
Contenidos
- Objetivos de la lección
- Abrir URLS con Python
- Guardar una copia local de una página web
- Lecturas sugeridas
Objetivos de la lección
Esta lección muestra qué es un Localizador de recursos uniforme (Uniform Resource Locator = URL) y explica cómo utilizar Python para descargar y guardar los contenidos de una página web en tu disco duro.
Acerca de los URL
Una página web es un archivo que está almacenado en otra computadora, una máquina conocida como servidor web. Cuando tú “vas” a una página web, lo que en realidad sucede es que tu computadora (el cliente) envía una solicitud al servidor (el alojamiento o host) a través de la red, y el servidor responde enviándote una copia de la página a tu máquina. Una manera de ir a una página web con tu navegador es seguir un enlace a alguna otra parte. También tienes la posibilidad de pegar o escribir un localizador de recursos uniforme (URL) directamente en tu navegador. El URL le indica a tu navegador dónde encontrar un recurso en línea especificando el servidor, directorio y nombre del archivo que tiene que ser recuperado, así como el tipo de protocolo que tu navegador y el servidor estarán de acuerdo en usar mientras intercambian información (como HTTP o protocolo de transferencia de hipertexto). La estructura básica de un URL es:
protocolo://dominio:puerto//ruta?consulta
Veamos algunos ejemplos.
http://oldbaileyonline.org
El tipo más básico de URL simplemente especifica el protocolo y el alojamiento. Si introduces este URL en tu navegador, te mostrará la página principal del sitio The Old Bailey Online. Por defecto, la página principal en un directorio se denomina índice, por lo general index.html.
El URL también pude incluir un número de puerto opcional. Sin entrar en detalles, el protocolo de red que subyace en el intercambio de información en la Internet permite a las computadoras conectarse de diferentes maneras. Los números de puerto se usan para distinguir estas diferentes formas de conexión. Dado que, por defecto, el puerto para HTTP es el número 80, el siguiente URL es equivalente al previo.
http://oldbaileyonline.org:80
Como sabes, generalmente hay muchas páginas en un determinado sitio web. Éstas están almacenadas en directorios del servidor y tú puedes especificar la ruta (path) a una página en particular. La página “Acerca de” del The Old Bailey Online tiene el siguiente URL:
http://oldbaileyonline.org/static/Project.jsp
Por último, muchas páginas web te permiten introducir consultas. El sitio web The Old Bailey Online, por ejemplo, está diseñado de tal manera que puedes solicitar una página en particular utilizando una cadena de consulta. EL siguiente URL te llevará a la página de resultados de búsqueda de registros de juicios criminales que contienen la palabra “arsenic” (arsénico)
https://www.oldbaileyonline.org/search.jsp?form=searchHomePage&_divs_fulltext=arsenic&kwparse=and&_persNames_surname=&_persNames_given=&_persNames_alias=&_offences_offenceCategory_offenceSubcategory=&_verdicts_verdictCategory_verdictSubcategory=&_punishments_punishmentCategory_punishmentSubcategory=&_divs_div0Type_div1Type=&fromMonth=&fromYear=&toMonth=&toYear=&ref=&submit.x=0&submit.y=0
El fragmento de texto después de “?” representa la consulta. Puedes aprender más acerca de la construcción de consultas en Descarga de registros múltiples usando cadenas de consulta (en inglés).
Abrir URLS con Python
Como historiador digital a menudo querás utilizar los datos alojados en una base de datos académica en línea. Para obtener estos datos puedes abrir una URL a la vez y copiar y pegar su contenido a un archivo de texto, o puedes utilizar Python para hacer una cosecha por procesamiento automático de las páginas web. Para hacer esto tienes que ser capaz de abrir cualquier URL con tus propios programas. El lenguaje Python incluye un número de formas estándar para hacer esto.
Como ejemplo, vamos a trabajar con una tipo de archivo que podrás encontrar haciendo investigación histórica. Digamos que te interesan las relaciones étnicas en la Gran Bretaña del siglo XVIII. The Old Bailey Online (OBO) es una rica fuente que proporciona transcripciones de juicios de 1674 a 1913 y es un buen lugar para buscar documentación.
Página principal del sitio The Old Bailey Online
Para este ejemplo vamos a utilizar la relatoría del juicio de Benjamin Bowsey, un “moro negro” que fue procesado por romper la paz durante las revueltas de Gordon en 1780. El URL para esa entrada es:
http://www.oldbaileyonline.org/browse.jsp?id=t17800628-33&div=t17800628-33
Si estudiamos el URL podemos aprender varias cosas. En primer lugar, OBO fue escrito en JSP (+JavaServer Pages, un lenguaje de programación que genera HTML), y es posible obtener entradas de procesos judiciales individuales haciendo uso de cadenas de consulta. A cada proceso se le asignó, aparentemente un número de identificación (ID) (id=t* en el URL), compuesto a partir de la fecha del juicio en formato (AAAA-MM-DD) y el número de proceso dentro de esa sesión de la corte, en este caso: 33. Si cambias 33 por 34 en tu navegador y presionas Enter, eso te deberá llevar al siguiente proceso. Desafortunadamente no todos los sitios web tienen estos URL tan legibles y fiables.
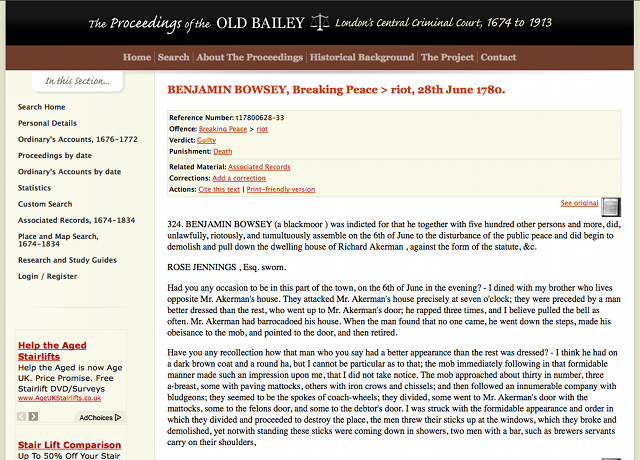
Página de la transcripción del juicio de Benjamin Bowsey, 1780
Tómate unos minutos para ver la página del proceso contra Benjamin Bowsey. No estamos muy interesados en lo que dice la relatoría sino en la información que proporciona la página. Al final de la misma notarás que hay un enlace View as XML que te lleva a una versión de la página del texto profusamente etiquetado con XML que es muy útil para cierto tipo de investigaciones. También puedes ver un escaneo del documento original que fue transcrito para hacer construir esta fuente.
Ahora vamos a tratar de abrir la página usando Python. Copia el siguiente programa en Komodo Edit y guárdalo como abre-paginaweb.py Cuando ejecutes el programa abrirá la página del proceso judicial, leerá (read) su contenido en una cadena de texto de Python llamada contenidoWeb y luego te mostrará mediante print los primeros trescientos caracteres de la cadena en el panel de salida de comando. Usa el comando de Firefox Herramientas -> Desarrollador web -> Código fuente de esta página (Ctrl-U) para verificar que la fuente de la página de ese URL es la misma fuente que tu programa recupera. Consulta la biblioteca de referencias de Python para saber más de urllib.
# abre-paginaweb.py
import urllib.request, urllib.error, urllib.parse
url = 'http://www.oldbaileyonline.org/browse.jsp?id=t17800628-33&div=t17800628-33'
respuesta = urllib.request.urlopen(url)
contenidoWeb = respuesta.read().decode('UTF-8')
print(contenidoWeb[0:300])
Estas cinco líneas de código logran mucho rápidamente. Vamos a detenernos un momento para asegurarnos de que todo está claro y que puedes reconocer los bloques que permiten que este programa haga lo que queremos que haga.
url, respuesta y contenidoWeb son variables que nosotros mismos hemos llamado así.
url contiene el URL de la página web que queremos descargar. En este caso, el juicio contra Benjamien Bowsey.
En la línea siguiente invocamos a la función urlopen que está almacenada en un módulo de Python llamado urllib.py y le hemos pedido a esa función que abra el sitio web en el URL que le especificamos. Entonces, guardamos el resultado de ese proceso en una variable denominada respuesta. Esta variable contiene una versión abierta del sitio web solicitado.
Utilizamos entonces el método read, que ya usamos anteriormente, para copiar el contenido de esa página web abierta en una nueva variable llamada contenidoWeb.
Asegúrate de que puedes reconocer las variables (hay 3), los módulos (1), los métodos (2) y los parámetros (1) antes de seguir adelante.
Al ejecutar el programa, te darás cuenta que en el panel de salida se muestra algo etiquetado en HTML:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>Browse - Central Criminal Court</title>
<meta http-equiv="content-type" content=
El contenido del proceso judicial está mucho más adelante en la página. Lo que vemos aquí es solamente en código HTML de la parte superior del documento. Esto no es lo que necesitamos para una investigación histórica, pero no te preocupes: en breve aprenderás cómo quitar el exceso de etiquetas y obtener el contenido que estás buscando.
Guardar una copia local de una página web
Dado que ya sabes lo suficiente acerca de escribir en archivos, resulta bastante sencillo modificar el programa anterior para que escriba el contenido de la cadena de texto contenidoWeb en un archivo local de nuestra computadora en vez de en el panel de salida. Copia el siguiente programa en Komodo Edit, guárdalo como guardar-paginaweb.py y ejecútalo. Abre en tu navegador el archivo creado en tu disco duro (obo-t17800628-33.html) para confirmar que la copia que guardaste es igual a la que está en línea.
# guardar-paginaweb.py
import urllib.request, urllib.error, urllib.parse
url = 'http://www.oldbaileyonline.org/browse.jsp?id=t17800628-33&div=t17800628-33'
respuesta = urllib.request.urlopen(url)
contenidoWeb = respuesta.read().decode('UTF-8')
f = open('obo-t17800628-33.html', 'w')
f.write(contenidoWeb)
f.close
Ahora, si tu puedes guardar un solo archivo así de fácil, ¿es posible escribir un programa que te permita descargar un puñado de archivos? ¿Es posible incrementar la cantidad de IDs de los juicios y obtener copias de todos ellos en una sola descarga? Efectivamente. Puedes aprender cómo hacerlo en la lección Downloading Multiple Files using Query Strings, que te recomendamos ver una vez completadas las lecciones introductorias de esta serie.
Lecturas sugeridas
- Lutz, Mark. “Ch. 4: Introducing Python Object Types”, Learning Python (O’Reilly, 1999).
Sicronización de código
Para seguir a lo largo de las lecciones futuras es importante que tengas los archivos correctos y programas en el directorio “programming-historian” de tu disco duro. Al final de cada lección puedes descargar el archivo zip “python-es-lecciones” para asegurarte que tienes el código correcto.
- python-es-lecciones1.zip (zip)