
Contenus
- Objectifs de la leçon
- Ouvrir des URL en Python
- Sauvegarder une copie locale d’une page web
- Lectures recommandées
Objectifs de la leçon
Cette leçon présente les URL (un acronyme tiré de l’anglais Uniform Resource Locator, soit localisateur uniforme de ressource) et explique comment utiliser Python pour télécharger et sauvegarder le contenu d’une page Web sur votre poste de travail.
À propos des URL
Une page web est un fichier entreposé sur un autre ordinateur, communément appelé un serveur web. Lorsque vous visitez une page web, votre ordinateur (le client) envoie une requête au serveur (l’hôte) par l’intermédiaire du réseau, et le serveur répond en transmettant une copie de la page demandée à votre poste de travail. Pour accéder à une page web à partir de votre navigateur, vous pouvez suivre un lien à partir d’un autre site. Vous pouvez aussi, bien entendu, copier-coller ou entrer un URL directement dans le champ de recherche du navigateur. L’URL indique au navigateur comment trouver la ressource que vous désirez, en spécifiant le serveur, le répertoire et le nom du fichier appropriés, ainsi que le protocole de communication que le serveur et votre navigateur s’engageront à suivre pendant la transaction (par exemple: HTTP, le protocole de transfert hypertexte ou Hypertext Transfer Protocol.) Un URL est constitué des composantes suivantes :
protocole://hôte:port/chemin?requête
Voyons quelques exemples.
http://oldbaileyonline.org
Le type d’URL le plus élémentaire se contente de spécifier le protocole et l’hôte. Si vous fournissez cet URL à votre navigateur, vous obtiendrez la page d’accueil du site Old Bailey Online. Par défaut, on assume que la page principale dans un répertoire donné est nommée ‘index’, le plus souvent index.html.
L’URL peut aussi inclure un numéro de port (optionnel). Sans entrer dans les détails, le protocole de communication qui gouverne les échanges d’information sur Internet permet aux ordinateurs de connecter de multiples façons. Les numéros de ports servent à identifier ces différentes manières de se connecter. Puisque le port par défaut pour les connexions HTTP est le 80, l’URL suivant est équivalent au précédent :
http://oldbaileyonline.org:80
Comme vous le savez, on retrouve habituellement plusieurs pages web sur un même site. Ces pages sont stockées dans des répertoires sur le serveur et il est possible de spécifier le chemin à parcourir pour accéder à la page qui nous intéresse. La page d’information générale du site The Old Bailey Online, par exemple, se retrouve à l’URL suivant :
http://oldbaileyonline.org/static/Project.jsp
Enfin, certaines pages web vous permettent d’envoyer des requêtes au serveur. The Old Bailey Online, par exemple, est conçu de sorte que l’on puisse demander au serveur d’effectuer des recherches dans sa base de données à l’aide d’une chaîne d’interrogation. L’URL suivant vous donnera accès à une liste des procès criminels dont les archives contiennent le mot “arsenic”.
https://www.oldbaileyonline.org/search.jsp?form=searchHomePage&_divs_fulltext=arsenic&kwparse=and&_persNames_surname=&_persNames_given=&_persNames_alias=&_offences_offenceCategory_offenceSubcategory=&_verdicts_verdictCategory_verdictSubcategory=&_punishments_punishmentCategory_punishmentSubcategory=&_divs_div0Type_div1Type=&fromMonth=&fromYear=&toMonth=&toYear=&ref=&submit.x=0&submit.y=0
Le code qui suit le “?” englobe les paramètres de recherche. Pour en savoir plus sur la manière de construire des requêtes, consultez la leçon Downloading Multiple Records Using Query Strings (en anglais).
Ouvrir des URL en Python
En tant qu’historiens et historiennes numériques, nous avons souvent besoin d’accéder aux informations enregistrées dans des bases de données en ligne. Nous pourrions ouvrir les URL appropriés un par un et copier leur contenu dans des fichiers textes. Mais il est aussi possible d’utiliser Python pour récolter et traiter automatiquement le contenu d’un ensemble de pages web. Pour ce faire, il faut d’abord savoir comment ouvrir des URL à l’intérieur de nos programmes. Le langage Python propose un ensemble de fonctionnalités qui permettent de réaliser cela.
Voici un exemple qui exploite le genre de fichier que vous risquez de rencontrer pendant vos propres recherches historiques. Supposons que vous vous intéressez aux relations interethniques en Grande-Bretagne au XVIIIe siècle. The Old Bailey Online contient des transcriptions de procès tenus entre 1674 et 1913 ; il s’agit donc d’une source potentiellement utile pour votre projet.
Page d’accueil du site Old Bailey Online
Pour les besoins de cet exemple, nous allons obtenir la transcription du procès de Benjamin Bowsey, un homme noir (‘black moor’ dans le texte) reconnu coupable d’avoir troublé la paix pendant les Gordon Riots de 1780. L’URL de cette transcription est :
http://www.oldbaileyonline.org/browse.jsp?id=t17800628-33&div=t17800628-33
En étudiant la structure de l’URL, il est possible d’apprendre plusieurs choses. Par exemple, le Old Bailey Online a été programmé en langage JSP (JavaServer Pages), un langage qui sert à produire du code HTML. On apprend aussi qu’il est possible d’accéder à un procès spécifique à l’aide de la chaîne de requête. Il semble aussi que chaque procès possède son propre code d’identification (id=t dans l’URL) composé de la date de l’audience en format AAAAMMJJ et d’un numéro de série à l’intérieur de cette audience, 33 dans le cas qui nous concerne. Si vous remplacez les deux copies du nombre 33 par 34 dans votre navigateur, vous devriez obtenir la transcription du procès suivant. Mais malheureusement, tous les sites web ne structurent pas leurs URL de façon aussi lisible, ni de façon aussi régulière.
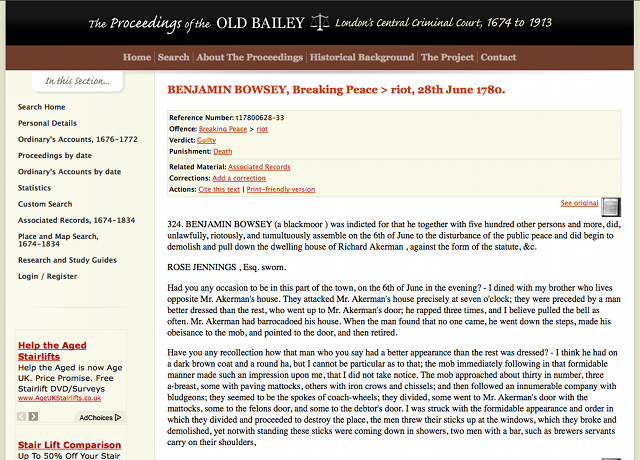
Page de la transcription du procès de Benjamin Bowsey, 1780
Examinez la page du procès de Benjamin Bowsey pendant quelques minutes. Concentrez-vous sur les caractéristiques de la page plutôt que sur la transcription elle-même. Par exemple, notez la présence du lien View as XML au bas de la page, qui vous amènera vers une version abondamment balisée du texte qui pourrait être utile pour certains types de recherche. Vous pouvez aussi consulter une image numérisée du document d’origine qui a été transcrit pour construire cette ressource.
Essayons maintenant d’ouvrir cette page en Python. Copiez le programme suivant dans votre éditeur de texte et sauvegardez-le sous le titre open-webpage.py. Lorsque vous exécuterez le programme, il ouvrira (open) la page du procès, il lira (read) son contenu dans une chaîne de caractères Python nommée contenu_web, puis il affichera les 300 premiers caractères du fichier à l’écran. Utilisez la commande Outils -> Développement web -> Code source de la page de Firefox (ou son équivalent dans votre propre navigateur) pour vérifier que le code source HTML de la page est bien identique à ce que vous venez de télécharger. Notez aussi que chaque navigateur possède son propre raccourci clavier qui permet d’accéder au code source HTML d’une page ; dans le cas de la version Windows de Firefox, il s’agit de CTRL+u. Si vous ne parvenez pas à trouver l’équivalent pour votre propre navigateur, essayez de faire appel à votre moteur de recherche favori pour y arriver. (Consultez la documentation de Python pour en savoir plus au sujet de urllib.)
# open-webpage.py
# NOTE : l'archive zip que vous pouvez télécharger contient une version
# anglophone de ce code, fonctionnellement identique
import urllib.request, urllib.error, urllib.parse
url = 'http://www.oldbaileyonline.org/browse.jsp?id=t17800628-33&div=t17800628-33'
reponse = urllib.request.urlopen(url)
contenu_web = reponse.read().decode('UTF-8')
print(contenu_web[0:300])
Ces quelques lignes de code accomplissent un travail considérable en un rien de temps. Prenons un moment pour nous assurer que tout est bien clair et que nous maîtrisons bien le rôle de chacun des blocs qui permettent à ce programme de bien remplir sa mission.
Nous avons nous-même instancié les variables url, reponse et contenu_web.
url contient l’URL de la page que nous voulons télécharger. Dans le cas qui nous concerne, il s’agit de la transcription du procès de Benjamin Bowsey.
À la ligne suivante, nous invoquons la fonction urlopen, qui fait partie d’un module Python nommé urllib.py. Cette fonction sert à établir une connexion vers le site web dont l’URL a été passé en paramètre. Nous enregistrons ensuite le résultat de la requête dans la variable reponse, qui contient maintenant une liaison vers le site web en question.
Nous utilisons ensuite la méthode read pour copier le contenu de cette page web dans une nouvelle variable nommée contenu_web.
Assurez-vous de bien identifier les variables (il y en a trois), le module, les méthodes (il y en a deux) et le paramètre avant de continuer.
Dans le texte affiché en sortie, vous remarquerez la présence de certains éléments de code HTML :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>Browse - Central Criminal Court</title>
<meta http-equiv="content-type" content=
La transcription du procès elle-même apparaît beaucoup plus bas dans la page. Ce que vous voyez ici fait partie de l’en-tête du document. Ce n’est pas exactement ce dont nous avons besoin pour mener de la recherche historique, mais ne vous découragez pas : vous apprendrez bientôt comment mettre de côté ces marques de balisage et extraire le contenu dont vous avez besoin.
Sauvegarder une copie locale d’une page web
Si vous savez déjà comment écrire des fichiers textes en Python, il est assez facile de modifier le programme ci-dessus pour qu’il sauvegarde les données enregistrées dans contenu_web dans un fichier sur votre poste de travail plutôt que de l’afficher à l’écran. Copiez le programme ci-dessous dans votre éditeur de texte, sauvegardez-le dans un fichier nommé save-webpage.py et exécutez celui-ci. Utilisez ensuite la commande Fichier -> Ouvrir un fichier de Firefox, ou son équivalent dans votre propre navigateur, pour ouvrir le fichier que le programme save-webpage.py vient de créer sur votre poste de travail (obo-t17800628-33.html) et vérifiez que le résultat correspond bien à la page du procès Bowsey que vous avez consultée en ligne un peu plus tôt.
# save-webpage.py
# NOTE DU TRADUCTEUR : l'archive zip que vous pouvez télécharger contient une version anglophone de ce code, fonctionnellement identique
import urllib.request, urllib.error, urllib.parse
url = 'http://www.oldbaileyonline.org/browse.jsp?id=t17800628-33&div=t17800628-33'
reponse = urllib.request.urlopen(url)
contenu_web = reponse.read().decode('UTF-8')
f = open('obo-t17800628-33.html', 'w')
f.write(contenu_web)
f.close
Maintenant que vous savez comment sauvegarder une page web dans un fichier, pourriez-vous écrire un programme capable de télécharger toute une collection de pages? Pourriez-vous parcourir une liste de codes d’identification de procès, par exemple, et sauvegarder des copies locales de chacune des pages correspondantes? Oui. Vous apprendrez notamment à faire cela dans la leçon Downloading Multiple Records Using Query Strings, que nous vous recommandons d’étudier lorsque vous aurez maîtrisé la présente série de leçons d’introduction.
Lectures recommandées
- Lutz, Mark. “Ch. 4 : Introducing Python Object Types”, Learning Python (O’Reilly, 1999).
Synchronisation du code
Pour bien suivre la progression de la présente série de leçons, il est important que vous disposiez des bons fichiers et des bons programmes dans votre répertoire “programming-historian”. À la fin de chacune des leçons, vous pourrez télécharger une archive zip “programming-historian” à jour pour vous assurer d’avoir accès au code source nécessaire.
- programming-historian-1 (zip)