
Contenidos
- Resumen
- Objetivos
- Introducción
- Requisitos
- Los datos explorados
- Tratamiento y limpieza de los datos con R
- Explorando los datos
- Visualizando tablas con ggplot2
- Animando la visualización de los datos con gganimate
- Conclusión
- Notas
Resumen
Esta lección te mostrará cómo cruzar, graficar y animar un conjunto de datos históricos. Aprenderás a importar en RStudio una tabla disponible en una hoja de cálculo y a utilizar funciones que te permitan transformar esos datos para representarlos como una tabla de contingencia. También sabrás cómo utilizar funciones de nuevas librerías que te permitirán visualizar tus datos cruzados en forma gráfica e inclusive llegar a animarlos en perspectiva temporal.
Objetivos
En esta lección aprenderás a:
- Ordenar y transformar tablas históricas para realizar análisis exploratorios
- Generar gráficos estáticos y animados para visualizar datos históricos
Introducción
Es indudable que en una disciplina como la historia predomina el tratamiento cualitativo de los documentos y fuentes que el pasado nos ha legado. Pero, como ha señalado Roderick Floud, “aunque estemos básicamente más interesados en las cuestiones ‘cualitativas’ que en las ‘cuantitativas’, ambas están inextricablemente unidas”1. Es decir, no compiten, no se reemplazan, sino que se complementan. Una forma de combinar ambas metodologías, es a través de la búsqueda de regularidades o patrones ocultos o, a la inversa, de anomalías. Esto permite acercar a quienes hacen investigación histórica a un mejor conocimiento de las coordenadas en las que situar sus interpretaciones. Si esa comprensión global de los datos puede visualizarse gráficamente, posibilita “que el investigador descubra fácilmente relaciones, similitudes y diferencias entre sus casos”. Desde que escribió Floud -a mediados de los años setenta- la tecnología informática y la programación han avanzado de tal manera que hacen muy fácil el cruce entre perspectivas metodológicas. De esta manera, si un trabajo histórico cualitativo apunta a profundizar aspectos de fenómenos que sucedieron en el pasado, uno cuantitativo te permitirá saber con qué frecuencia sucedieron, observar patrones y anomalías, y a establecer relaciones temporales entre las diferentes categorías de análisis existentes.
Quien se propone hacer un análisis histórico cuantitativo debe partir de un ejercicio de codificación de las fuentes documentales que el pasado nos ha legado y plasmarlas en una matriz de datos. Es decir, esto demanda un proceso de conversión de nuestras fuentes de información, para transformar los datos textuales (palabras) en datos simbólicos operables digitalmente (números). Lo anterior consta de varios pasos: 1) clasificar los documentos a los que se ha accedido de forma que permitan su puesta en común según criterios determinados, 2) categorizar descriptiva, interpretativa o analíticamente, con ideas, categorías o conceptos el contenido de las fuentes, 3) codificar, poniendo a las distintas expresiones particulares de cada caso un símbolo (números, palabras), 4) tabular, es decir, representar los casos organizados en forma de una matriz en un soporte informático, habitualmente una hoja de cálculo.
En esta lección te mostraremos una de las tantas formas en que se pueden analizar cuantitativamente archivos que reúnen información sistemática y seriada (como son casos de productores de documentación permanente como el Estado, empresas o la prensa) utilizando el lenguaje de programación R. El objetivo es que adquieras conocimientos que te permitan efectuar un análisis exploratorio de datos, trabajando principalmente la distribución de frecuencias de distintas variables a través de tablas de contingencia, para luego visualizarlas, generar gráficos y, finalmente, crear una animación de los mismos en perspectiva temporal.
Requisitos
Esta lección requiere que cuentes con nociones básicas de R, que tratan las lecciones Datos tabulares en R de Trayn Dewar y Administración de datos en R de Nabeel Siddiqui.
Además de R, deberás tener instalado el entorno de desarrollo [RStudio] (https://www.rstudio.com/products/rstudio/download/#download). Si no lo tienes aún, en este video encontrarás una guía sobre cómo descargarlo e instalarlo.
Los datos explorados
El conjunto de datos que aquí se presenta servirá para que veas cómo R te puede ayudar a analizar dinámicas de la violencia política en Argentina a finales de la década de los años cincuenta, a partir de documentos policiales de espionaje. Habitualmente estos archivos de inteligencia se han utilizado para el estudio histórico de casos particulares, pero rara vez se ha apuntado a lograr grados de agregación que permitan hacer comparaciones entre distintos casos. Contar con algunos elementos básicos de programación facilita dar pasos en esa dirección.
La fuente que te proponemos codificar es un legajo muy especial del archivo de la ex Dirección de Inteligencia de la Policía de Buenos Aires (Argentina). Contiene varios informes de inteligencia que contabilizan “actos terroristas” durante los años del período de conflictividad política y social que se conoce en la historia argentina como “Resistencia peronista”2. En la Figura 1 se presenta una imagen escaneada de uno de los legajos. Lo interesante es que la información cruda se presenta de una manera que facilita su tabulación.

Figura 1. Imagen de un legajo con datos sobre atentados
Este documento fue transformado en un conjunto de datos procesables cuantitativamente. Se construyó una tabla a partir información sobre algunas localidades de la provincia de Buenos Aires en 1959, año en el que el número de “actos terroristas” o atentados fue muy alto. Los datos representan los valores de ciertas variables de análisis comunes a todos los registros, como son la ciudad (dónde) y la fecha del atentado (cuándo). Desde la información descriptiva de la policía (atributos del atentado), fue posible generar variables como: objeto utilizado en el atentado (con qué elemento se realizó), sitio (lugar/espacio) y objetivo (contra quién). Con esta categorización, buscamos ahorrar un paso, ya que la tabla sigue los preceptos de “datos ordenados” (tidy data): cada variable forma una columna, cada observación forma una fila, cada valor tiene su propia celda, cada tipo de unidad observacional forma una tabla3.
| fecha | ciudad | objeto | sitio | objetivo |
|---|---|---|---|---|
| 18/01/1959 | La Plata | bomba | sede | institucion extranjera |
| 19/01/1959 | La Plata | petardo | vias ffcc | ferrocarril |
| 19/01/1959 | Matanza | bomba | vias ffcc | ferrocarril |
| 20/01/1959 | Avellaneda | molotov | comercio | comercio |
| 20/01/1959 | Avellaneda | bomba | vias ffcc | ferrocarril |
| 20/01/1959 | Lomas | bomba | vias ffcc | ferrocarril |
| 20/01/1959 | Matanza | bomba | vias ffcc | ferrocarril |
Para esta lección utilizaremos la tabla correspondiente a los atentados en cinco ciudades de Argentina durante 1959, la que se encuentra disponible en el archivo atentados1959.xlsx
Tratamiento y limpieza de los datos con R
En esta sección te mostraremos cómo cargar los datos en RStudio para comenzar a procesarlos. No esperes que esté todo listo para trabajar una vez importada la hoja de cálculo; siempre será necesaria una adecuación de tus datos para que R pueda interpretarlos. En lo que atañe a este caso, por ejemplo, luego de importarlos deberás asignarle un tipo a las variables, convertirlas, hacer algunas modificaciones en los datos y luego ordenarlos temporalmente.
El primer paso será importarlos desde su formato de hoja de cálculo al entorno de RStudio. Para poder hacerlo, primero deberás instalar el paquete que te dará los recursos necesarios: readxl4. Este paquete es parte de la colección de paquetes conocida como Tidyverse5, una de las más utilizados para el tipo de análisis que te proponemos, ya que permite realizar fácilmente tareas tales como leer, transformar, tratar, manipular, organizar y visualizar distinto tipo de datos. Además de readxl, contiene varios de los paquetes que necesitarás más adelante.
install.packages("tidyverse")
A continuación, debes cargar tanto el paquete readxl como el paquete tidyverse. Si bien el paquete readxl está contenido dentro de este último, es necesario cargarlo de forma independiente.
library(readxl)
library(tidyverse)
Ahora estás en condiciones de importar el dataset, usando la función read_excel(). Esta función toma como argumento el nombre del archivo donde almacenaste la hoja de cálculo, suponiendo que está en tu directorio actual de trabajo. Si no estuviese en tu directorio de trabajo, deberás indicar toda la ruta del archivo.
El contenido del archivo lo asignaremos a un nuevo objeto que llamaremos at59:
at59 <- read_excel("atentados1959.xlsx")
Es fundamental entender en qué forma fue almacenada la información. En R todo es un objeto y, dependiendo de las características de los datos importados, corresponderá a una determinada estructura de datos. R maneja varias estructuras que se diferencian por tener distinta cantidad de dimensiones y por si pueden guardar o no datos de diverso tipo. La más conocida es el vector, que es una colección de una dimensión de datos de igual tipo. Otra estructura es la matriz, que es similar al vector, pero permite trabajar en dos dimensiones.
Además, R cuenta con una forma particular de estructura de datos, la cual tiene dos dimensiones y nos da la posibilidad de contener datos de distinto tipo (enteros junto a fechas, caracteres, etcétera). Esta estructura es denominada data frame, y se compone por filas y columnas; cada fila corresponde a una observación o registro, mientras que cada columna es un vector que representa una variable de análisis. El data frame es una de las estructuras más utilizadas en R y los datos que importamos de hojas de cálculo se almacenarán de esta manera. Es importante tener en cuenta que muchas de las funciones del Tidyverse (como read_excel()) devuelven un tipo particular de data frame llamado tibble. La principal diferencia entre ambos tipos es la forma en que los datos se muestran en la consola. Los tibble, por ejemplo, muestran debajo del nombre de cada variable a qué tipo corresponde. Esto lo podrás apreciar al usar la función head(), que muestra los primeros seis registros de at59. Ahí se puede observar que la fecha está en formato datetime (fecha y hora) y el resto de las columnas son de tipo character (caracter).
> head(at59)
# A tibble: 6 x 5
fecha ciudad objeto sitio objetivo
<dttm> <chr> <chr> <chr> <chr>
1 1959-06-23 00:00:00 Almirante Brown bomba via publica ns
2 1959-06-30 00:00:00 Almirante Brown bomba domicilio ns
3 1959-07-30 00:00:00 Almirante Brown bomba domicilio ns
4 1959-08-02 00:00:00 Almirante Brown bomba domicilio ns
5 1959-09-15 00:00:00 Almirante Brown bomba taller industria
6 1959-01-20 00:00:00 Avellaneda molotov comercio comercio
Con la tabla ya cargada en RStudio puedes empezar el tratamimiento de los datos para poder trabajar con ellos. Así, por ejemplo, podemos partir reemplazando determinados valores de la estructura de datos para corregir o cambiar contenidos masivamente. Para tal efecto, utilizaremos la función ifelse(), la que te permite seleccionar elementos de una estructura de datos según se cumpla o no alguna condición. Esta función aprovecha la vectorialización del lenguaje R y permite que, al aplicar una función a un objeto, esta lo haga sobre todos sus elementos. Así, se evita la necesidad de utilizar bucles (for o while, por ejemplo) para recorrer las filas. Lo recomendable es que hagas estas operaciones sobre los datos antes de realizar alguna conversión sobre su tipo.
Supón que deseas reemplazar todos los casos donde el objeto figura como ‘bomba’, por el término ‘explosivo’. Para tal efecto puedes utilizar la función ifelse() pasándole solo tres argumentos. Primero se indica la condición a cumplir, en este caso, los valores ‘bomba’ de la columna objeto de at59, que es seleccionada con el símbolo $. El segundo argumento corresponde a lo que la función asignará en el caso de que la condición se cumpla: lo reemplazará por ‘explosivo’. El tercer argumento es el valor asignado en el caso negativo. En este caso mantendrás el valor original:
at59$objeto <- ifelse(at59$objeto == "bomba", "explosivo", at59$objeto)
Si te llegases a arrepentir de los cambios, puedes hacer la misma operación pero a la inversa:
at59$objeto <- ifelse(at59$objeto == "explosivo", "bomba", at59$objeto)
A continuación, sería conveniente transformar los tipos de variables. En este caso, los cambios te permitirán aprovechar mejor las funciones de visualización. Primero, como no interesa que las fechas tengan además la hora, puedes adecuar esa variable utilizando la función as.Date() sobre la columna fecha. Segundo, puedes transformar el resto de las variables de análisis a factores, que es el tipo de dato que brinda R para trabajar con variables categóricas, es decir, aquellas que representan un conjunto fijo y conocido de valores posibles. A continuación deberías hacer algo idéntico con cada una las cuatro columnas restantes (ciudad, objeto, sitio y objetivo) y aplicarles la función factor(). En principio, esto implicaría escribir cinco sentencias (una por cada variable): variable <- factor(variable). Si te interesa practicar escritura de código prolijo, uno de sus preceptos apunta a evitar la repetición de sentencias si no son necesarias y aprovechar el potencial que brinda el lenguaje que estemos utilizando para resolverlo. En el caso de R puedes hacerlo utilizando funciones que permiten aplicar de manera generalizada otras funciones a una estructura de datos.
Entre diversas opciones, te invitamos a usar a map_df() del paquete purrr6, que es también parte del Tidyverse. map_df() te permite asignar una función -que en este caso será para cambiar el tipo de datos- a diversos elementos de un data frame y almacenar el resultado en un objeto de esta misma clase. Como argumentos de la función, se indica en primer término el nombre de las columnas -en un formato vectorizado con c()- y luego la función que quieres aplicar a dichas columnas.
Para unir el código de ambas transformaciones en una solo una sentencia, puedes utlizar la función tibble(). Esto te dará como resultado un tibble con las columnas convertidas y organizadas tal como estaban originalmente:
at59 <- tibble(map_df(at59[,c("fecha")], as.Date), map_df(at59[,c("ciudad", "objeto", "sitio","objetivo")], factor))
Para finalizar esta etapa de limpieza y transformación de los datos, es necesario ordenarlos cronológicamente. Para ello dispones de la función arrange(), del paquete dplyr7, tambien parte del Tidyverse, que te permitirá reordenar las filas del data frame. Por defecto lo hace de forma ascendente, aunque, al igual que la mayoría de las funciones en R, es parametrizable y nos permite variaciones. En este caso, el orden ascendente es pertinente, así que no podrás utilizar la función directamente. El primer argumento es tu objeto de datos y el segundo la variable que se utilizará como criterio ordenador. Si lo haces por fecha deberás ingresar:
at59 <- arrange(at59, fecha)
Con head() podrás apreciar cómo quedó reorganizado y listo tu conjunto de datos para que comiences, ahora, sí a analizarlo.
# A tibble: 6 x 5
fecha ciudad objeto sitio objetivo
<date> <fct> <fct> <fct> <fct>
1 1959-01-18 La Plata bomba sede institucion extranjera
2 1959-01-19 La Plata petardo vias ffcc ferrocarril
3 1959-01-19 Matanza bomba vias ffcc ferrocarril
4 1959-01-20 Avellaneda molotov comercio comercio
5 1959-01-20 Avellaneda bomba vias ffcc ferrocarril
6 1959-01-20 Lomas bomba vias ffcc ferrocarril
Explorando los datos
A continuación realizaremos un análisis exploratorio básico de nuestros datos históricos, con el fin de encontrar relaciones entre los casos de atentados incluidos en el dataset. La idea de este tipo de metodología es identificar las principales características de un conjunto de datos (patrones, diferencias, tendencias, anomalías, discontinuidades y distribuciones) con el objetivo de conocer su variabilidad. Al representar dicha variabilidad de manera numérica, y sobre todo en forma de gráficos y visualizaciones, el análisis exploratorio de datos se transforma en un medio para desarrollar nuevas perspectivas analíticas, preguntas o hipótesis: con una breve mirada podemos estar al tanto de concentraciones de datos, valores atípicos, saltos, etcétera.
Con nuestra base de datos vamos a trabajar con una de las formas primarias en que se manifiesta la variabilidad en la información: la distribución de frecuencias. Lo haremos en modo bivariado, es decir, veremos cómo se pueden construir tablas de contingencia que contabilicen los casos resultantes del cruce de dos variables dentro del conjunto de los atentados efectuados durante 1959.
Para tal efecto, cuentas con una sencilla función denominada table(), que toma variables tipo factor como parámetros y regresa la frecuencia de aparición de las categorías de la variable. Un aspecto interesante de esta función es que también te permite pasarle una sola columna como argumento. Por ejemplo, si quieres saber cuántos atentados hay por ciudad puedes conocer la cifra con la sentencia:
table(at59$ciudad)
Almirante Brown Avellaneda La Plata Lomas Matanza
5 54 52 9 14
Si quieres empezar a probar las capacidades gráficas que te da R base, puedes transformar esa tabla de una dimensión en un gráfico de barras, con una función llamada barplot():
barplot(table(at59$ciudad))
El gráfico resultante (Figura 2) aparecerá en la pestaña Plots de la ventana de utilidades.
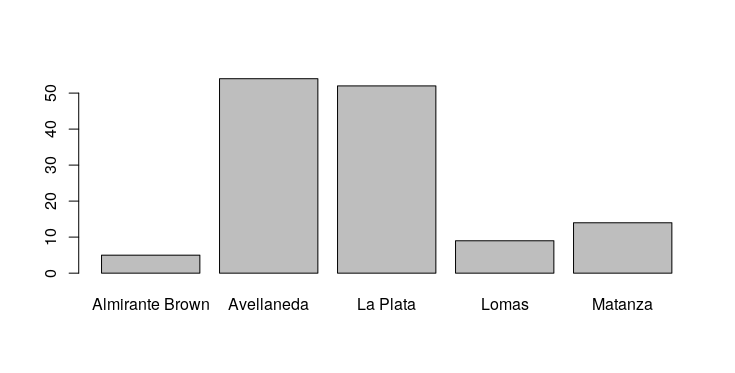
Figura 2. Gráfico de barras que muestra la frecuencia de atentados por ciudad. En este caso, Avellaneda y La Plata concentran la mayor cantidad de atentados.
Para analizar posibles relaciones entre variables y categorías, puedes confeccionar una tabla de contingencia. Para ello, a la función table() debes aplicas como argumento las dos columnas que te interesa cruzar. Por ejemplo, si quieres saber con qué tipo de elementos u objetos se efectuaron los atentados, según la ciudad de ocurrencia del hecho, deberías ingresar a la consola:
table(at59$ciudad, at59$objeto)
Obtendrás como resultado la siguiente tabla:
alquitran bomba armas de fuego bomba liquido inflamable molotov petardo proyectil
Almirante Brown 0 0 5 0 0 0 0
Avellaneda 1 0 40 1 5 7 0
La Plata 2 1 37 0 4 7 1
Lomas 0 1 5 2 1 0 0
Matanza 0 0 12 0 2 0 0
Existen muchas formas de hacer más amigable la visualización de tablas de contingencia utilizando paquetes disponibles en CRAN. Una que, sin ser complicada, te dará unos cuadros mejorados estéticamente es kableExtra8. El procedimiento tiene dos partes. Primero, debes darle formato html a la tabla con la función kable() y almacenarla en una variable (por ejemplo at59k). Luego, debes usar ese objeto como argumento de la función kable_styling(), lo que te permitirá visualizar la tabla y manejar varios atributos de estilo, tales como el tamaño y color de la fuente tipográfica. Dicho esto, prueba instalar, cargar y probar ese paquete, y aprovechar de agregar un título a tu tabla con el argumento caption:
install.packages("kableExtra")
library(kableExtra)
at59k <- kable(table(at59$ciudad, at59$objeto), caption = "Objeto vinculado al atentado por ciudad")
kable_styling(at59k, font_size = 10)
El resultado aparecerá en Viewer y tendrás la posibilidad de guardarlo como imagen o como código html, por medio de la pestaña Export.
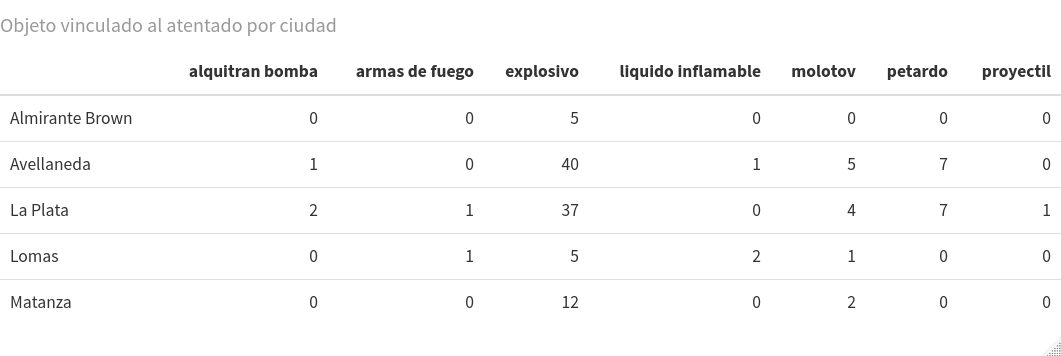
Figura 3. La misma tabla de contingencia creada anteriormente, pero con el formato dado por el paquete kableExtra.
Visualizando tablas con ggplot2
Como te hemos mostrado con las tablas generadas en esta lección, R se destaca por su capacidad para ilustrar conjuntos de datos. El paquete ggplot29 es uno de los más usados para hacer gráficas por quienes utilizan este lenguaje de programación. Tiene una lógica inspirada en la denominada gramática de los gráficos (grammar of graphics)10, la que consiste en el uso de capas o layers, que se ajustan según determinados parámetros. Un gráfico es la combinación de las capas, donde cada una cumple una función determinada sobre los datos, sus aspectos estéticos (tamaño, forma, color, etc.), los objetos geométricos que van a representar los datos (puntos, líneas, polígonos, áreas, etc.). Estas tres capas (datos, parámetros estéticos y representación geométrica) son esenciales, es decir, no pueden faltar. Opcionalmente, es posible modificar los valores por defecto de otras capas, que te permitirán facetar los datos en subgrupos, modificar el tipo de coordenadas, usar funciones estadísticas y modificar la apariencia general del gráfico. El paquete ggplot2 está incluido en el Tidyverse y se carga cuando ejecutas library(tidyverse), por lo tanto, no necesitas realizar ninguna instalación adicional.
En términos abstractos, una sentencia básica de esta gramática de gráficos tiene la siguiente estructura: ggplot(datos, variables) + función geométrica. Los datos corresponden al objeto de datos que contiene las variables que queremos visualizar y que para ggplot2 debe estar en formato data frame. Las variables se interpretan aquí como los parámetros estéticos (aes) en que serán representadas las columnas elegidas (por ejemplo, posición en los ejes x e y, tamaño, color). La función geométrica (geom) nos permite elegir el objeto visual con el que se representarán los datos. Como es una lógica de capas, el signo + permite ir agregando todas las que consideres necesarias para que tu gráfico incluya los elementos que consideres relevante.
Si deseas ver gráficamente la tabla de contingencia que construiste anteriormente, puedes empezar haciendo la equivalencia de un atentado = un punto en el plano, a lo que correspondería la sentencia mínima:
ggplot(at59, aes(x = ciudad, y = objeto)) +
geom_point()
Con el código anterior obtendrás un resultado similar al de la Figura 4.
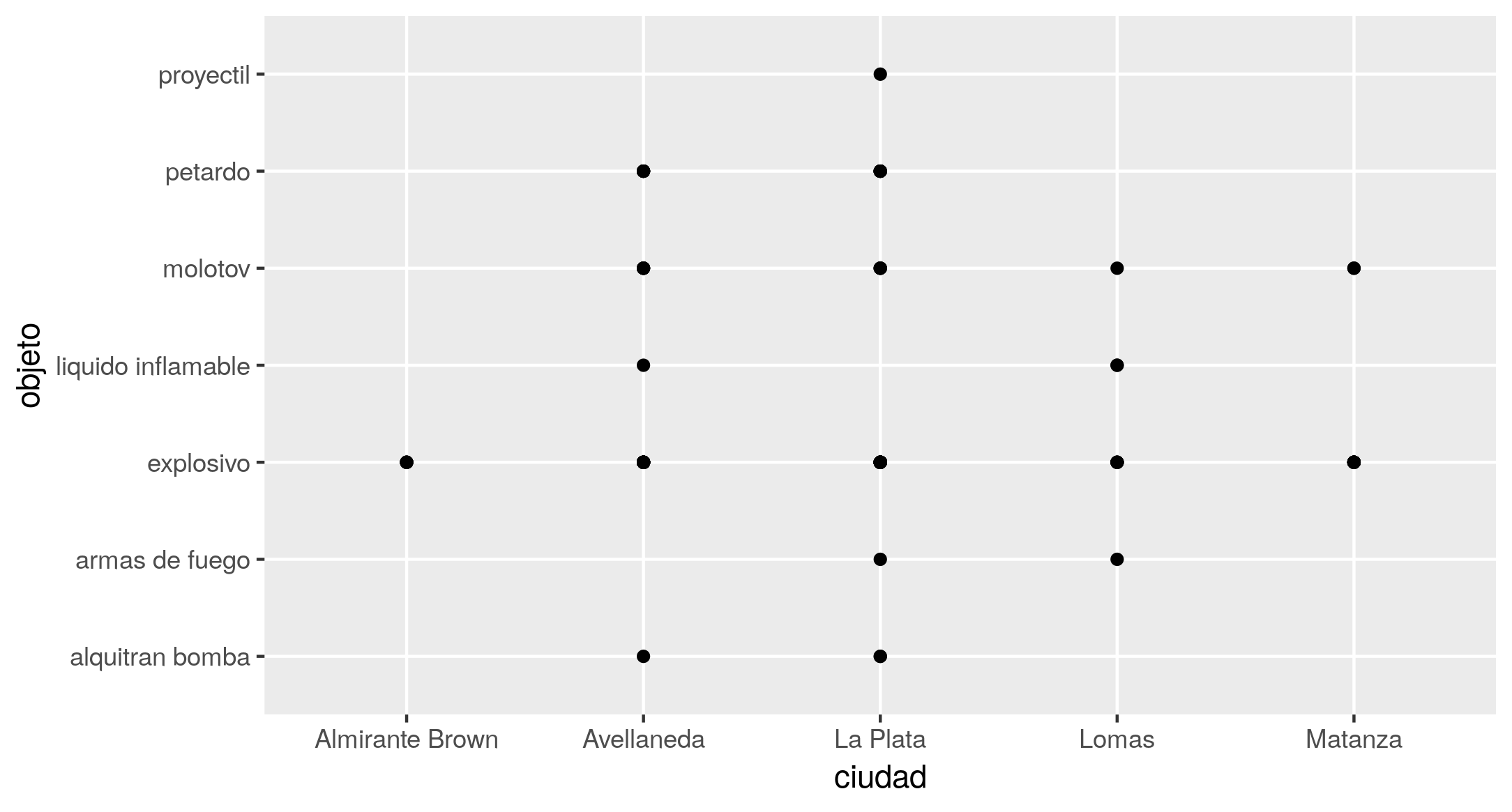
Figura 4. Gráfico de puntos que muestra el cruce de las variables objeto y ciudad.
Sin embargo, debe reconocerse que la acumulación de puntos, uno sobre otro, en una misma coordenada (fenómeno conocido como overplotting), da como resultado una visualización muy poco aprovechable, ya que, a diferencia de la tabla, no logra representar las frecuencias. Solo muestra la existencia de cruces de variables, no cuántas veces ocurren. En casos como este, es recomendable reemplazar la función geom_point() por otra que contabilice el número de ocurrencias de cada combinación, para obtener una imagen que te dé una pista rápida sobre las variaciones en la frecuencia de los atentados. Para ello está disponible geom_count(), que además del efecto visual, añade al gráfico una escala de frecuencias.
Si te interesa, además, enriquecer la visualización mediante la adición de etiquetas al gráfico (ponerle un título, cambiar los nombres de las variables en los ejes, etcétera), puedes agregar una capa adicional con la función labs(). Incluso, puedes cambiar la apariencia general si agregas una capa con alguna de las variantes que te proveen las funciones theme_(), que permiten controlar los elementos del gráfico que no son datos. Obtendrás un resultado similar al de la Figura 5.
ggplot(at59, aes(x = ciudad, y = objeto)) +
geom_count() +
labs(title = "Atentados durante 1959", subtitle = "Objeto utilizado según ciudad", x = "CIUDAD", y = "OBJETO") +
theme_bw()
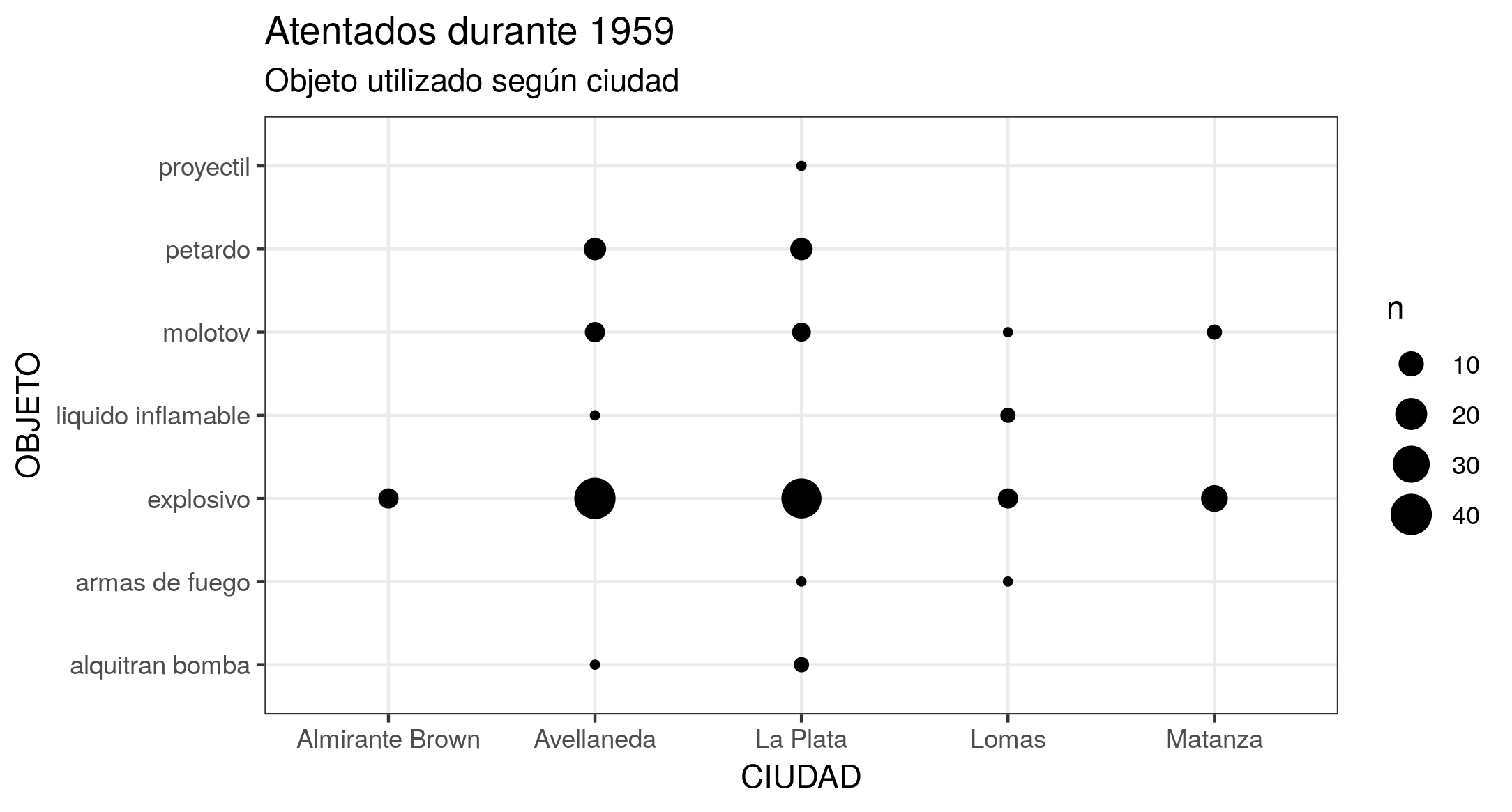
Figura 5. Gráfico de puntos que representa la frecuencia de atentados, según objeto y ciudad. El tamaño de los puntos depende del recuento de combinaciones entre objeto del atentado y ciudad. Se advierte que las ciudades de Avellaneda y La Plata concentran la mayor cantidad de atentados, y que en la mayoría de estos se utilizaron explosivos.
Para almacenar el gráfico en un archivo, cuentas con la función ggsave(), que guardará tu imagen en tu directorio de trabajo:
ggsave("nombre-archivo.png")
Otra forma de aprovechar las ventajas de visualización que te da R y evitar la superposición de puntos, es utilizando la propiedad jitter, que afecta la posición de los mismos. La función gráfica geom_jitter() te permite agregar una pequeña variación aleatoria a la ubicación de cada punto; esto es muy útil si trabajas posiciones discretas y conjuntos de datos pequeños. Para explorar otras capacidades estéticas, prueba, por ejemplo, aplicar como parámetro que el color de los puntos sea diferente según la ciudad, mediante el argumento colour. Como el argumento debe estar en formato numérico, debes convertirlo con as.numeric(). Además de establecer la coloración, tienes la posibilidad de manipular el tamaño de los puntos mediante el argumento size, su transparencia con alpha y la distancia interpuntos vertical u horizontal con width o height. Obtendrás un gráfico similar al de la Figura 6.
ggplot(at59, aes(x = ciudad, y = objeto)) +
geom_jitter(colour = as.numeric(at59$ciudad), size = 3) +
labs(title = "Atentados durante 1959", subtitle = "Objeto utilizado según ciudad", x = "CIUDAD", y = "OBJETO") +
theme_bw()
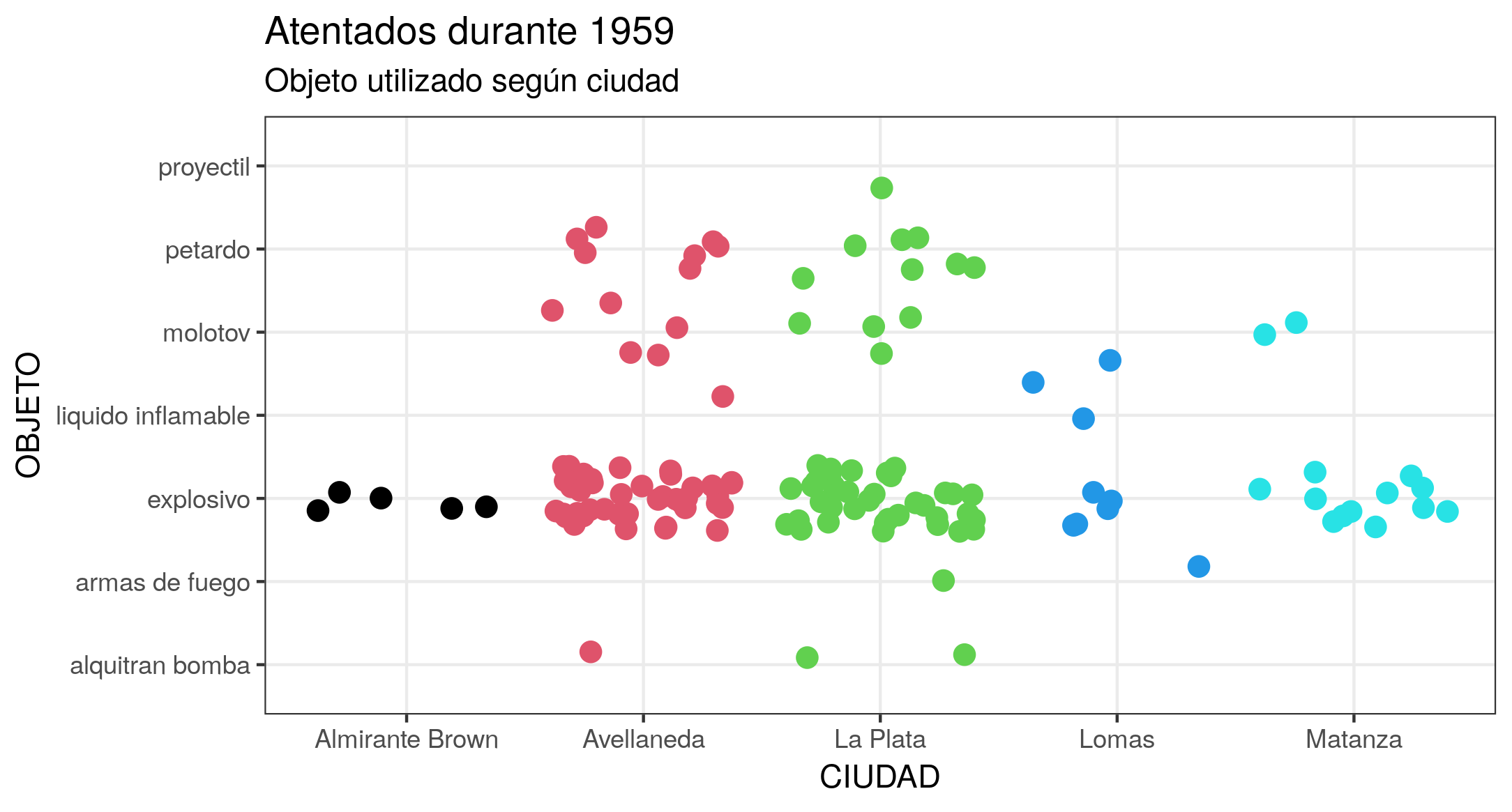
Figura 6. Gráfico que resulta de aplicar la función geom_jitter(). Permite visualizar la misma tendencia que el gráfico anterior (mayor cantidad de explosivos en Avellaneda y La Plata), pero asignando un punto por cada combinación objeto/ciudad evitando su superposición.
Animando la visualización de los datos con gganimate
Si bien existen distintos paquetes para animar visualizaciones en R, te invitamos a hacerlo con gganimate11, que es una extensión del paquete ggplot2 que te permitirá crear una animación a partir de un gráfico ggplot y ver de forma dinámica cómo tus datos evolucionan según estados o en el tiempo. Las funciones centrales de gganimate son las para transiciones (transition_*()), que permiten especificar cómo los datos deben interpretarse en términos de la su animación, es decir, según qué criterio se crearán los cuadros (frames) que se animarán.
Para instalar y activar el paquete puedes utilizar el código que se presenta a continuación. Si estás trabajando en Mac, te sugerimos instalar también la última versión del paquete gifski. Algunas personas han reportado problemas al generar las animaciones cuando utilizan una versión anterior a la 0.8.6.
install.packages("gganimate")
library (gganimate)
# Si trabajas en Mac y tu versión de gifski es anterior a 0.8.6
install.packages("gifski")
Si deseas generar una animación que represente la ocurrencia de atentados según una progresión temporal, la función indicada es transiton_time(). El procedimiento es muy sencillo; al código que escribiste para hacer el gráfico le sumas esta función, poniendo como argumento la variable temporal, en este caso, fecha. Sin embargo, con el fin de realizar una visualización más clara de tus datos, es conveniente que al código le agregues un par de elementos.
Por un lado, como en gganimate la animación resultante es un conjunto de imágenes (instantáneas) desplegadas en serie consecutiva, cada nuevo frame -si no le indicas lo contrario- al mostrarse oculta el anterior y sólo lograrás ver puntos parpadeando. Para manejar esto, cuentas con el grupo de funciones shadow, que te deja elegir cómo se muestran los datos que ya no se corresponden con los del frame actual. En el caso de este gráfico, para que permanezcan todos los datos anteriores de fondo, es necesario utilizar shadow_mark(past = TRUE), que te permite dejar visibles los cuadros ya mostrados.
Por otra parte, como puede ser bastante difícil entender una animación sin ninguna indicación sobre el significado de cada punto temporal, gganimate te proporciona un conjunto de variables para cada fotograma (frame variables), los cuales puedes insertar en las etiquetas de los gráficos utilizando la sintaxis propia del paquete glue, que utiliza los símbolos {}. Con ello dispondrás de una serie de metadatos, según la variante de transición que ensayes. Para transition_time() cuentas con {frame_time}, que te retornará el valor del argumento que procesa la función durante el fotograma en curso, es decir, te permitirá ir viendo la fecha correspondiente. El código quedaría de esta manera:
ggplot(at59, aes(x = ciudad, y = objeto)) +
geom_jitter(colour = as.numeric(at59$ciudad), size = 4) +
labs(title = "Atentados durante 1959", subtitle = "Objeto utilizado según ciudad - Fecha: {frame_time}", x = "CIUDAD", y = "OBJETO") +
theme_bw() +
transition_time(fecha) +
shadow_mark(past = TRUE)
Al ingresar el código directamente en la consola, comienza el proceso de generación de la animación, denominado rendering. Este proceso tiene una duración relativa, dependiendo del volumen de los datos y de tu procesado. En este caso sólo debería tomar unos segundos, durante los cuales podrás ver una barra de progreso que te indicará cuánto falta. Cuando concluya, en la pestaña Viewer de la ventana de utilidades podrás observar la animación. Si presionas el ícono Show in new window, se abrirá un gif en tu navegador asociado por defecto, desde donde podrás almacenarlo. En caso de que te interese continuar practicando con la consola, también puedes almacenarlo con la función anim_save(), que guarda la última animación realizada en tu directorio de trabajo:
anim_save("nombre-archivo.gif")
Para poder explorar más posibilidades del paquete gganimate, la sugerencia es que asignes el bloque de código para generar el gráfico a un objeto. Esto te dará la posibilidad de manejar parámetros como la velocidad y las pausas en la animación por medio de la función animate(). Con ella podrás ajustar también la cantidad total de frames, la duración total y los frames por segundo. Para ensayarlo, dale a fps un parámetro de 5 cuadros por segundo y añade una pausa final de 15 segundos con end_pause. Con ello obtendrás una animación similar a la Figura 7.
atentados <- ggplot(at59, aes(x = ciudad, y = objeto)) +
geom_jitter(colour = as.numeric(at59$ciudad), size = 4) +
labs(title = "Atentados durante 1959", subtitle = "Objeto utilizado según ciudad - Fecha: {frame_time}", x = "CIUDAD", y = "OBJETO") +
theme_bw() +
transition_time(fecha) +
shadow_mark(past = TRUE)
animate(atentados, fps = 5, end_pause = 15)
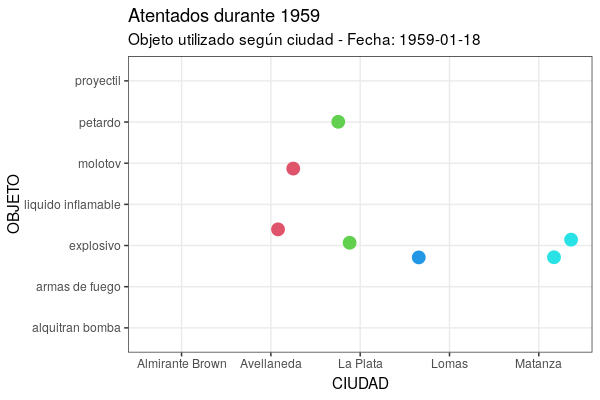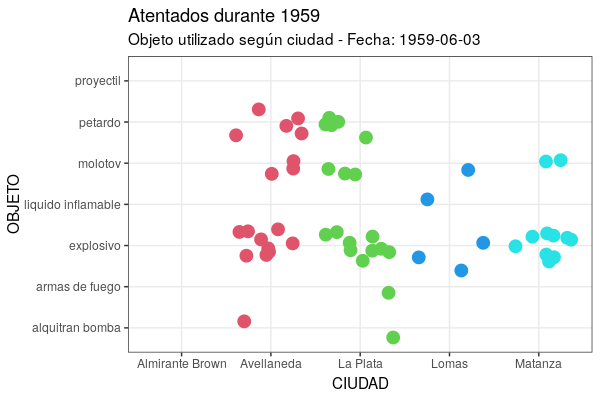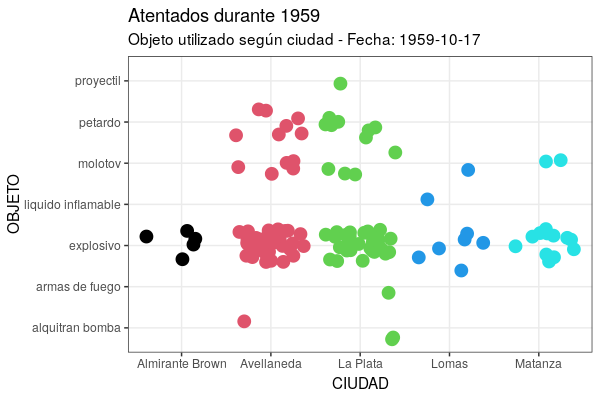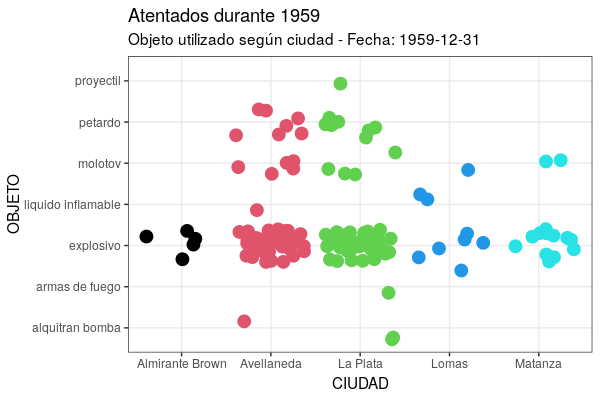
Figura 7. Versión animada del gráfico creado con la función geom_jitter.
A esta altura y con estos resultados, puedes considerar que has realizado un análisis exploratorio de tus datos y estás en condiciones de plantear hipótesis al respecto. En el caso trabajado, y si te dedicas a la historia de las luchas sociales y políticas en Argentina contemporánea, las tablas de contingencia y los gráficos estáticos trabajadas en esta lección, por ejemplo, te permiten encontrar similitudes entre Avellaneda y La Plata, tanto entre las frecuencias de los atentados, como en su tipo (en términos del objeto utilizado). Además, disponemos del ritmo temporal (intensidad) de los mismos, lo que te invita a enfocar sobre posibles patrones o relaciones de corte más histórico, entre casos que no suelen estar conectados en las investigaciones, por su diferente estructura socio-económica para la época.
Conclusión
Esta lección buscó darte una idea general de las diversas tareas que deberías seguir para preparar y llevar adelante un primer análisis exploratorio de datos sobre alguna serie de documentos históricos. Este procedimiento te permite realizar cálculos básicos con esos datos y analizarlos visualmente para pensar, generar preguntas e hipotetizar a partir de ellos.
En esta lección te hemos ofrecido solo un punto de partida para el análisis de tus tablas históricas. Como desafío, y a partir de lo que aprendiste en este tutorial, te proponemos que continúes probando otros cruces de variables. Finalmente, te invitamos a que te animes a descubrir por ti mismo la potencia de ggplot y gganimate, explorando la documentación de este último paquete para conocer otras opciones disponibles.
Notas
-
Roderick Floud, Métodos cuantitativos para historiadores (Madrid: Alianza, 1983). ↩
-
Puedes encontrar una detallada referencia del archivo en el sitio de la Comisión Provincial por la Memoria de la provincia de Buenos Aires: https://www.comisionporlamemoria.org/extra/archivo/cuadroclasificacion/ ↩
-
Los fundamentos y significado de la noción de “datos ordenados” puedes encontrarlos en: Hadley Wickham, “Tidy Data”, Journal of Statistical Software, Volume 59, Issue 10, 2019,https://www.jstatsoft.org/index.php/jss/article/view/v059i10/v59i10.pdf) ↩
-
Hadley Wickham and Jennifer Bryan, “readxl: Read Excel Files. R package version 1.3.1”, 2019, https://CRAN.R-project.org/package=readxl ↩
-
Hadley Wickham et al.,”Welcome to the tidyverse”, Journal of Open Source Software, 4(43), 1686 (2019): 1-5, https://doi.org/10.21105/joss.01686 ↩
-
Lionel Henry and Hadley Wickham, “purrr: Functional Programming Tools. R package version 0.3.4”, 2020, https://CRAN.R-project.org/package=purrr ↩
-
Hadley Wickham, Romain François, Lionel Henry and Kirill Müller, “dplyr: A Grammar of Data Manipulation. R package version 1.0.6”, CRAN R Project, 2021, https://CRAN.R-project.org/package=dplyr ↩
-
Hao Zhu, “kableExtra: Construct Complex Table with ‘kable’ and Pipe Syntax. R package version 1.3.2”, 2021, https://CRAN.R-project.org/package=kableExtra ↩
-
Hadley Wickham, “ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics”, Springer-Verlag New York, 2016, https://ggplot2.tidyverse.org ↩
-
El referente del concepto es Leland Wilkinson, con su obra The Grammar of Graphics, de la que puedes consultar algunas páginas en: https://www.springer.com/gp/book/9780387245447 ↩
-
Thomas Lin Pedersen and David Robinson, “gganimate: A Grammar of Animated Graphics. R package version 1.0.7”, 2020, https://CRAN.R-project.org/package=gganimate ↩