
Contenidos
- Objetivos
- Un pequeño ejemplo
- Análisis del discurso del Estado de la Unión de 2016 de Barak Obama
- Análisis de los discursos del Estado de la Unión desde 1790 a 2016
- Siguientes pasos
- Notas
Objetivos
Hoy en día hay una cantidad sustancial de datos históricos disponibles en forma de texto simple digitalizado. Algunos ejemplos comunes son cartas, artículos periodísticos, notas personales, entradas de diario, documentos legales y transcripciones de discursos. Mientras que algunas aplicaciones de software independientes ofrecen herramientas para el análisis de datos textuales, el uso de lenguajes de programación presenta una mayor flexibilidad para analizar un corpus de documentos de texto. En este tutorial se introduce a los usuarios en las bases del análisis de texto con el lenguaje de programación R. Nuestro acercamiento involucra únicamente el uso de un tokenizador (tokenizer) que realiza un análisis sintáctico del texto con elementos como palabras, frases y oraciones. Al final de esta lección los usuarios podrán:
- utilizar análisis exploratorios para verificar errores y detectar patrones de nivel general;
- aplicar métodos básicos de estilometría a lo largo del tiempo y entre autores;
- enfocarse en el resumen de resultados para ofrecer descripciones de nivel general de los elementos en un corpus.
Para el particular se utilizará un conjunto de datos compuesto por los textos de los discursos del Estado de la Unión de los Estados Unidos1.
Asumimos que los usuarios tienen un conocimiento básico del lenguaje de programación R. La lección ‘R Basics with Tabular Data’ de Taryn Dewar2 es una excelente guía que trata todo el conocimiento sobre R aquí asumido: instalar y abrir R, instalar y cargar paquetes, e importar y trabajar con datos básicos de R. Los usuarios pueden descargar R para su sistema operativo desde The Comprehensive R Archive Network. Aunque no es un requisito, también recomendamos que los nuevos usuarios descarguen R Studio, un entorno de desarrollo de código abierto para escribir y ejecutar programas en R.
Todo el código de esta lección fue probado en la versión 3.3.2 de R, pero creemos que funcionará correctamente en versiones futuras del programa.
Un pequeño ejemplo
Configuración de paquetes
Es necesario instalar dos paquetes de R antes de comenzar con el tutorial. Estos son tidyverse3 y tokenizers4. El primero proporciona herramientas cómodas para leer y trabajar con grupos de datos y el segundo contiene funciones para dividir los datos de texto en palabras y oraciones. Para instalarlos, abre R en tu ordenador y ejecuta estas dos líneas de código en la consola:
install.packages("tidyverse")
install.packages("tokenizers")
Dependiendo de la configuración de tu sistema, puede que se abra un cuadro de diálogo pidiéndote que elijas un sitio espejo (mirror) del que realizar la descarga. Escoge uno cerca de tu localización. La descarga y la instalación deberían realizarse automáticamente.
Ahora que estos paquetes están descargados en tu ordenador, tenemos que decirle a R que los cargue para usarlos. Hacemos esto mediante el comando library(librería); puede que aparezcan algunos avisos mientras se cargan otras dependencias, pero por lo general se pueden ignorar sin mayor problema.
library(tidyverse)
library(tokenizers)
Mientras que solo necesitas ejecutar el comando install.packages (instalar paquetes) la primera vez que inicias este tutorial, tendrás que ejecutar el comando library cada vez que reinicies R5.
Segmentación de palabras
En esta sección vamos a trabajar con un único párrafo. Este ejemplo pertenece al comienzo del último discurso sobre el Estado de la Unión de Barack Obama en 2016. Para facilitar la comprensión del tutorial en esta primera etapa, estudiamos este párrafo en su versión en español6.
Para cargar el texto copia y pega lo siguiente en la consola de R.
texto <- paste("También entiendo que como es temporada de elecciones, las expectativas para lo que lograremos este año son bajas. Aún así, señor Presidente de la Cámara de Representantes, aprecio el enfoque constructivo que usted y los otros líderes adoptaron a finales del año pasado para aprobar un presupuesto, y hacer permanentes los recortes de impuestos para las familias trabajadoras. Así que espero que este año podamos trabajar juntos en prioridades bipartidistas como la reforma de la justicia penal y ayudar a la gente que está luchando contra la adicción a fármacos de prescripción. Tal vez podamos sorprender de nuevo a los cínicos.")
Después de ejecutar esto (haciendo clic en ‘Intro’), escribe la palabra texto en la consola y haz clic en ‘Intro’. R imprimirá el párrafo de texto porque la variable ‘texto’ ahora contiene el documento.
Como primer paso en el procesamiento del texto vamos a usar la función tokenize_words (segmentar palabras) del paquete tokenizers para dividir el texto en palabras individuales.
palabras <- tokenize_words(texto)
Para imprimir los resultados en la ventana de la consola de R, mostrando tanto el resultado tokenizado como la posición de cada elemento en el margen izquierdo, ejecuta palabras en la consola:
palabras
Esto produce el siguiente resultado:
> [[1]]
[1] "también" "entiendo" "que" "como"
[5] "es" "temporada" "de" "elecciones"
[9] "las" "expectativas" "para" "lo"
[13] "que" "lograremos" "este" "año"
[17] "son" "bajas" "aún" "así"
[21] "señor" "presidente" "de" "la"
[25] "cámara" "de" "representantes" "aprecio"
[29] "el" "enfoque" "constructivo" "que"
[33] "usted" "y" "los" "otros"
[37] "líderes" "adoptaron" "a" "finales"
[41] "del" "año" "pasado" "para"
[45] "aprobar" "un" "presupuesto" "y"
[49] "hacer" "permanentes" "los" "recortes"
[53] "de" "impuestos" "para" "las"
[57] "familias" "trabajadoras" "así" "que"
[61] "espero" "que" "este" "año"
[65] "podamos" "trabajar" "juntos" "en"
[69] "prioridades" "bipartidistas" "como" "la"
[73] "reforma" "de" "la" "justicia"
[77] "penal" "y" "ayudar" "a"
[81] "la" "gente" "que" "está"
[85] "luchando" "contra" "la" "adicción"
[89] "a" "fármacos" "de" "prescripción"
[93] "tal" "vez" "podamos" "sorprender"
[97] "de" "nuevo" "a" "los"
[101] "cínicos"
¿Cómo ha cambiado el texto cargado después de ejecutar esa función de R? Ha eliminado todos los signos de puntuación, ha dividido el texto en palabras individuales y ha convertido todo a minúsculas. Veremos a continuación por qué todas estas intervenciones son útiles para nuestro análisis.
¿Cuántas palabras hay en este fragmento de texto? Si usamos la función length (longitud) directamente en el objeto palabras, el resultado no es muy útil que digamos.
length(palabras)
El resultado es igual a:
[1] 1
La razón por la cual la longitud equivale a 1 es que la función tokenize_words devuelve una lista de objetos con una entrada por documento cargado. Nuestro ingreso solo tiene un documento y, por tanto, la lista contiene solo un elemento. Para ver las palabras dentro del primer documento, usamos el símbolo del corchete para seleccionar solo el primer elemento de la lista, así:
length(palabras[[1]])
El resultado es 101, lo cual indica que hay 101 palabras en nuestro párrafo.
La separación del documento en palabras individuales hace posible calcular cuántas veces se utilizó cada palabra en el texto. Para hacer esto, primero aplicamos la función table(tabla) a las palabras en el primer (y aquí, único) documento y después separamos los nombres y los valores de la tabla en un único objeto llamado marco de datos (data frame). Los marcos de datos en R son utilizados de manera similar a como se utiliza una tabla en una base de datos. Estos pasos, junto con la impresión de los resultados, son conseguidos con las siguientes líneas de código:
tabla <- table(palabras[[1]])
tabla <- data_frame(palabra = names(tabla), recuento = as.numeric(tabla))
tabla
El resultado de este comando debería parecerse a este en tu consola (una tibble es una variedad específica de marco de datos creado bajo el enfoque Tidy Data):
# A tibble: 70 x 2
palabra recuento
<chr> <dbl>
1 a 4.
2 adicción 1.
3 adoptaron 1.
4 año 3.
5 aprecio 1.
6 aprobar 1.
7 así 2.
8 aún 1.
9 ayudar 1.
10 bajas 1.
# ... with 60 more rows
Hay una gran cantidad de información en esta muestra. Vemos que hay 70 palabras únicas, como indica la dimensión de la tabla. Se imprimen las 10 primeras filas del conjunto de datos con la segunda columna indicando el número de veces que la palabra de la primera columna ha sido usada. Por ejemplo, “a” se usó 4 veces pero “ayudar” solo se usó una vez.
También podemos ordenar la tabla usando la función arrange(organizar). Esta función toma el conjunto de datos sobre el que trabajar, aquí tabla, y después el nombre de la columna que toma como referencia para ordenarlo. La función desc en el segundo argumento indica que queremos clasificar en orden descendiente.
arrange(tabla, desc(recuento))
Y el resultado ahora será:
# A tibble: 70 x 2
palabra recuento
<chr> <dbl>
1 de 7.
2 que 6.
3 la 5.
4 a 4.
5 año 3.
6 los 3.
7 para 3.
8 y 3.
9 así 2.
10 como 2.
# ... with 60 more rows
Las palabras más comunes son pronombres y palabras de función como “de”, “que”, “la” y “a”. Advierte como se facilita el análisis al usar la versión en minúscula de cada palabra. La palabra “así” en la segunda oración no es tratada de diferente manera a “Así” al comienzo de la tercera oración.
Una técnica popular es cargar una lista de palabras usadas con gran frecuencia y eliminarlas antes del análisis formal. Las palabras en dicha lista se denominan “stopwords” o “palabras vacías” y normalmente se trata de pronombres, conjugaciones de los verbos más comunes y conjunciones. En este tutorial usaremos una variación matizada de esta técnica.
Detectar oraciones
El paquete tokenizer también contiene la función tokenize_sentences que divide el texto en oraciones en vez de en palabras. Se puede ejecutar de la siguiente manera:
oraciones <- tokenize_sentences(texto)
oraciones
Con el resultado:
> oraciones
[[1]]
[1] "También entiendo que como es temporada de elecciones, las expectativas para lo que lograremos este año son bajas."
[2] "Aún así, señor Presidente de la Cámara de Representantes, aprecio el enfoque constructivo que usted y los otros líderes adoptaron a finales del año pasado para aprobar un presupuesto, y hacer permanentes los recortes de impuestos para las familias trabajadoras."
[3] "Así que espero que este año podamos trabajar juntos en prioridades bipartidistas como la reforma de la justicia penal y ayudar a la gente que está luchando contra la adicción a fármacos de prescripción."
[4] "Tal vez podamos sorprender de nuevo a los cínicos."
El resultado es un vector de caracteres, un objeto unidimensional que consta únicamente de elementos representados como caracteres. Advierte que el resultado ha marcado cada oración como un elemento separado.
Es posible conectar el resultado de la división de oraciones con el de la división por palabras. Si ejecutamos la división de oraciones del párrafo con la función tokenize_words, cada oración es tratada como un único documento. Ejecuta esto usando la siguiente línea de código y observa si el resultado se parece al que estabas esperando; usa la segunda línea para imprimir el resultado.
oraciones_palabras <- tokenize_words(oraciones[[1]])
oraciones_palabras
Si miramos el tamaño del resultado directamente podemos ver que hay cuatro “documentos” en el objeto oraciones_palabras:
length(oraciones_palabras)
Accediendo a cada uno directamente, es posible saber cuántas palabras hay en cada oración del párrafo:
length(oraciones_palabras[[1]])
length(oraciones_palabras[[2]])
length(oraciones_palabras[[3]])
length(oraciones_palabras[[4]])
Esto puede ser algo engorroso pero, afortunadamente, hay una forma más sencilla de hacerlo. La función sapply ejecuta la función en el segundo argumento a cada elemento en el primer argumento. Como resultado, podemos calcular la longitud de cada oración en el primer párrafo con una sola línea de código:
sapply(oraciones_palabras, length)
El resultado es este:
[1] 18 40 34 9
Podemos ver que hay cuatro oraciones con una longitud de 18, 40, 34 y 9 palabras. Utilizaremos esta función para manejar documentos más grandes.
Análisis del discurso del Estado de la Unión de 2016 de Barak Obama
Análisis exploratorio
Vamos a aplicar las técnicas de la sección previa a un discurso del Estado de la Unión completo. Por motivos de consistencia, vamos a usar el mismo discurso de 2016 de Obama. Aquí vamos a cargar los datos desde un archivo puesto que copiarlo directamente se vuelve difícil a gran escala.
Para hacer esto, vamos a combinar la función readLines (leer líneas) para cargar el texto en R y la función paste (pegar) para combinar todas las líneas en un único objeto. Vamos a crear la URL del archivo de texto usando la función sprintf puesto que este formato permitirá su fácil modificación para otras direcciones web78.
base_url <- "https://raw.githubusercontent.com/programminghistorian/jekyll/gh-pages/assets/basic-text-processing-in-r/"
url <- sprintf("%s/sotu_text/236.txt", base_url)
texto <- paste(readLines(url), collapse = "\n")
Como antes, vamos a segmentar el texto y ver el número de palabras que hay en el documento.
palabras <- tokenize_words(texto)
length(palabras[[1]])
Vemos que este discurso contiene un total de 6113 palabras. Combinando las funciones de table (tabla), data_frame (marco de datos) y arrange (organizar), como lo hicimos en el ejemplo, obtenemos las palabras más frecuentes del discurso entero. Mientras haces esto, advierte lo fácil que es reutilizar código previo para repetir el análisis en un nuevo grupo de datos; esto es uno de los mayores beneficios de usar un lenguaje de programación para realizar un análisis basado en datos.
tabla <- table(palabras[[1]])
tabla <- data_frame(word = names(tabla), count = as.numeric(tabla))
tabla <- arrange(tabla, desc(count))
tabla
El resultado debería ser:
>#A tibble: 1,590 x 2
word count
<chr> <dbl>
1 the 281.
2 to 209.
3 and 189.
4 of 148.
5 that 125.
6 we 124.
7 a 120.
8 in 105.
9 our 96.
10 is 72.
>#... with 1,580 more rows
De nuevo, palabras extremamente comunes como “the”, “to”, “and” y “of” están a la cabeza de la tabla. Estos términos no son particularmente esclarecedores si queremos saber el tema del discurso. En realidad, queremos encontrar palabras que destaquen más en este texto que en un corpus externo amplio en inglés. Para lograr esto necesitamos un grupo de datos que proporcione estas frecuencias. Aquí está el conjunto de datos de Peter Norviq usando el Google Web Trillion Word Corpus (Corpus de un trillón de palabras web de Google), recogido de los datos recopilados a través del rastreo de sitios web más conocidos en inglés realizado por Google10:
palabras_frecuentes <- read_csv(sprintf("%s/%s", base_url, "word_frequency.csv"))
palabras_frecuentes
La primera columna indica el lenguaje (siempre “en” por el inglés en este caso), la segunda aporta la palabra en cuestión y la tercera el porcentaje con que aparece en el Corpus de un trillón de palabras de Google. Por ejemplo, la palabra “for” aparece casi exactamente 1 vez cada 100 palabras, por lo menos en los textos de webs indexadas por Google.
Para combinar estas palabras frecuentes con el grupo de datos en la tabla construida a partir de este discurso del Estado de la Unión, podemos utilizar la función inner_join (unión interna). Esta función toma dos grupos de datos y los combina en todas las columnas que tengan el mismo nombre; en este caso la columna común es la que se llama “palabra”.
tabla <- inner_join(tabla, palabras_frecuentes)
tabla
Ten en cuenta que ahora nuestro grupo de datos tiene dos columnas extras que aportan el lenguaje (aquí relativamente poco útil ya que siempre es “en”) y la frecuencia de la palabra en el corpus externo. Esta segunda nueva columna será muy útil porque podemos filtrar filas que tengan una frecuencia menor al 0.1%, esto es, que aparezcan más de una vez en cada 1000 palabras:
filter(tabla, frequency < 0.1)
Esto da:
>#A tibble: 1,457 x 4
word count language frequency
<chr> <dbl> <chr> <dbl>
1 america 28. en 0.0232
2 people 27. en 0.0817
3 just 25. en 0.0787
4 world 23. en 0.0734
5 american 22. en 0.0387
6 work 22. en 0.0713
7 make 20. en 0.0689
8 want 19. en 0.0440
9 change 18. en 0.0358
10 years 18. en 0.0574
>#... with 1,447 more rows
Esta lista ya comienza a ser más interesante. Un término como “america” aparece a la cabeza de la lista porque, podemos pensar, se utiliza mucho en los discursos de los políticos y menos en otros ámbitos. Al establecer el umbral aun más bajo, a 0.002, obtenemos un mejor resumen del discurso. Puesto que sería útil ver más que las diez líneas por defecto, vamos a usar la función print (imprimir) junto con la opción n (de número) configurada a 15 para poder ver más líneas.
print(filter(tabla, frequency < 0.002), n = 15)
Esto ahora nos muestra el siguiente resultado:
>#A tibble: 463 x 4
word count language frequency
<chr> <dbl> <chr> <dbl>
1 laughter 11. en 0.000643
2 voices 8. en 0.00189
3 allies 4. en 0.000844
4 harder 4. en 0.00152
5 qaida 4. en 0.000183
6 terrorists 4. en 0.00122
7 bipartisan 3. en 0.000145
8 generations 3. en 0.00123
9 stamp 3. en 0.00166
10 strongest 3. en 0.000591
11 syria 3. en 0.00136
12 terrorist 3. en 0.00181
13 tougher 3. en 0.000247
14 weaken 3. en 0.000181
15 accelerate 2. en 0.000544
>#... with 448 more rows
Los resultados parecen sugerir algunos de los temas principales de este discurso como “syria” (Siria), “terrorist” (terrorismo) y “qaida” (Qaeda) (al-qaida está dividido en “al” y “qaida” por el tokenizador).
Resumen del documento
Para proporcionar información contextual al conjunto de datos que estamos analizando, tenemos una tabla con metadatos sobre cada uno de los discursos del Estado de la Unión. Vamos a cargarla a R:
metadatos <- read_csv(sprintf("%s/%s", base_url, "metadata.csv"))
metadatos
Aparecerán las primeras diez líneas del grupo de datos así:
>#A tibble: 236 x 4
president year party sotu_type
<chr> <int> <chr> <chr>
1 George Washington 1790 Nonpartisan speech
2 George Washington 1790 Nonpartisan speech
3 George Washington 1791 Nonpartisan speech
4 George Washington 1792 Nonpartisan speech
5 George Washington 1793 Nonpartisan speech
6 George Washington 1794 Nonpartisan speech
7 George Washington 1795 Nonpartisan speech
8 George Washington 1796 Nonpartisan speech
9 John Adams 1797 Federalist speech
10 John Adams 1798 Federalist speech
>#... with 226 more rows
Tenemos el nombre del presidente, el año, el partido político del presidente y el formato del discurso del Estado de la Unión (oral o escrito) de cada discurso en el conjunto. El discurso de 2016 está en la línea 236 de los metadatos, que casualmente es la última línea.
En la siguiente sección puede ser útil resumir los datos de un discurso en una única línea de texto. Podemos hacer esto extrayendo las cinco palabras más frecuentes con una frecuencia menor al 0.002% en el Corpus de un trillón de palabras de Google y combinando esto con los datos sobre el presidente y el año.
tabla <- filter(tabla, frequency < 0.002)
resultado <- c(metadatos$president[236], metadatos$year[236], tabla$word[1:5])
paste(resultado, collapse = "; ")
Esto debería darnos el siguiente resultado:
[1] "Barack Obama; 2016; laughter; voices; allies; harder; qaida"
[1] "Barack Obama; 2016; risa; voces; aliados; más duro; qaeda"
¿Capta esta línea todo lo relativo al discurso? Por supuesto que no. El procesamiento de texto nunca va a reemplazar a la lectura atenta de un texto, pero ayuda a dar un resumen de alto nivel de los temas discutidos (la “risa” aparece aquí porque en el texto del discurso están anotadas las reacciones de la audiencia). Este resumen es útil de varias formas. Puede dar un buen título y resumen para un documento que carece de ellos; puede servir para recordar a los lectores que han leído o escuchado el discurso cuáles fueron los temas principales discutidos en él; y recopilar varios resúmenes con una sola acción puede mostrar patrones de gran escala que suelen perderse en corpus amplios. Es este último uso al que recurrimos ahora al aplicar las técnicas de esta sección a un grupo más amplio de discursos del Estado de la Unión.
Análisis de los discursos del Estado de la Unión desde 1790 a 2016
Cargar el corpus
Lo primero que hay que hacer para analizar el corpus de discursos sobre el Estado de la Unión es cargarlos todos en R. Esto implica las mismas funciones paste (pegar) y readLines (leer líneas) que antes, pero tenemos que generar un bucle for (para) que ejecuta las funciones en los 236 archivos de texto. Estos se combinan con la función c.
archivos <- sprintf("%s/sotu_text/%03d.txt", base_url, 1:236)
texto <- c()
for (f in archivos) {
texto <- c(texto, paste(readLines(f), collapse = "\n"))
}
Esta técnica carga todos los archivos uno por uno desde Github. Opcionalmente, puedes descargar una archivo zip (comprimido) con el corpus completo y cargar los archivos manualmente. Esta técnica es descrita en la siguiente sección.
Forma alternativa de cargar el corpus (opcional)
El corpus completo puede descargarse aquí: sotu_text.zip. Descomprime el repositorio en algún lugar de tu ordenador y fija la variable input_loc (localización de carga) a la ruta de directorio donde has descomprimido el archivo. Por ejemplo, si los archivos están en el escritorio de un ordenador con el sistema operativo macOS y el usuario es stevejobs, input_loc debería ser:
input_loc <- "/Users/stevejobs/Desktop/sotu_text"
Una vez hecho esto, puedes usar el siguiente bloque de código para cargar todos los textos:
archivos <- dir(input_loc, full.names = TRUE)
texto <- c()
for (f in archivos) {
texto <- c(texto, paste(readLines(f), collapse = "\n"))
}
Puedes usar esta misma técnica para cargar tu propio corpus de textos.
Análisis exploratorio
Una vez más, con la función tokenize_words podemos calcular la longitud de cada discurso en número de palabras.
palabras <- tokenize_words(texto)
sapply(palabras, length)
¿Existe un patrón temporal sobre la longitud de los discursos? ¿Cómo se compara la longitud de los discursos de otros presidentes a los de Franklin D. Roosevelt, Abraham Lincoln y George Washington?
La mejor forma de saberlo es mediante la creación un gráfico de dispersión. Puedes construir uno usando qplot (gráfico), con el año (year) en el eje-x u horizontal y el número de palabras (length) en el eje-y o vertical.
qplot(metadatos$year, sapply(palabras, length)) + labs(x = "Año", y = "Número de palabras")
Esto crea un gráfico como este:
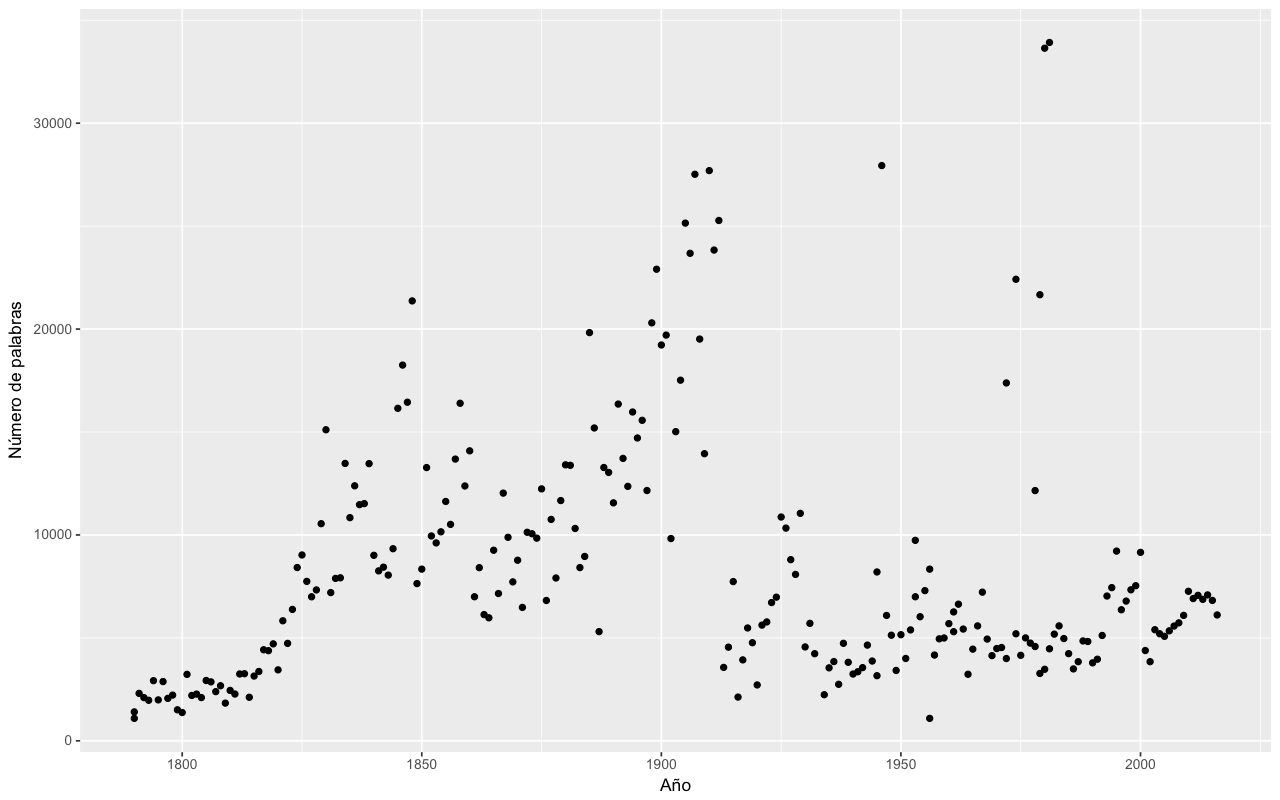
Número de palabras en cada Estado de la Unión dispuestos por año
Utiliza la opción `+ labs(x = "nombre", y = "nombre")` para añadir un nombre a los ejes de tu gráfico y facilitar así su lectura. [N. de la T.]
Parece que en su mayor parte los discursos incrementaron su longitud de 1790 a 1850 y después incrementaron de nuevo hacia finales del siglo XIX. La longitud disminuyó drásticamente alrededor de la Primera Guerra Mundial, con unos pocos valores atípicos dispersos a lo largo del siglo XX.
¿Hay algún tipo de razón tras estos cambios? Para explicar esta variación podemos configurar el color de los puntos para denotar si se trata de discursos que fueron presentados de forma escrita o de forma oral. El comando para realizar este gráfico solo conlleva un pequeño cambio en el comando del gráfico:
qplot(metadatos$year, sapply(palabras, length), color = metadatos$sotu_type) + labs(x = "Año", y = "Número de palabras", color = "Modalidad del discurso")
Esto proporciona el siguiente gráfico:
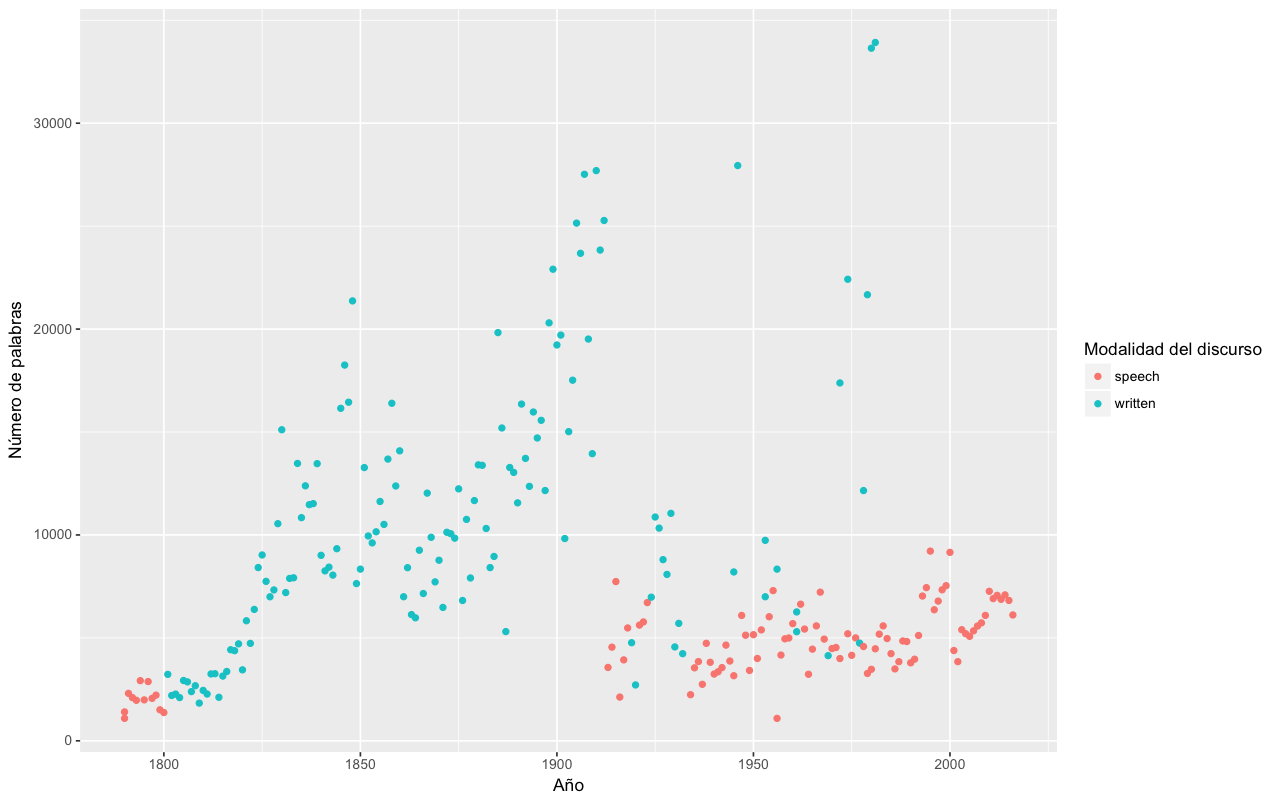
Número de palabras en cada Estado de la Unión dispuestos por año y con el color denotando si se trató de un discurso escrito u oral
Vemos que el incremento en el siglo XIX se dio cuando los discursos pasaron a ser documentos escritos y que la caída drástica se dio cuando Woodrow Wilson (28º presidente de los EEUU de 1913 a 1921) rompió con la tradición y dio su discurso sobre el Estado de la Unión de forma oral en el Congreso. Los valores atípicos que vimos previamente fueron discursos dados de forma escrita después de la Segunda Guerra Mundial.
Análisis estilométrico
La estilometría, el estudio lingüístico del estilo, utiliza ampliamente los métodos computacionales para describir el estilo de escritura de un autor. Con nuestro corpus, es posible detectar cambios en el estilo de escritura a lo largo de los siglos XIX y XX. Un estudio estilométrico más formal usualmente implica el uso de código de análisis sintáctico o de reducciones dimensionales algorítmicas complejas como el análisis de componentes principales para el estudio a lo largo del tiempo y en varios autores. En este tutorial nos seguiremos enfocando en el estudio de la longitud de las oraciones.
El corpus puede dividirse en oraciones usando la función tokenize_sentences. En este caso el resultado es una lista con 236 objetos en ella, cada uno representando un documento específico.
oraciones <- tokenize_sentences(texto)
Lo siguiente es dividir cada oración en palabras. Se puede usar la función tokenize_words pero no directamente sobre las oraciones en la lista de objetos. Podríamos hacer esto con un bucle for nuevo pero hay una forma más sencilla de hacerlo. La función sapply ofrece un acercamiento más directo. Aquí, queremos aplicar la segmentación de palabras individualmente a cada documento y, por tanto, esta función es perfecta.
oraciones_palabras <- sapply(oraciones, tokenize_words)
Ahora tenemos una lista (con cada elemento representando un documento) de listas (con cada elemento representando las palabras en una oración dada). El resultado que necesitamos es una lista de objetos que dé la longitud de cada oración en un documento dado. Para ello, combinamos el bucle for con la función sapply.
longitud_oraciones <- list()
for (i in 1:nrow(metadatos)) {
longitud_oraciones[[i]] <- sapply(oraciones_palabras[[i]], length)
}
El resultado de longitud_oraciones puede ser visualizado sobre una línea temporal. Primero tenemos que resumir la longitud de todas las oraciones en un documento a un único número. La función median, que encuentra el percentil 50º de los datos ingresados, es una buena opción para resumirlos, puesto que no se verá demasiado afectada por el error de segmentación que haya podido crear una oración artificalmente larga11.
media_longitud_oraciones <- sapply(longitud_oraciones, median)
Ahora creamos un diagrama con esta variable junto con los años de los discursos usando, una vez más, la función qplot.
qplot(metadatos$year, media_longitud_oraciones) + labs(x = "Año", y = "Longitud media de las oraciones")
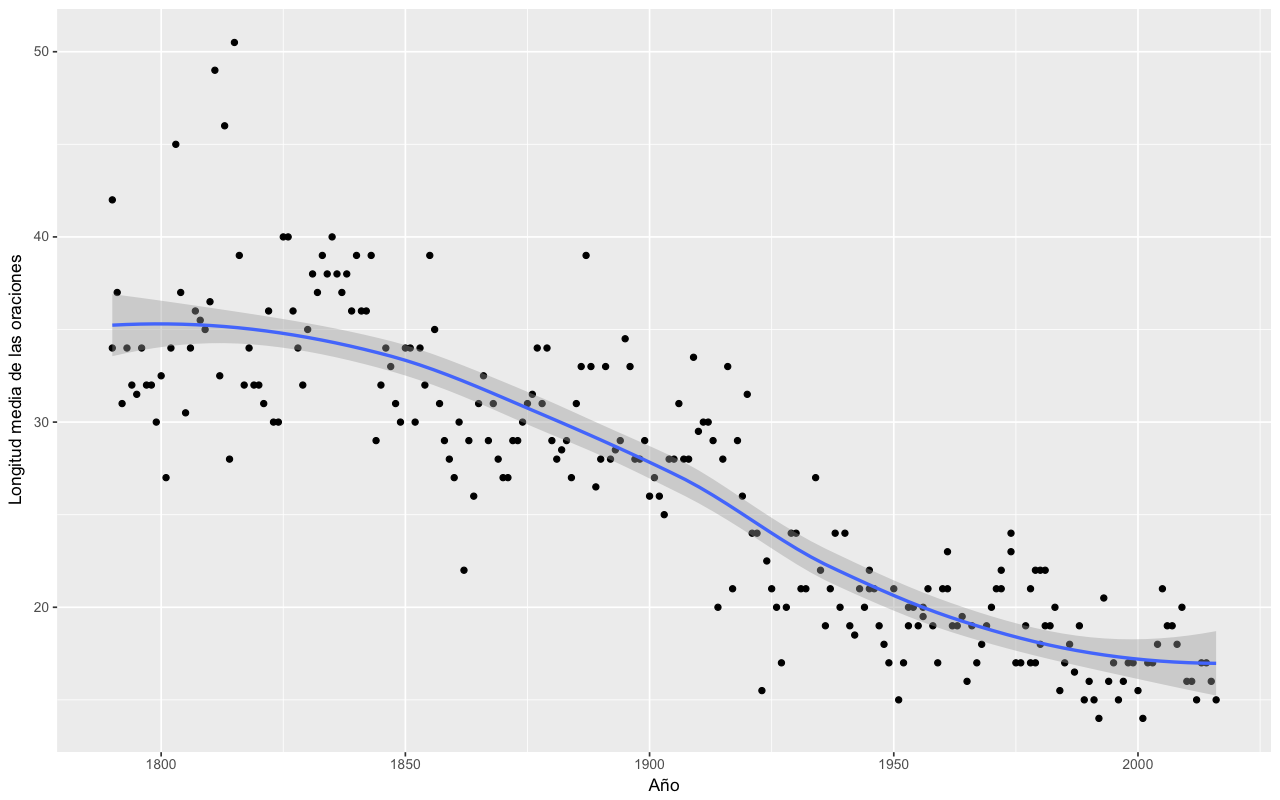
Longitud media de las oraciones por cada discurso del Estado de la Unión
El gráfico muestra una fuerte evolución a oraciones más cortas a lo largo de los dos siglos de nuestro corpus. Recuerda que algunos discursos hacia el final de la segunda mitad del siglo XX eran discursos escritos largos parecidos a los del siglo XIX. Es particularmente interesante que estos no destacan en cuanto a la media de la longitud de sus oraciones. Esto apunta al menos a una forma en que los discursos del Estado de la Unión han cambiado adaptándose a lo largo del tiempo.
Para ver el patrón de forma más explícita, es posible añadir una línea de tendencia sobre el diagrama con la función geom_smooth (geometrización suave).
qplot(metadatos$year, media_longitud_oraciones) + geom_smooth() + labs(x = "Año", y = "Longitud media de las oraciones")
Longitud media de cada discurso del Estado de la Unión con una línea de tendencia
Las líneas de tendencia son un gran añadido a los gráficos. Tienen la doble función de mostrar la corriente general de los datos en el tiempo mientras destaca puntos de datos atípicos o periféricos.
Resumen de documento
Como última tarea vamos a aplicar la función de resumen simple que hemos usado en la sección previa a cada uno de los documentos en este corpus más amplio. Necesitamos usar un bucle otra vez, pero el código interior sigue siendo casi el mismo a excepción de que vamos a guardar los resultados como un elemento del vector descripcion.
descripcion <- c()
for (i in 1:length(palabras)) {
tabla <- table(palabras[[i]])
tabla <- data_frame(word = names(tabla), count = as.numeric(tabla))
tabla <- arrange(tabla, desc(count))
tabla <- inner_join(tabla, palabras_frecuentes)
tabla <- filter(tabla, frequency < 0.002)
resultado <- c(metadatos$president[i], metadatos$year[i], tabla$word[1:5])
descripcion <- c(descripcion, paste(resultado, collapse = "; "))
}
Mientras se procesa cada archivo como resultado de la función inner_join, verás una línea que dice Joining, by = “word”. Como el bucle puede tardar uno o más minutos en procesar la función, dicha línea sirve para asegurarse de que el código está procesando los archivos. Podemos ver el resultado del bucle escribiendo descripcion en la consola, pero con la función cat obtenemos una vista más clara de los resultados.
cat(descripcion, sep = "\n")
Los resultados ofrecen una línea por cada discurso del Estado de la Unión. Aquí, por ejemplo, están las líneas de las presidencias de Bill Clinton, George W. Bush y Barack Obama:
>William J. Clinton; 1993; deficit; propose; incomes; invest; decade
William J. Clinton; 1994; deficit; renew; ought; brady; cannot
William J. Clinton; 1995; ought; covenant; deficit; bureaucracy; voted
William J. Clinton; 1996; bipartisan; gangs; medicare; deficit; harder
William J. Clinton; 1997; bipartisan; cannot; balanced; nato; immigrants
William J. Clinton; 1998; bipartisan; deficit; propose; bosnia; millennium
William J. Clinton; 1999; medicare; propose; surplus; balanced; bipartisan
William J. Clinton; 2000; propose; laughter; medicare; bipartisan; prosperity
George W. Bush; 2001; medicare; courage; surplus; josefina; laughter
George W. Bush; 2002; terrorist; terrorists; allies; camps; homeland
George W. Bush; 2003; hussein; saddam; inspectors; qaida; terrorists
George W. Bush; 2004; terrorists; propose; medicare; seniors; killers
George W. Bush; 2005; terrorists; iraqis; reforms; decades; generations
George W. Bush; 2006; hopeful; offensive; retreat; terrorists; terrorist
George W. Bush; 2007; terrorists; qaida; extremists; struggle; baghdad
George W. Bush; 2008; terrorists; empower; qaida; extremists; deny
Barack Obama; 2009; deficit; afford; cannot; lending; invest
Barack Obama; 2010; deficit; laughter; afford; decade; decades
Barack Obama; 2011; deficit; republicans; democrats; laughter; afghan
Barack Obama; 2012; afford; deficit; tuition; cannot; doubling
Barack Obama; 2013; deficit; deserve; stronger; bipartisan; medicare
Barack Obama; 2014; cory; laughter; decades; diplomacy; invest
Barack Obama; 2015; laughter; childcare; democrats; rebekah; republicans
Barack Obama; 2016; laughter; voices; allies; harder; qaida
Como ya habíamos señalado, estos resúmenes temáticos no reemplazan de ninguna manera la lectura atenta de cada documento. Sin embargo, sirven como un resumen de nivel general de cada presidencia. Vemos, por ejemplo, el enfoque inicial en el déficit durante los primeros años de la presidencia de Bill Clinton, su cambio hacia el bipartidismo cuando la Cámara y el Senado se inclinaron hacia los Republicanos en la mitad de los 90 y un cambio hacia una reforma en Medicare al final de su presidencia. Los discursos de George W. Bush se central principalmente en terrorismo, con la excepción del discurso de 2001, ofrecido antes de los ataques terroristas del 11 de Septiembre. Barack Obama volvió a preocuparse por la economía bajo la sombra de la recesión de 2008. La palabra “risa” (laughter) aparece con frecuencia porque se añade a las transcripciones cuando la risa de la audiencia hizo que el emisor tuviera que hacer una pausa.
Siguientes pasos
En este tutorial breve hemos explorado algunas formas básicas para analizar datos textuales con el lenguaje de programación R. Existen varias direcciones que puedes tomar para adentrarte más en las nuevas técnicas del análisis de texto. Estos son tres ejemplos particularmente interesantes:
- procesar un flujo completo de anotación de procesamiento de lenguajes naturales (NLP) en un texto para extraer características como nombres de entidades, categorías gramaticales y relaciones de dependencia. Estos están disponibles en varios paquetes de R, incluyendo cleanNLP, y para varios idiomas12.
- ajustar modelos temáticos (topic models) para detectar discursos particulares en el corpus usando paquetes como mallet13 y topicmodels14.
- aplicar técnicas de reducción dimensional para crear gráficos de tendencias estilísticas a lo largo del tiempo o entre múltiples autores. Por ejemplo, el paquete tsne15 realiza una forma poderosa de reducción dimensional particularmente apta para gráficos detallados.
Existen muchos tutoriales genéricos para estos tres ejemplos, además de documentación detallada de los paquetes16. Esperamos ofrecer tutoriales enfocados en aplicaciones históricas en particular en el futuro.
Notas
-
Nuestro corpus contiene 236 discursos del Estado de la Unión. Dependiendo de lo que se cuente, este número puede ser ligeramente más alto o más bajo. ↩
-
Dewar, Taryn. “Datos tabulares en R”, traducido por Jennifer Isasi, The Programming Historian en español 3 (2018), https://programminghistorian.org/es/lecciones/datos-tabulares-en-r. ↩
-
Hadley Wickham. “tidyverse: Easily Install and Load ‘Tidyverse’ Packages”. R Package, Version 1.1.1. https://cran.r-project.org/web/packages/tidyverse/index.html ↩
-
Lincoln Mullen and Dmitriy Selivanov. “tokenizers: A Consistent Interface to Tokenize Natural Language Text Convert”. R Package, Version 0.1.4. https://cran.r-project.org/web/packages/tokenizers/index.html ↩
-
Ten en cuenta que los nombres de las funciones como
libraryoinstall.packagessiempre estarán en inglés. No obstante, se proporciona una traducción de su significado para facilitar la comprensión y se traducen el nombre de las variables.[N. de la T.] ↩ -
Traducción publicada en CNN en español (12 de enero de 2016) http://cnnespanol.cnn.com/2016/01/12/discurso-completo-de-obama-sobre-el-estado-de-la-union/ [N. de la T.] ↩
-
Todos los discursos presidenciales del Estado de la Unión fueron descargados de The American Presidency Project at the University of California Santa Barbara (Accedido el 11 de noviembre de 2016) http://www.presidency.ucsb.edu/sou.php ↩
-
Aquí volvemos a la versión del discurso en su original (inglés) por motivos de continuación del análisis y, en particular, el listado de las palabras más frecuentes usadas en inglés. Seguimos traduciendo los nombres de las variables y de las funciones para facilitar la comprensión en español.[N. de la T.] ↩
-
Aquí optamos por nombrar a las columnas de la tabla en inglés, como “word” (palabra) y “count” (recuento), para facilitar su interoperabilidad con el conjunto de datos que introducimos más adelante con la función
inner_joinde más adelante. [N. de la T.] ↩ -
Peter Norvig. “Google Web Trillion Word Corpus”. (Accedido el 11 de noviembre de 2016) http://norvig.com/ngrams/. ↩
-
Esto ocurre en algunos discursos escritos del Estado de la Unión, donde una lista con puntos de enumeración es segmentada como una única oración larga. ↩
-
Taylor Arnold. “cleanNLP: A Tidy Data Model for Natural Language Processing”. R Package, Version 0.24. https://cran.r-project.org/web/packages/cleanNLP/index.html ↩
-
David Mimno. “mallet: A wrapper around the Java machine learning tool MALLET”. R Package, Version 1.0. https://cran.r-project.org/web/packages/mallet/index.html ↩
-
Bettina Grün and Kurt Hornik. “https://cran.r-project.org/web/packages/topicmodels/index.html”. R Package, Version 0.2-4. https://cran.r-project.org/web/packages/topicmodels/index.html ↩
-
Ver el artículo t-distributed stochastic neighbor embedding (en inglés) en Wikipedia. https://en.wikipedia.org/wiki/T-distributed_stochastic_neighbor_embedding [N. de la T.] ↩
-
Ver, por ejemplo, el libro de los autores: Taylor Arnold and Lauren Tilton. Humanities Data in R: Exploring Networks, Geospatial Data, Images, and Text. Springer, 2015. ↩