Contenidos
- Prerrequisitos
- ¿Qué es el rascado web o web scraping?
- Poder/deber
- Ejercicio práctico: extraer el texto contenido en un sitio web
- Repetir el proceso para el segundo discurso
- Síntesis
- Próximos pasos
- Notas
En esta lección introduciremos la técnica de adquisición de datos conocida como rascado web o web scraping, la cual nos permite extraer contenido publicado en una página web. Al tratarse de la primera lección de una serie sobre este tema, introduciremos algunos conceptos que son relevantes para aplicar mejor este procedimiento, así como el paso a paso para implementarlo.
Los objetivos de aprendizaje de esta primera lección son:
-
Conocer los elementos básicos de la estructura de un sitio web necesarios para extraer su contenido
-
Comprender qué es lo que caracteriza al web scraping ético
-
Aplicar estrategias para extraer desde una página web datos que estén en formato de bloque de texto
Este tutorial se divide en tres secciones. En la primera, revisaremos algunas de las características generales de una página web que es relevante conocer cuando hacemos web scraping. En la segunda, discutiremos algunas consideraciones respecto de la dimensión ética de esta técnica, es decir, cómo podemos determinar no solo si es viable extraer los datos de una página, sino también si es algo que podemos hacer y qué condiciones debemos respetar. En la tercera, haremos un primer ejercicio de extracción que nos permitirá conocer el flujo de trabajo habitual en la aplicación de este tipo de técnica. Para ello, extraeremos de la página oficial de la presidencia de Chile los discursos de asunción al cargo de los dos últimos presidentes de ese país.
Prerrequisitos
En esta lección mostraremos cómo hacer web scraping usando R. Las explicaciones que daremos asumen que ya tienes cierto grado de familiaridad con este lenguaje de programación. Por ejemplo, sabes cómo ejecutar el código, cómo instalar y activar paquetes, y cómo guardar un script y un archivo con datos en tu directorio de trabajo. Si no has utilizado R antes, te sugerimos revisar primero los tutoriales Datos tabulares en R y Administración de datos en R, que te permitirán adquirir la base necesaria.
Para poder completar los distintos pasos que ilustraremos necesitarás:
- Al menos la versión 4.1 de R, ya que utilizaremos el operador pipe de R base (
|>) que está disponible desde mayo de 2021. Puedes ejecutarR.versionpara revisar cuál es la versión que tienes instalada (o fijarte en el mensaje que se imprime en la consola cuando inicias R). De todos modos, deberías obtener los mismos resultados si utilizas el pipe del paquete magrittr (%>%) - Los paquetes rvest, stringr y readr
Si bien no es necesario utilizar RStudio para completar la lección, las capturas de pantalla que se incluyen provienen de ese programa. Algo similar ocurre respecto del navegador. Si bien puedes usar cualquiera, para las capturas de pantalla se utilizó Firefox.
Los datos que extraeremos los guardaremos en una carpeta llamada “discursos”, por lo que es necesario que la crees en tu directorio de trabajo (por ejemplo, con la función dir.create("discursos")).
¿Qué es el rascado web o web scraping?
Web scraping es una técnica que nos permite extraer datos publicados en un sitio web. A través de ella “rascamos” el código html de una página para obtener aquellas secciones que nos interesan, por ejemplo, tablas, párrafos con texto, enlaces, imágenes, etc.
Para poder entender mejor cómo funciona este procedimiento, es necesario que revisemos algunos aspectos básicos acerca de cómo está construida una página web. Ten en cuenta que esta será una explicación simplificada, que busca destacar solo aquellos elementos que resultan relevantes cuando hacemos web scraping. Si ya tienes claro qué es un elemento html, una clase o un id, quizás prefieras saltarte esta sección y pasar a la siguiente.
Una página web = archivo de texto etiquetado
Una página web es un archivo de texto plano que utiliza la extensión .html. Al contenido de ese archivo se le agregan ciertas etiquetas para indicar a qué corresponde cada uno de sus elementos, lo que permite darle la estructura necesaria para que se visualice correctamente en un navegador.
Para ilustrar esta idea, revisemos el siguiente ejemplo de código html:
<h1>Este es el título más grande</h1>
<p>Este es un párrafo que dice cosas muy muy interesantes. Es un poco breve, pero sirve para ilustrar que todas estas palabras conforman un párrafo.</p>
<h2>Este es un título un poco más pequeño</h2>
<ol>
<li>Un primer elemento</li>
<li>Un segundo elemento</li>
<li>Un tercer elemento</li>
</ol>
<h2>Este título es del mismo tamaño que el anterior</h2>
<p>Este es el inicio de otro párrafo que podría ser muy interesante también.</p>
En el ejemplo anterior, el contenido está delimitado por distintos tipos de etiquetas. Por ejemplo, en la primera línea el texto “Este es el título más grande” está rodeado de etiquetas que indican el inicio (<h1>) y el término (</h1>) de un encabezado (header) de nivel 1 (el más grande posible). Tenemos también otras etiquetas:
<h2> ... </h2>para títulos de nivel 2 (que son un poco más pequeños que los de nivel 1)<p> ... </p>para párrafos-
<ol> ... </ol>para una lista ordenada en que cada uno de sus elementos está a su vez etiquetado con<li> ... </li>Este conjunto de etiquetas permite que al abrir el documento en un navegador, este interprete el contenido de lo que está entre las etiquetas como un elemento con ciertas características, tal como se observa en la siguiente imagen. Si quieres probar cómo funciona, puedes guardar el bloque de código en un archivo de texto, cambiarle la extensión por .html y luego abrirlo en tu navegador.
Visualización del documento html en el navegador
Las etiquetas que hemos agregado permiten, por ejemplo, que lo que está etiquetado como h1 se vea más grande que lo que está como h2 y que nuestra lista esté numerada. Como se observa en la imagen anterior, todas estas etiquetas nos permiten definir la estructura del contenido de nuestro documento html. Pero ¿qué pasa con el estilo? ¿Cómo se indica, por ejemplo, que lo que está etiquetado como h1 debe tener una determinada fuente tipográfica o un tamaño y color particular? Todo eso podemos indicarlo con las hojas de estilo en cascada, conocidas como CSS por sus siglas en inglés (Cascading Style Sheets). A través de ellas definimos las reglas de estilo que hay que aplicar a cada elemento de nuestro documento html.
No profundizaremos acá acerca de cómo y dónde se escriben y aplican estas reglas, sino que solo nos referiremos a aquellos aspectos que inciden cuando hacemos web scraping. El más importante es que podemos crear “clases”. Para explicar qué es una clase, volvamos a nuestro ejemplo anterior. En él tenemos dos encabezados de nivel 2 (<h2>). Si queremos que ambos se vean igual, bastaría con indicar en nuestro archivo CSS las características que deben tener todos los encabezados h2. ¿Pero qué pasa si no queremos que sean todos iguales? Por ejemplo, como el primero es el encabezado de una lista, podríamos querer que algo en su formato sea distinto. Para distinguir ambos encabezados h2 lo que podemos hacer es asignarle una clase distinta a cada uno y luego definir las características de cada clase en nuestra hoja de estilo. Eso nos permitiría, por ejemplo, hacer que los encabezados de una lista tengan una fuente tipográfica distinta a los que encabezan un párrafo. Para asignar la clase de un determinado elemento, lo que hacemos es agregar class="nombre-de-la-clase" dentro de la etiqueta de inicio, tal como se muestra en esta versión actualizada de nuestro ejemplo:
<h1>Este es el título más grande</h1>
<p>Este es un párrafo que dice cosas muy muy interesantes. Es un poco breve, pero sirve para ilustrar que todas estas palabras conforman un párrafo.</p>
<h2 class="encabezado-lista">Este es un título un poco más pequeño</h2>
<ol>
<li>Un primer elemento</li>
<li>Un segundo elemento</li>
<li>Un tercer elemento</li>
</ol>
<h2 class="encabezado-parrafo">Este título es del mismo tamaño que el anterior</h2>
<p>Este es el inicio de otro párrafo que podría ser muy interesante también.</p>
Ahora, cada uno de los encabezados de nivel 2 corresponde a una clase diferente, lo que nos permite distinguirlos. A diferencia de las etiquetas html, que son una lista cerrada, el nombre de la clase es algo que define quien crea el sitio web.
¿Por qué es relevante entender qué son los elementos y las clases? Cuando hacemos web scraping lo que hacemos es importar el código html de un sitio web a nuestro computador (usando R, por ejemplo) y extraer aquellas partes específicas que nos interesan. Como el contenido de un archivo html se encuentra etiquetado, podemos utilizar esas mismas etiquetas para especificar cuáles son las partes de la página que nos interesa extraer. Por esa razón, entender la diferencia entre un “elemento” del documento html y una “clase” nos va a permitir precisar mejor cuál es el contenido exacto que queremos de una página. Si en nuestro ejemplo anterior quisiéramos extraer todos los encabezados de nivel 2, bastaría con indicar que queremos todo el contenido etiquetado como <h2>. Pero si solo nos interesan los encabezados <h2> de las secciones que corresponden a una lista, entonces saber que su clase es "encabezado-lista" nos permitirá seleccionar solo esa parte del contenido y no los h2 de la clase "encabezado-parrafo". Es decir, podemos hacer una búsqueda y extracción más precisa.
Además de los elementos y las clases, existen los id, que son la forma que tenemos de identificar de manera única un elemento dentro de un documento html. A diferencia de las clases, que se pueden aplicar a más de una instancia de un mismo elemento (por ejemplo, todos los encabezados <h2>), un id puede ser utilizado una sola vez por documento.
Hay varias razones por las que se utilizan. Por ejemplo, cumplen una función importante cuando el sitio web utiliza JavaScript (un tema que excede los objetivos de esta lección). Pero quizás una de las más conocidas es que nos permiten crear marcadores (bookmarks) que sirven para que quien lea la página pueda saltar a una parte específica de la misma. Por ejemplo, si revisas la página “Acerca de” en el sitio web de Programming Historian, verás que al pasar el cursor por sobre los subtítulos de la página aparece un símbolo de enlace a la derecha, tal como se muestra en la siguiente imagen:

Cuando pasamos el cursor sobre alguno de los subtítulos en la página de Programming Historian aparece un ícono de enlace a la derecha
Eso ocurre porque cada subtítulo tiene asignado un id, que identifica de forma única esa sección de la página. Si revisamos el enlace asociado veremos que a la url base de la página (https://programminghistorian.org/es/acerca-de) se le agrega un # y el nombre del id (que coincide en este caso con el nombre del subtítulo): https://programminghistorian.org/es/acerca-de#revisión-por-pares. Esto sirve, por ejemplo, para crear un índice de contenido en la página que permita a sus visitantes acceder a secciones específicas. Y también si queremos compartir un enlace a una sección particular de una página web.
El hecho de que los id solo se puedan utilizar una vez es muy útil cuando hacemos web scraping, porque si los datos que queremos están etiquetados con un id, cuando tratemos de recuperarlos usando R u otra herramienta tendremos seguridad de que obtendremos exactamente el elemento específico que nos interesa.
A modo de resumen de esta primera sección, podemos decir que una página web es un documento de texto plano con extensión .html, en que su contenido se encuentra etiquetado. Estas etiquetas sirven para distinguir elementos, clases y, en algunos casos, el id de sus distintos componentes. Cuando hacemos web scraping, esas etiquetas nos servirán para seleccionar el contenido exacto que nos interesa extraer de una página.
Poder/deber
Ahora que ya tenemos una idea general de cómo está compuesto un archivo html y sus implicancias a la hora de hacer web scraping, podríamos empezar con un primer ejercicio de extracción. Sin embargo, es importante que discutamos brevemente las cuestiones éticas del uso de esta técnica. ¿Qué quiere decir esto? Que cuando queremos extraer contenido de un sitio web no solo tenemos que preguntarnos si es viable hacerlo (en términos de si tenemos el conocimiento y herramientas necesarias), sino también si podemos o debemos extraer esos datos. Esta pregunta supone averiguar dos cosas:
- Si los datos tienen alguna restricción de uso, producto de la licencia con que han sido publicados
- Cómo el sitio web espera que interactuemos con él (sobre todo si lo haremos a través de un medio automatizado, como el web scraping)
¿Cómo podemos averiguar esto? Usualmente esta información se encuentra en la sección relativa a las condiciones de uso del sitio web. Además, existe un archivo llamado robots.txt que nos entrega pistas adicionales sobre cómo interactuar con el sitio. A continuación explicaremos cómo obtener esta información y cómo interpretarla.
Revisar los términos o condiciones de uso
La mayoría de los sitios web incluyen una sección en la que se indica cuáles son los términos o condiciones de uso. Usualmente esa información la encontramos en la parte inferior de la página, ya sea porque hay un mensaje que explícitamente dice lo que podemos hacer con el sitio, o bien, porque hay un enlace que nos lleva a un documento más detallado. Por ejemplo, si vas a la parte inferior de cualquier página de Programming Historian, encontrarás el siguiente mensaje: “Programming Historian en español (ISSN: 2517-5769) se publica con una licencia CC-BY”.
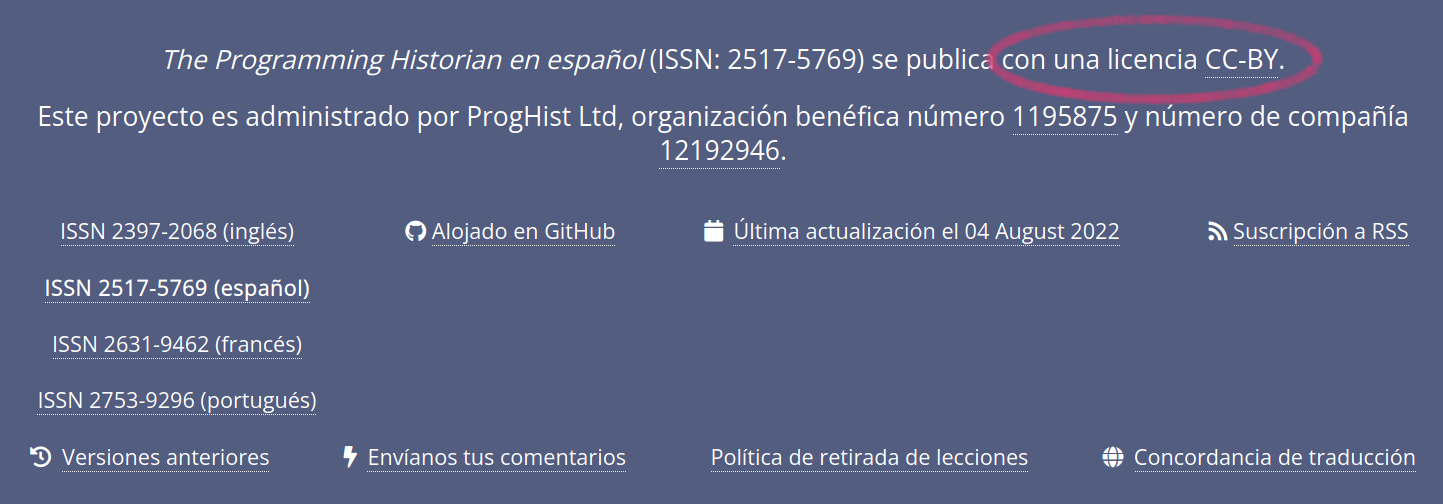
Declaración sobre la licencia de publicación del contenido de Programming Historian
En este caso, la explicitación de la licencia utilizada nos permite saber que podemos compartir y adaptar el material publicado, siempre que se sigan los términos de atribución que este tipo de licencia exige. En otros casos, en particular cuando se trata de sitios web cuyo contenido no está pensado para ser compartido, nos encontraremos con una explicación más larga y detallada de lo que se puede y no puede hacer. Por ejemplo, un sitio web que es muy explícito respecto de esto es Amazon. Si vas hasta la parte de más abajo de su página de inicio, encontrarás un enlace a las condiciones de uso. En esa sección se describen de forma extensa los términos de uso del sitio. ¿Cómo encontrar la información que nos interesa cuando la sección es así de larga? Algo que usualmente resulta útil es buscar palabras como “robot”, “extracción”, “extraer” o “automático/a”. En este caso, esa búsqueda nos llevará al siguiente párrafo:
“No está permitida la extracción sistemática ni la reutilización de parte alguna del contenido de ninguno de los servicios de Amazon sin nuestro expreso consentimiento por escrito. En particular, no se permite el uso de herramientas o robots de búsqueda y extracción de datos para la extracción (ya sea en una o varias ocasiones) de partes sustanciales de los servicios de Amazon para su reutilización sin nuestro expreso consentimiento por escrito. Tampoco le está permitido al usuario crear ni publicar sus propias bases de datos cuando éstas contengan partes sustanciales de cualquiera de los servicios de Amazon (por ejemplo, nuestras listas de productos y listas de precios) sin nuestro expreso consentimiento por escrito.1”
Es decir:
- Necesitamos la autorización de Amazon por escrito para extraer o reutilizar el contenido de su sitio web
- No está permitido utilizar herramientas de extracción de datos (¡como el web scraping!)
- No está permitido crear una base de datos a partir del contenido extraído de este sitio web
Por lo tanto, según lo que el propio sitio nos indica, por mucho que sepamos cómo extraer los datos de él, no es algo que debiésemos hacer si queremos respetar los términos de uso que la empresa ha definido.
Revisar el archivo robots.txt
Existe otro lugar en el que podemos encontrar información sobre cómo interactuar con un sitio web: el archivo robots.txt. Este archivo explicita algo que se conoce como “protocolo de exclusión de robots”, es decir, en él se dan instrucciones de qué puede y no puede hacer un mecanismo automatizado de extracción de datos al interactuar con ese sitio en particular. Lamentablemente no todos los sitios web lo incluyen, por lo que no siempre encontraremos esta información disponible.
Este archivo está pensado principalmente para robots que hacen extracciones masivas del contenido de algunas páginas. Sin embargo, en él encontraremos información relevante para tareas más discretas, como las que realizaremos en esta serie de lecciones.
El documento robots.txt se encuentra en el directorio raíz de un sitio web, por lo tanto, en caso de estar disponible, podemos acceder a su contenido agregando “robots.txt” luego de la url principal. Por ejemplo, si quisiéramos revisar la versión de este archivo del sitio web del proyecto Memoria Chilena de la Biblioteca Nacional de Chile, tendríamos que escribir: http://www.memoriachilena.gob.cl/robots.txt. Eso nos llevará a una página con el siguiente contenido:
User-agent: *
Allow: /
Disallow: /*/alt-*.html
Disallow: /*/aux-*.html
Crawl-Delay: 2
¿Qué significa este mensaje? Revisemos cada línea:
User-agent: *: Indica a quién se aplican estas instrucciones. A veces aparece el nombre de algún robot en particular. En este caso, el asterisco explicita que estas instrucciones aplican a todos.Allow: /: Indica cuáles son las rutas dentro del sitio desde las que es posible extraer datos. En este caso la barra/indica que es posible hacerlo de todas.Disallow: /*/alt-*.htmlyDisallow: /*/aux-*.htmlexplicitan aquellas rutas dentro del sitio web desde las que no se da autorización para hacer una extracción de forma automatizada. En este caso, son todas aquellas páginas cuya url incluyealt-oaux-. Es decir, acá se está poniendo una restricción a la autorización general que nos dieron en la línea anterior.Crawl-Delay: 2: Explicita la cantidad de segundos que es necesario esperar entre cada petición (request) de datos al sitio. Esto es importante tenerlo en cuenta cuando extraemos datos de varias páginas dentro de un sitio web al mismo tiempo, ya que esos segundos de espera permiten que el funcionamiento del sitio no se vea afectado. Por el momento no es algo que necesitemos tener en consideración para esta lección en particular, pero sí será relevante en la tercera parte de esta serie.
Como señalamos anteriormente, es importante tener en cuenta que no todos los sitios web tienen un archivo robots.txt o una sección específica sobre cuáles son las condiciones de uso. A veces este tipo de información está contenida dentro de otras secciones (por ejemplo, “Preguntas frecuentes” o “Acerca de”) y en otras simplemente no se menciona nada. En esos casos tendrás que aplicar tu criterio y evaluar qué es lo más adecuado.
Ejercicio práctico: extraer el texto contenido en un sitio web
Ahora que tenemos clara la forma de funcionamiento de un sitio web y cómo averiguar de qué forma podemos interactuar con él, haremos un primer ejercicio de extracción de datos. En él mostraremos cómo extraer texto contenido en una página. Este método resulta particularmente útil cuando, por ejemplo, necesitamos compilar un corpus de textos disponibles en línea. En esta ocasión, usaremos como ejemplos los discursos de asunción de los dos últimos presidentes de Chile. Los discursos que extraeremos se encuentran disponibles en la página de prensa de la presidencia Chile. Este podría ser el paso inicial para compilar, por ejemplo, un corpus de discursos de asunción al cargo que posteriormente podríamos analizar con alguna técnica de minería de textos. Veamos ahora el paso a paso para realizar la extracción.
Paso 1. Revisar los términos de uso del sitio web
Si revisamos la parte inferior del sitio web, encontraremos un mensaje en el que se señala de forma explícita que podemos utilizar los contenidos publicados ahí.

Declaración de la licencia con que se publican los contenidos en el sitio web de prensa de la Presidencia de Chile
Como en esta ocasión haremos solo una “llamada” al sitio web, no es necesario preocuparnos por los tiempos de espera (crawl delay) que podrían estar indicados en el archivo robots.txt (aunque en este caso en particular el sitio no contiene este archivo). Así que con la información de que los derechos están liberados, ya tenemos todo lo necesario para continuar con el siguiente paso.
Paso 2. Identificar la etiqueta que contiene los datos que nos interesan
Como veremos a lo largo de esta serie de lecciones, los pasos para hacer web scraping suelen ser los mismos siempre. Lo que varía cada vez es el elemento, la clase o el id en el que se encuentra el contenido queremos extraer de una determinada página. ¿Cómo podemos saber cuál es la etiqueta del contenido que nos interesa? Existen dos formas: la primera, utilizando las herramientas de desarrollo incluidas en el navegador; la segunda, utilizando alguna extensión para nuestro navegador que nos ayude con este propósito. En esta ocasión ilustraremos el primer método, ya que es el que resulta óptimo para el sitio web con el que trabajaremos.
Las herramientas de desarrollo del navegador
Tanto en Firefox como en Chrome se puede acceder a las herramientas de desarrollo utilizando el comando abreviado Ctrl + Shift + i (o Cmd + Shift + i si estás en Mac). Eso abrirá un panel que nos mostrará el código html de la página y las reglas de estilo (CSS). En el caso de Firefox el panel se encuentra en la parte inferior de la ventana (en Chrome lo verás al lado derecho). También puedes llegar a las herramientas de desarrollo utilizando el botón derecho del ratón (o Ctrl + hacer clic si usas Mac). En el menú que se despliega debes seleccionar la opción “Inspect” o “Inspeccionar”, que es la que abrirá el panel de desarrollo.
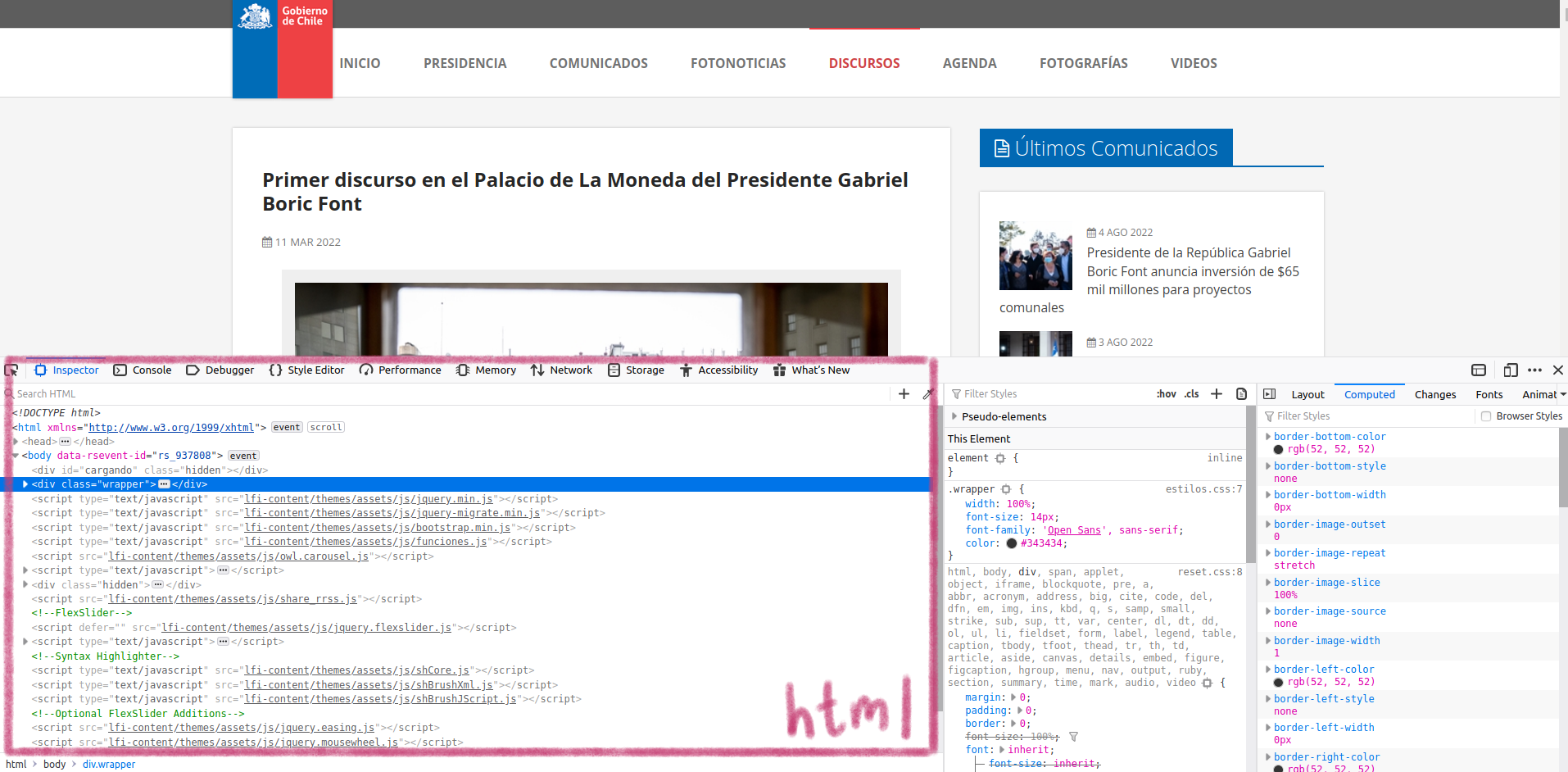
El panel de desarrollo en Firefox
En el caso de Firefox, lo que está al lado izquierdo del panel es el código html de la página. Si hacemos clic en las líneas que tienen una flecha al lado izquierdo, se irá desplegando el código de la página. Y si ponemos el cursor sobre alguna de las líneas de ese código, se destacará en la página la parte de la misma a la que corresponde esa línea en particular.
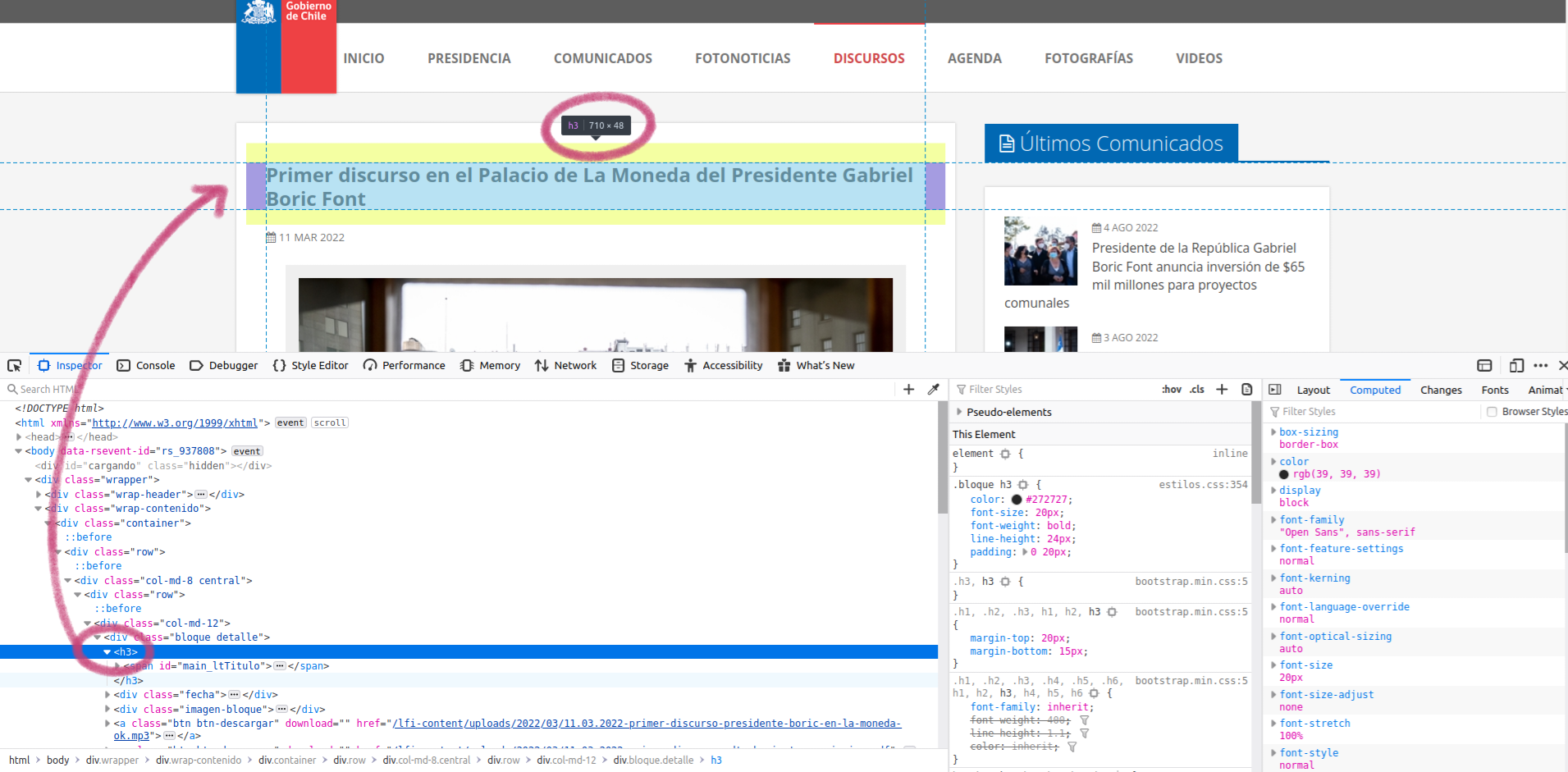
Cuando ponemos el cursor sobre alguna de las líneas de código en el panel de desarrollo se destaca la parte correspondiente en la página
Por ejemplo, en la captura de pantalla anterior, pusimos el cursor sobre la línea que decía h3 y eso destacó el titular de la nota que aparece ahí publicada.
También podemos hacerlo al revés (que suele ser la forma más útil), es decir, poner el cursor sobre algún elemento de la página para que el navegador nos muestre a qué parte del código corresponde ese fragmento en particular. Hay dos maneras de hacer esto. Si ya tienes abierto el panel con las herramientas de desarrollo, como en nuestro caso, puedes hacer clic en la esquina superior izquierda de ese panel, en el símbolo que tiene un cursor. Al hacerle clic cambiará de color a azul para indicar que está activa esa opción. Si no tienes abierto el panel, puedes utilizar el comando abreviado Ctrl/Cmd + Shift + C, que abrirá las herramientas del navegador con esa opción ya activa.
Cuando la opción de seleccionar un elemento de la página se activa cambia de color
Esta opción te permitirá mover el cursor por la página para que se destaque en el panel la parte del código correspondiente. Además, al igual que en el caso anterior, se desplegará un recuadro con información sobre el elemento. Por ejemplo, si movemos el cursor hacia el nombre de la página en la parte superior, veremos que el recuadro nos indica que corresponde a img.full. En este caso, img indica el elemento html al que correponde esta parte de la página (una imagen) y .full nos indica la clase a la que corresponde. Si miramos el panel veremos que la línea destacada es: <img src="lfi-content/themes/assets/img/logo_prensa.png" class="full">. En ella se indica que es un elemento de tipo imagen, el lugar donde se encuentra alojada esa imagen en el directorio de la página y el nombre de la clase que describe las reglas de estilo con que esa imagen debe mostrarse.
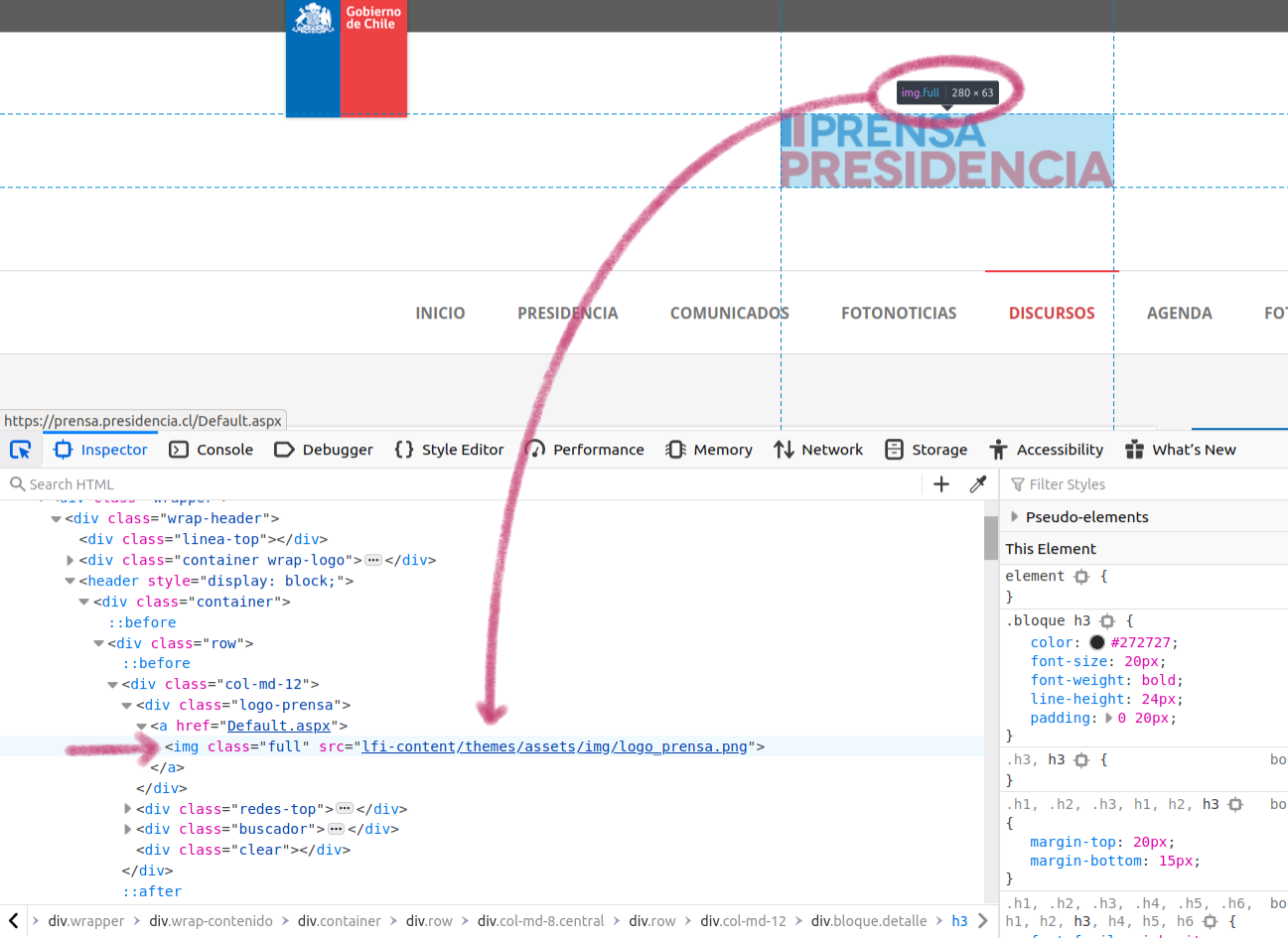
Cuando pasamos el cursor sobre alguna sección de la página se destaca en el panel de desarrollo la línea de código que le corresponde
Ahora que ya sabemos cómo funciona esa opción, busquemos la información sobre el elemento que contiene el texto del discurso, tal como se muestra en la siguiente captura de pantalla.
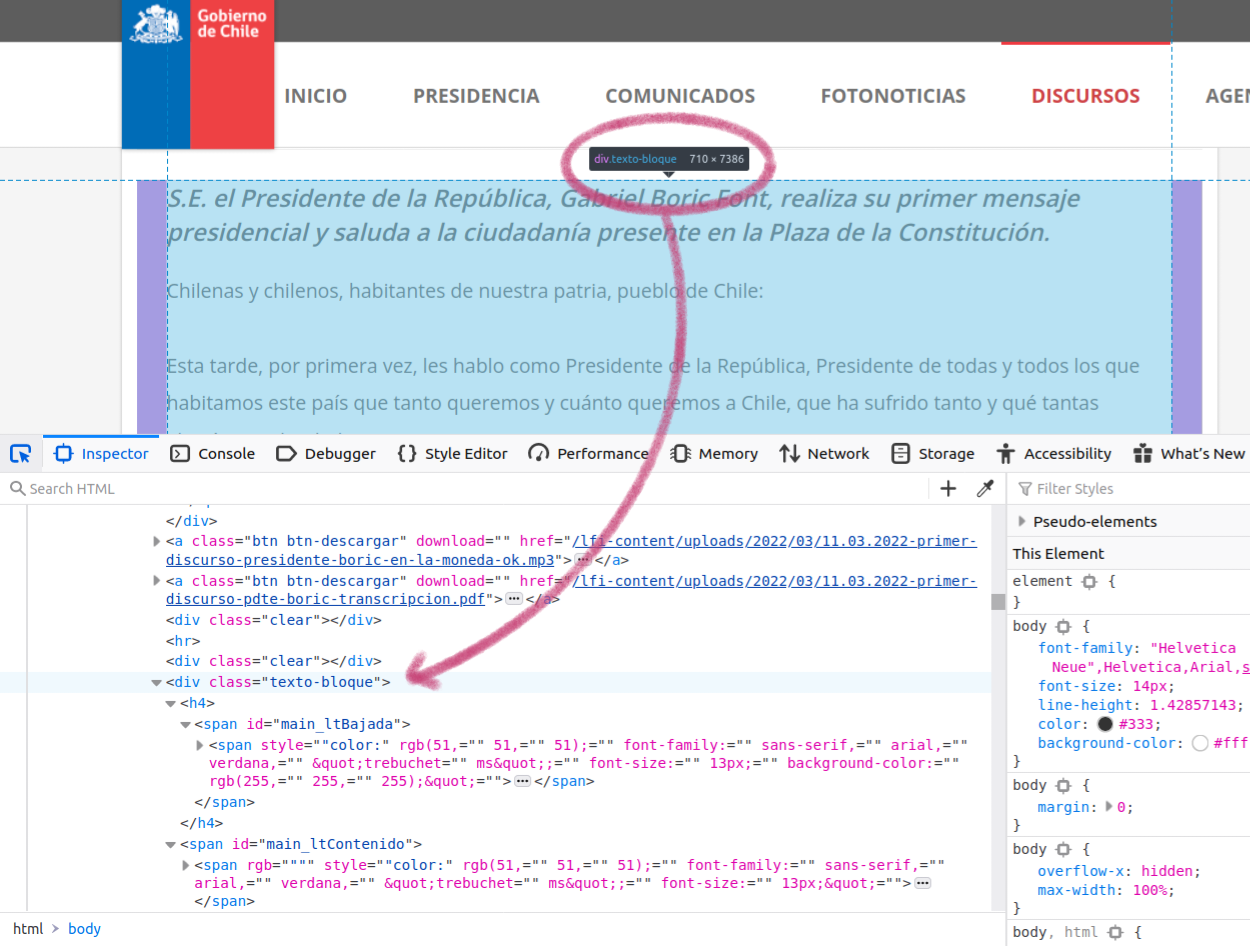
Al pasar el cursor sobre el discurso se destaca la línea correspondiente en el panel de desarrollo
Al poner el cursor sobre el discurso, vemos que el recuadro nos indica que corresponde a div.texto-bloque. En principio, pareciera que eso nos sirve. Sin embargo, si te fijas la clase “texto-bloque” no solo incluye el discurso, sino también las dos líneas anteriores que, técnicamente, no son parte de el. Es decir, no son parte de lo que Gabriel Boric dijo en ese momento, sino la presentación de lo que viene a continuación. Es importante eliminar esas dos oraciones en algún momento del proceso, ya que en el futuro podrían alterar los resultados de nuestro análisis. La primera opción sería revisar si existe algún otro elemento, clase o id que capture solo el discurso. Si eso no funciona, entonces tenemos que recordar eliminar manualmente esas líneas cuando procesemos los textos de nuestro corpus.
Busquemos primero si hay alguna etiqueta que contenga solo el discurso. Una opción es seguir moviendo el cursor para ver si en algún momento se destaca solo la parte que nos interesa. Si eso no resulta, como en este caso, entonces podemos revisar el código de la página con mayor detalle.
Si vamos al panel con el código, podemos empezar a explorar lo que está dentro del div de la clase “texto-bloque”, que es la que contenía el discurso y su presentación. Si movemos el cursor por sobre esas líneas, podemos ir revisando qué es lo que se destaca en cada una de ellas. Al llegar a la línea <span id="main_ltContenido"> se destaca solo el texto del discurso y en la página aparece un recuadro que confirma que la etiqueta de esa sección es span#main_ltContenido. A diferencia de las clases que se mostraban ahí con un punto antes del nombre, los id tienen un signo #.
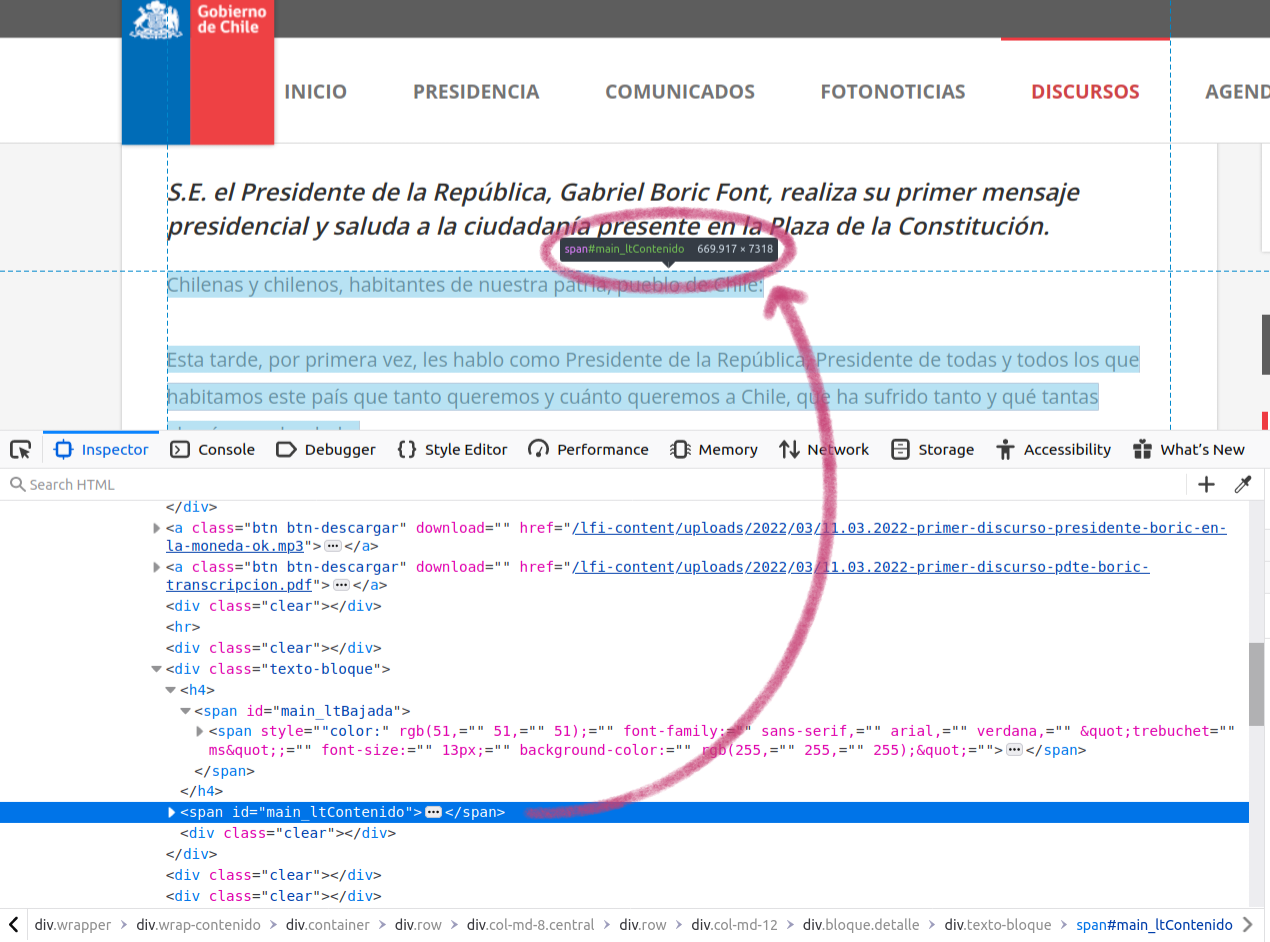
Al explorar las líneas de código encontramos la que corresponde solo al discurso
Ahora ya tenemos claro qué parte del código html es la que nos interesa (#main_ltContenido), así que podemos irnos a R a realizar el proceso de extracción.
Paso 3. Importar el código html a R y extraer los datos
Ahora que tenemos claro cómo está etiquetado el contenido de la página que nos interesa, usaremos R para hacer la extracción.
Lo primero que haremos será cargar los paquetes que utilizaremos en el proceso. Todos están disponibles en CRAN, por lo que se pueden instalar con la función install.packages():
library(rvest)
library(stringr)
library(readr)
- rvest es el paquete que nos sirve para importar el código html a R y extraer los elementos de la página que nos interesan
- stringr está enfocado en el manejo de cadenas de texto (conocidas en inglés como strings); nos servirá para hacer algunas modificaciones en el formato del texto
- readr se utiliza para importar y guardar archivos de texto plano (como csv y txt) y lo usaremos para guardar localmente en nuestro computador el resultado de nuestra extracción
Como mencionamos anteriormente, en este tutorial utilizaremos el operador pipe de R Base (|>). Si prefieres utilizar %>%, tendrías que cargar también el paquete magrittr o dplyr2.
Ahora que tenemos cargados los paquetes, importaremos el código html de la página que nos interesa y lo guardaremos en un objeto. Para ello, utilizaremos la función read_html() del paquete rvest:
html_boric <- read_html("https://prensa.presidencia.cl/discurso.aspx?id=188237")
El objeto html_boric contiene todo el código html de la página. Para seleccionar de su interior solo la parte que nos interesa (en este caso, el id “#main_ltContenido”) usamos la función html_element(). Si te fijas, cuando empezamos a escribir el nombre de esa función, RStudio nos ofrece dos opciones: html_element() y html_elements().
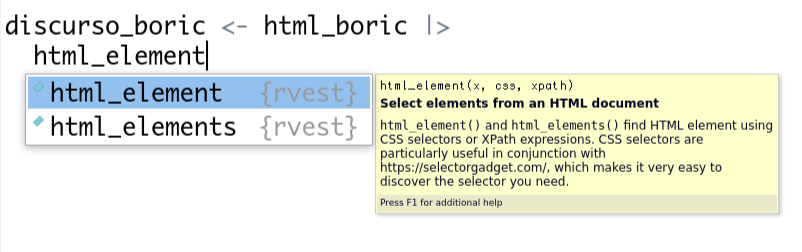
La opción de autocompletar de RStudio muestra que existe tanto html_element() como html_elements()
La diferencia está en si queremos capturar una o más instancias de un determinado elemento de la página. En esta ocasión, como nos interesa un id que solo aparece una vez, html_element() hará el trabajo que queremos. Pero si nos interesaran todas las ocurrencias de un elemento (por ejemplo, todos los encabezados <h2>), es muy importante que usemos la versión en plural (html_elements()) para extraerlos todos. De lo contrario, solo obtendremos su primera aparición.
Utilizaremos, entonces, html_element() para indicar el id que nos interesa y guardaremos el resultado en un nuevo objeto:
discurso_boric <- html_boric |>
html_element("#main_ltContenido")
Con esas líneas de código le estamos pidiendo a R que tome nuestro objeto html_boric y que extraiga de él el contenido etiquetado con el id #main_ltContenido. Si ejecutáramos nuestro código hasta este momento, lo que obtendríamos serían las líneas del código html etiquetadas con ese id. Es decir, el texto del discurso nos aparecería con todo el código html que permite darle estructura en la página. Si lo imprimiésemos en la consola, veríamos algo como esto:
> discurso_boric
{xml_nodeset (1)}
[1] <p align="justify" id="rslectura"><span rgb='""""""' style='"color:' font-family: sans ...
Para poder obtener solo el texto, necesitamos un paso más: indicarle a R en qué formato queremos el contenido. En este caso lo queremos como texto (si estuviésemos extrayendo una tabla, por ejemplo, nos interesaría que mantuviese la estructura de filas y columnas). Para lograr esto, agregaremos una función más a nuestro bloque de código: la función html_text(). Al escribir el nombre de la función, RStudio nos ofrecerá dos opciones: html_text() y html_text2().
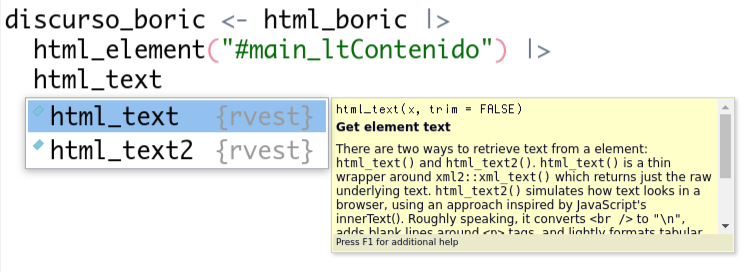
La opción de autocompletar de RStudio muestra que existe tanto html_text() como html_text2()
En el recuadro amarillo se ofrece una breve descripción de las diferencias. La principal es que html_text2() tratará de resolver algunas cosas de formato para que el texto se asemeje lo más posible a lo que se ve en la página. En este caso usaremos esa opción. Si usásemos la otra (html_text()) el texto nos quedaría como un solo párrafo (si quieres, puedes probar para ver qué es lo que ocurre). ¿Cuál nos conviene utilizar? La decisión va a depender de lo que nos interese hacer posteriormente con nuestro corpus. Si queremos mantener la estructura de párrafos, entonces nos convendría utilizar html_text2(). Incluso si no tenemos muy claro si los párrafos serán de utilidad para nuestro corpus en el futuro, es necesario tener en cuenta que si los descartamos ahora no hay manera de recuperarlos (tendrías que volver a extraer el texto de la página). En esta ocasión tomaremos la opción precavida y usaremos html_text2(). Agregaremos, entonces, esta función a nuestro bloque de código, que ahora queda así:
discurso_boric <- html_boric |>
html_elements("#main_ltContenido") |>
html_text2()
En la sección “Values” del panel “Environment” aparecerá ahora discurso_boric como un objeto tipo caracter. Si lo imprimes en la consola podrás chequear que el texto está completo.
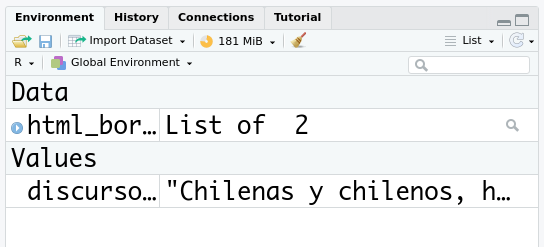
El objeto que creamos quedó en nuestro ambiente global
Ya tenemos el primer documento para nuestro corpus. Nuestro siguiente paso será guardarlo para un futuro uso.
Paso 4. Procesar y guardar los datos
Ahora que tenemos el primer texto, lo guardaremos localmente en nuestro computador. Para eso crearemos una carpeta llamada “discursos”. Puedes crearla como mejor te parezca: ejecutando dir.create("discursos") en la consola, usando la opción “+ Folder” de la esquina superior izquierda del panel Files de RStudio, o directamente en el explorador de archivos de tu computador.
Es importante detenerse un momento a pensar qué metadatados es necesario incluir en el nombre del archivo al guardarlo. Por ejemplo, al leer el nombre del archivo, sería relevante saber quién emitió ese discurso y cuándo: 2022_boric.txt. Pero si nuestro corpus eventualmente incluirá discursos de otros países, entonces necesitaríamos integrar esa variable en el nombre del archivo, por ejemplo, utilizando el código ISO 2 para nombres de países: cl_2022_boric.txt. Y si en algún momento quisiéramos incorporar otros tipos de discursos, habría que indicar de alguna forma que este archivo corresponde al que se emitió luego de asumir el cargo: cl_2022_boric_asuncion-cargo.txt. Si te fijas, usamos guiones bajos (_) para separar las cuatro variables incluidas en el nombre del archivo (país, año, presidente, tipo de discurso) y un guión para separar las palabras cuando una variable tenía más de una (“asuncion-cargo”). Es importar prestar atención a estos detalles, ya que en el futuro nos pueden ayudar a hacer más fácil el proceso de trabajo con nuestros datos.
En esta ocasión agregaremos esas cuatro variables a nuestro nombre de archivo: el código para guardar el discurso quedaría así:
write_lines(discurso_boric, "discursos/cl_2022_boric_asuncion-cargo.txt")
Esa línea de código le está pidiendo a R que escriba el contenido del objeto discurso_boric en un archivo txt dentro de la carpeta “discursos”.
¡Listo! Si abrimos la carpeta “discursos” en nuestro panel “Files” y hacemos doble clic sobre el nombre del archivo, se abrirá en una nueva pestaña en RStudio.
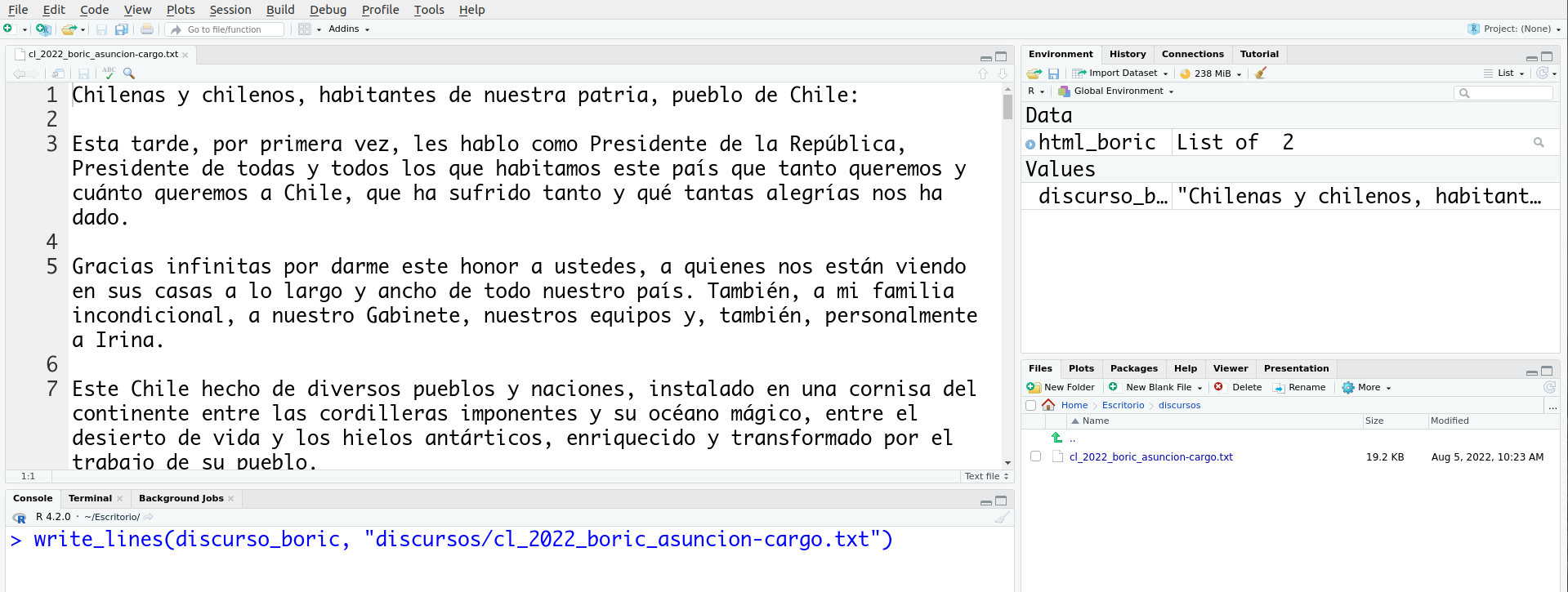
Así se ve el texto en el archivo que acabamos de guardar
Podemos observar que el texto tiene dos saltos de líneas entre los párrafos. Si bien eso no es un problema que afecte algún análisis posterior del texto, quizás podríamos querer que quedara solo un salto de línea entre los párrafos porque nos interesa hacer una edición digital de estos discursos en el que ese es el formato requerido. Para resolver esta situación, podemos usar el paquete stringr, que está enfocado en el trabajo con cadenas de textos. La función str_replace_all() (remplazar todo) nos permite buscar un patrón en una cadena de texto y remplazarlo por otro.
Para saber qué patrón buscar, imprimamos el objeto discurso_boric en la consola. Como es largo, lo primero que veremos será el final. Comparémoslo con la parte final del texto del archivo que tenemos en el panel superior.
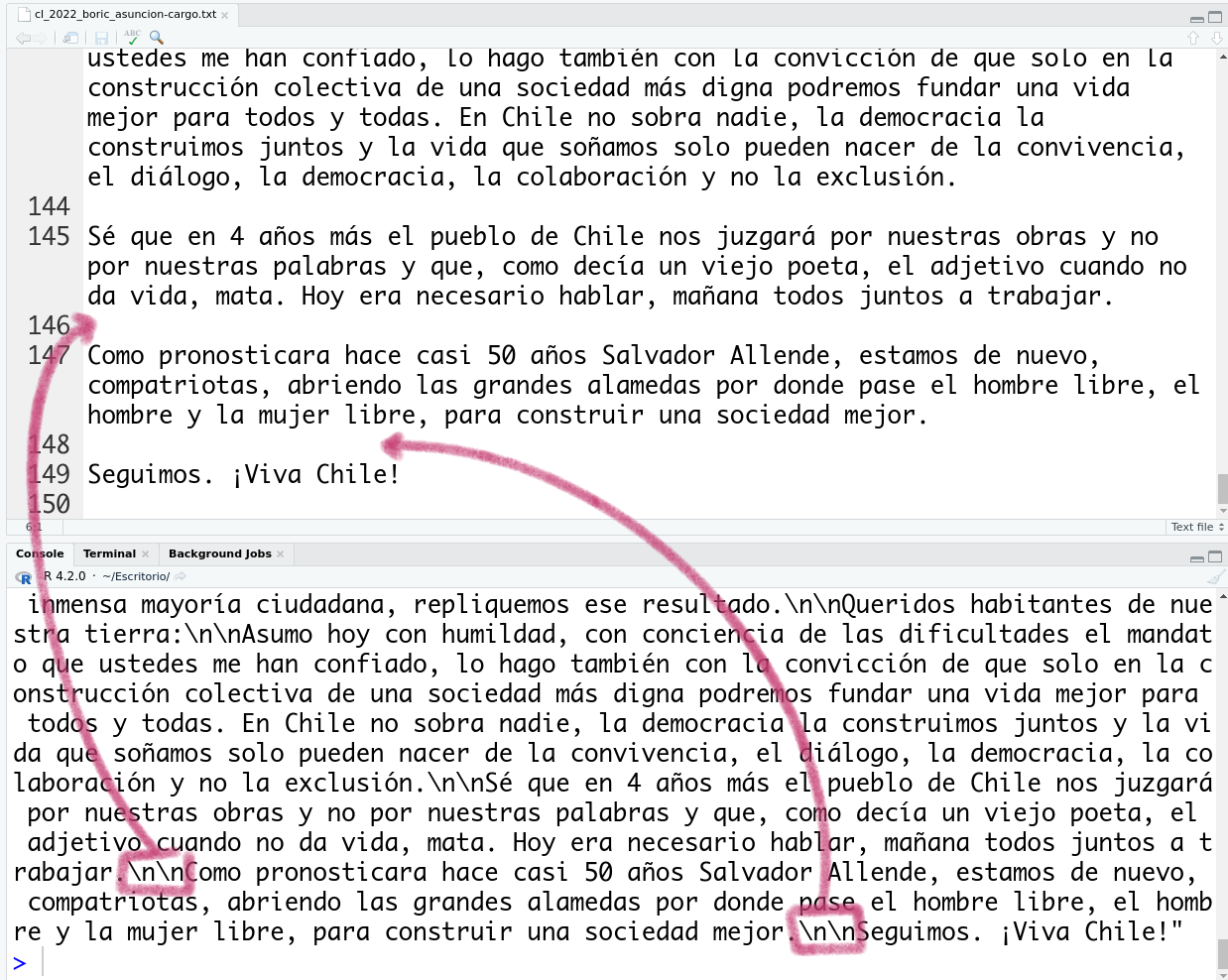
Comparación entre el texto en la cosola y el texto en el archivo
Si miramos el texto de la consola veremos que los saltos de líneas son representados en nuestro computador como \n. Esta es la forma que los sistemas operativos representan los saltos de línea y es la que se utiliza también en las expresiones regulares (un tema sobre el que volveremos en la segunda lección de esta serie). Como en nuestro caso hay dos saltos de línea seguidos, entonces lo que vemos es \n\n.
Lo que haremos ahora será pedirle a R que con la función str_replace_all() busque en nuestro objeto discurso_boric el patrón “\n\n” (dos saltos de línea seguidos) y los remplace por un solo salto de línea “\n”. El código quedaría así:
discurso_boric <- str_replace_all(discurso_boric, pattern = "\n\n", replacement = "\n")
El paquete “stringr” tiene una función que se llama str_replace() que solo hace el remplazo en el primer elemento que encuentra. Procura escoger str_replace_all para que haga el cambio todas las veces que encuentre el patrón que nos interesa.
Luego de ejecutar la modificación, volveremos a guardar nuestro objeto para que la versión del archivo txt refleje estos últimos cambios.
write_lines(discurso_boric, "discursos/cl_2022_boric_asuncion-cargo.txt")
¡Listo! Ya tenemos el primer texto de nuestro corpus.
Repetir el proceso para el segundo discurso
Quizás te estés preguntando si acaso no era más rápido copiar el discurso directamente del sitio web y pegarlo en un archivo txt. Si solo nos interesa un texto de un sitio, probablemente eso sea lo más rápido. Pero si necesitamos más de un texto, lo conveniente es hacerlo de forma programática. No solo por tiempo, sino porque así podemos evitar posibles errores humanos en el proceso. Además, incluso si se trata de un solo texto, tener el código para extraerlo permite que otras personas puedan repetir el proceso y obtener el mismo resultado, lo que favorece la reproducibilidad de nuestros flujos de trabajo.
El mismo código que escribimos para extraer el discurso de Gabriel Boric, debería servirnos para extraer el de Sebastián Piñera. Así que lo que haremos ahora será tomar el bloque de código que escribimos anteriormente y modificar tres cosas:
- El nombre de los objetos que creamos
- La url desde la que haremos la extracción
- El nombre del archivo en que guardaremos el texto procesado
El código quedaría así:
url_pinera <- "https://prensa.presidencia.cl/discurso.aspx?id=71722"
discurso_pinera <- read_html(url_pinera) |>
html_element("#main_ltContenido") |>
html_text2() |>
str_replace_all("\n \n", "\n")
write_lines(discurso_pinera, "discursos/cl_2018_pinera_asuncion-cargo.txt")
¡Listo! Si ejecutas esas líneas de código, debería aparecer el archivo en tu directorio de trabajo con el texto ya procesado.
Esto nos muestra que una vez que resolvemos cómo extraer datos de un sitio, podemos luego reutilizar el código para otras secciones que nos interesen. Con este mismo bloque de código, por ejemplo, podrías extraer todos los discursos que se encuentran en este sitio web.
En este archivo puedes revisar la versión final de nuestro script.
Síntesis
En esta lección conocimos cuáles son las características centrales de una página web que nos permiten extraer su contenido usando técnicas como el web scraping. Discutimos también acerca de cómo podemos resguardar que el procedimiento que implementamos se ajuste a las condiciones de uso del sitio del que nos interesa extraer datos. Finalmente, hicimos un primer ejercicio en el que seguimos el flujo de trabajo completo y revisamos las ventajas que tiene trabajar de este modo cuando necesitamos repetir una tarea de extracción.
Próximos pasos
Esta es la primera lección de la serie sobre web scraping usando R. En la próxima, aprenderemos a extraer tablas, y a partir de la tercera, veremos cómo crear funciones que nos permitan extraer datos de varias páginas al mismo tiempo.
Notas
-
Amazon.es. “Condiciones de Uso y Venta”, https://www.amazon.es/gp/help/customer/display.html?nodeId=201909000. ↩
-
En el menú Tools > Global Options > Code puedes configurar RStudio para que utilice el nuevo pipe como opción por defecto. Esto te permitirá incluirlo en tu código con el atajo de teclado Ctrl/Cmd + Shift + m. ↩
