Contenido
Contenidos
- Contenido
- Antes de empezar
- Introducción
- Instalación local de Omeka
- Un vistazo al “esqueleto” de Omeka
- Exportar e importar información de la base de datos
- Metadatos en Omeka
- Plugins o complementos
- Temas o plantillas
- Editar el
Corede Omeka - A modo de cierre
- Notas
Antes de empezar
Actualmente el proyecto Omeka se encuentra dividido en tres productos: Omeka Classic, una plataforma de publicación Web para construir y compartir colecciones digitales; Omeka.net, un servicio de alojamiento web específicamente diseñado para Omeka; y Omeka Semantic o S, lanzada en 2017, enfocada en la conexión de las colecciones con la Web semántica. Esta lección se basa en Omeka Classic1 por estar enfocada en proyectos particulares, de individuos o grupos medianos. Para construir grandes colecciones institucionales de documentos, bibliotecas o archivos, recomendamos usar Omeka S.
Algunos de los ejercicios planteados en esta lección requieren un repositorio con una cantidad de elementos (por lo menos una decena). Para facilitar el ejercicio puede descargar un dataset con elementos, colecciones y tipos de elementos desde este archivo.
Introducción
La abundancia de información documental que tenemos a disposición es cada vez mayor. Las fuentes primarias que se encuentran publicadas por archivos y bibliotecas han facilitado significativamente nuestro trabajo de recolección de información histórica. Sin embargo, esto ha conllevado un problema de abundancia de digitalizaciones y transcripciones de documentos que muchas veces quedan almacenadas anárquicamente en nuestros ordenadores. En esta lección aprovecharemos las capacidades de Omeka para desarrollar repositorios, individuales o colaborativos, para almacenar, analizar y exhibir fuentes primarias; con el propósito de presentar una opción para la sistematización de documentación primaria que posteriormente podrá ser utilizada en tareas de investigación o exhibiciones Web.
Para seguir esta lección requieres una instalación de Omeka. Puedes seguir la lección Installing Omeka disponible en el sitio en inglés (la versión en español se encuentra en proceso de traducción). En caso de que necesites conocer el funcionamiento básico de la plataforma es importante que entiendas como crear sitios, elementos, colecciones y exhibiciones.
Asimismo es importante que en caso de querer ampliar la información sobre el funcionamiento de Omeka recurras al manual de usuario de la versión clásica. También es posible que consultes o participes en el foro para obtener información adicional o respuesta a un problema específico.
Instalación local de Omeka
Instalar un servidor Web en tu ordenador brinda la posibilidad de ejecutar aplicaciones como Omeka de manera privada y gratuita; lo que representa una ventaja significativa para experimentar con proyectos que aún se encuentren en desarrollo o para utilizar Omeka con información privada que no se desea subir a un servidor Web accesible desde la Internet.
La arquitectura de Omeka está basada en PHP-MySQL, esto significa que la información que se agrega, modifica y lee desde el entorno de la plataforma escrito en PHP; queda almacenada en una base de datos MySQL; y se procesa mediante un servidor Apache. No es necesario entender exactamente el funcionamiento de la tecnología de servidor (se requeriría de una especialización en informática para ello), pero es importante familiarizarse con los conceptos de servidor Web, plataforma y base de datos para los ejercicios posteriores.
El sentido básico de este esquema puede resumirse con la siguiente imagen:
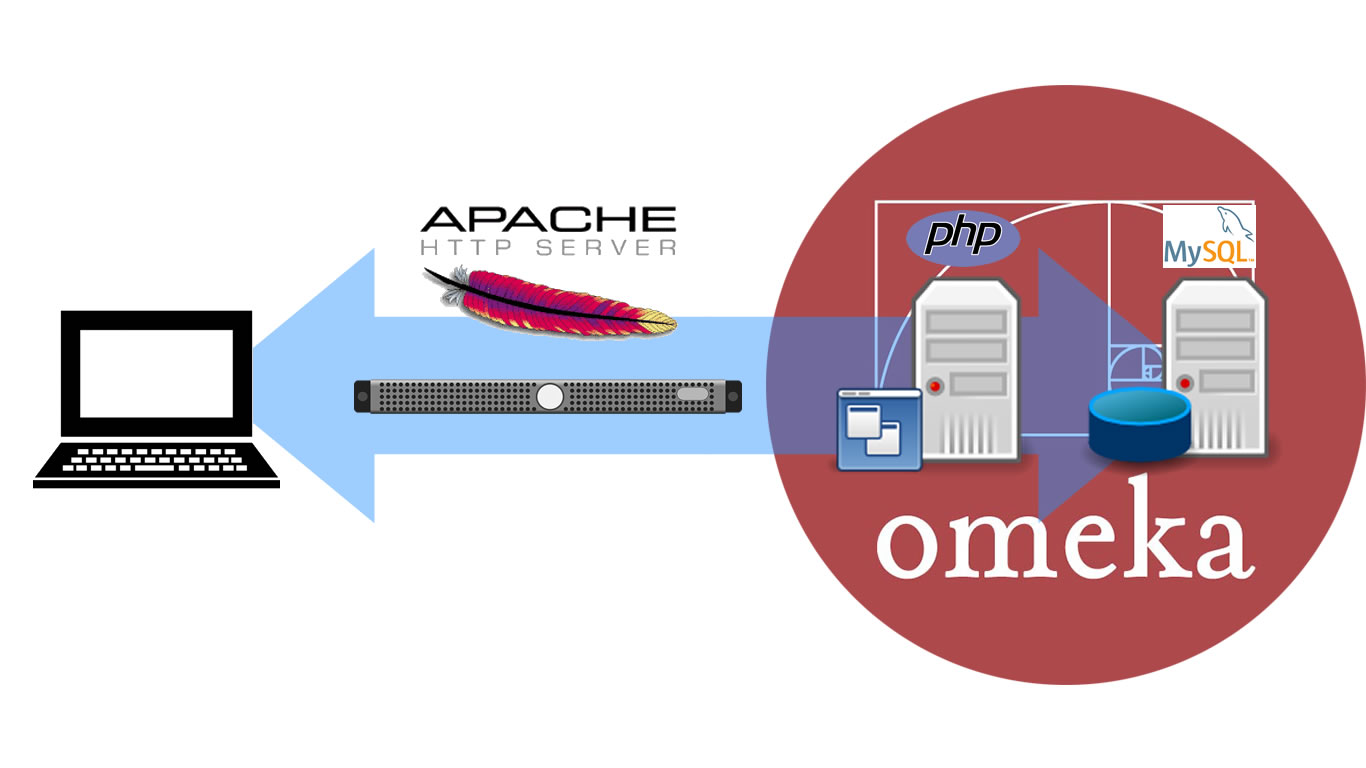
Síntesis de la tecnología de servidor
Para realizar la instalación local y configurar Omeka en tu ordenador, te recomendamos seguir las instrucciones del paso 2A de la lección Installing Omeka. También es recomendable consultar el manual elaborado por Manuel Alcaraz (bibliotecónomo con grado en ingeniería informática), en el cual cubre los aspectos necesarios para gestionar una instalación en Omeka desde la interface de administración del sitio.
En este tutorial te ayudaremos a instalar una máquina virtual, es decir, una serie de programas que permiten ejecutar aplicaciones que requieren tecnología de servidor (como Omeka) sin necesidad de tener contratado un servidor Web. También te mostraremos una forma común de gestionar la base de datos a través del aplicativo phpMyAdmin, una herramienta ampliamente difundida para administrar MySQL.
Instalar la máquina virtual
Para los fines de esta lección usaremos el entorno XAMPP, disponible para Windows, Linux y OS X. Después de descargar el paquete correspondiente a su sistema operativo instale el entorno siguiendo las instrucciones del instalador.2 A continuación le solicitará que escoja un directorio para albergar los archivos de la máquina virtual, en nuestro caso realizamos la instalación en Windows 10 y escogeremos la opción predeterminada C:\xampp; en el caso de Linux-Ubuntu será obligatoriamente /opt/lampp y en Mac OS X /aplications/XAMPP.
Para ejecutar el instalador en Linux deberás iniciar la terminal y dirigirte al directorio donde lo descargarte y hacerlo ejecutable mediante el siguiente comando (recuerda cambiar el nombre del ejemplo por el del archivo que descargaste):
sudo chmod +x xampp-linux-x64-7.2.10-0-installer.run
Luego ejecuta el archivo mediante el comando:
sudo ./xampp-linux-x64-7.2.10-0-installer.run
A partir de allí sigue las instrucciones del instalador.
Tras la instalación, la primera acción que debemos realizar será activar los módulos “Apache” y “MySQL” para poner a funcionar nuestro servidor.3 Para eso sólo debes hacer click en los botones “Start” de la columna “Actions”, tras lo cual los módulos se pondrán de color verde.
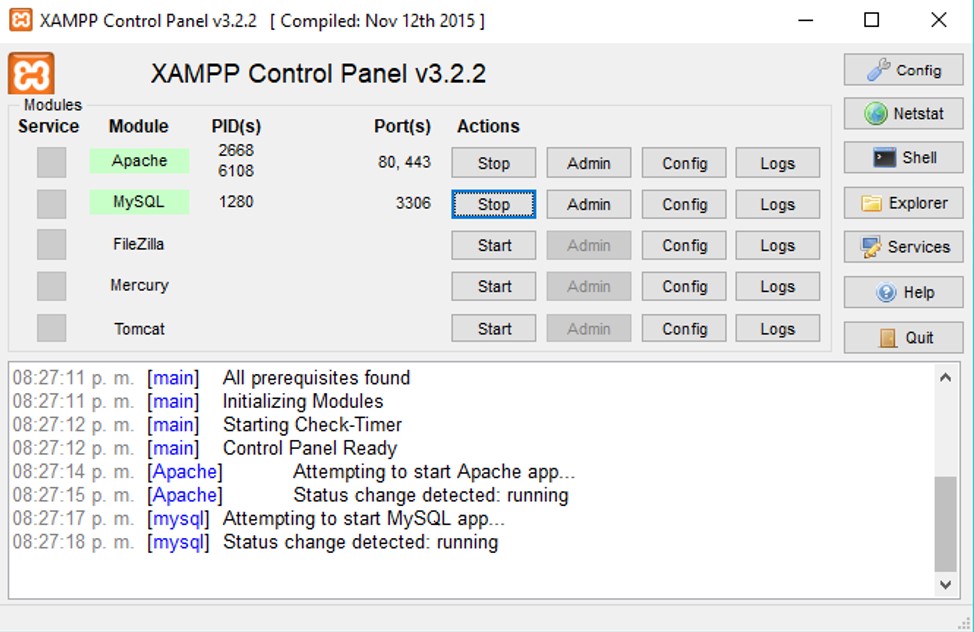
Módulos XAMPP activados
Para probar que todo funciona correctamente, ingresa desde tu navegador a la dirección http://localhost/ o http://127.0.0.1. Si la instalación es correcta te mostrará la pantalla de inicio:
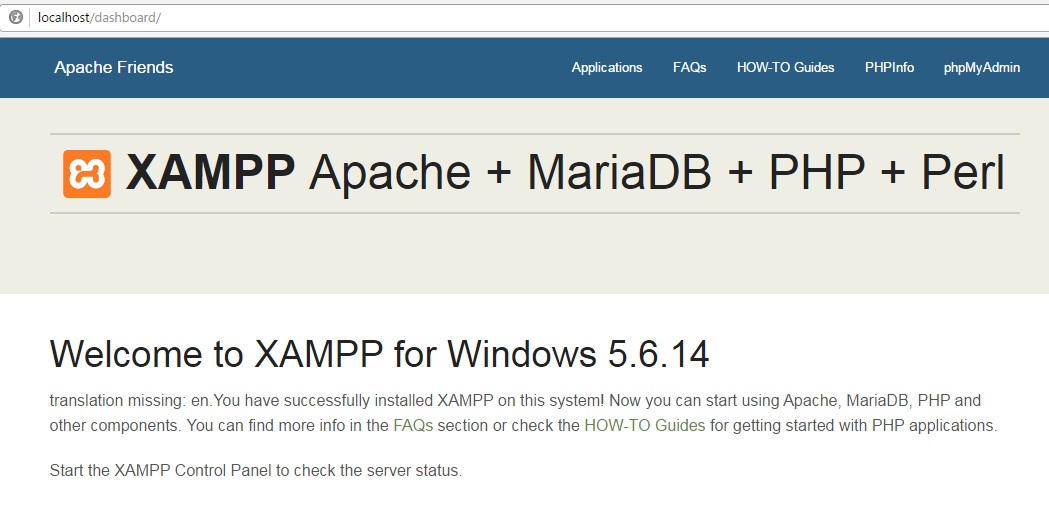
Pantalla de inicio (dashboard) de XAMPP
Deberás tener en el menú de inicio de Windows un menú de XAMPP con tres opciones desplegables. Las más útiles para nuestro trabajo serán “XAMPP Control Panel”, que abre el panel de control para activar o desactivar los módulos, y “XAMPP htdocs folder”, un enlace al directorio donde se guardarán los archivos de Omeka para realizar la instalación, por lo general es C:\xampp\htdocs para Windows. En Linux este directorio se encuentra en la ruta /opt/lampp/htdocs.
Errores comunes en Windows que pueden surgir de este proceso pueden derivarse de haber instalado la máquina virtual sin desactivar el antivirus, conflictos con otras máquinas virtuales previamente instaladas, o haber escogido un directorio, para el caso de Windows 10, en la carpeta C:\Program Files (x86). En todos estos casos la opción más sencilla consiste en reinstalar la máquina y evitar estas advertencias.
En el caso de Linux tal vez sea necesario instalar instancias adicionales como “net-tools”. Si va a utilizar XAMPP de manera frecuente lo más recomendable es crear un script para iniciar la aplicación automáticamente en cada reinicio del ordenador.
Gestionar las bases de datos desde phpMyAdmin
Para la instalación de Omeka es necesario crear una base de datos que albergará información que permite relacionar elementos, tipos de elementos, colecciones, entre sí y con otros objetos, como textos, documentos o imágenes.
Para crear la base de datos es posible utilizar los métodos explicados en el paso 2 de Installing Omeka. También podemos utilizar phpMyAdmin para crear la base de datos de la instalación e incluso para editarla después.
El primer paso consiste en ingresar al entorno de phpMyAdmin a través de la dirección http://localhost/phpmyadmin/ XAMPP te dejará ingresar sin contraseña, pero otros servicios (como Bitnami) te exigirán permisos de usuario para ingresar.4 La página de inicio te mostrará una página con la configuración general del servidor de la base de datos, el servidor web y de la aplicación. Esta pantalla será importante al momento de requerir la versión de MySQL (“Servidor de base de datos » Versión del servidor”), la versión de PHP (“Servidor web » Versión de PHP”), o incluso el nombre de usuario del servidor (por lo general “root@localhost”). Esta pantalla es útil no sólo en instalaciones locales, servirá también para comprobar que algún servicio de alojamiento web corresponda con la tecnología necesaria para ejecutar ciertas aplicaciones.
En phpMyAdmin seleccionaremos la pestaña “Bases de datos” donde veremos un pequeño formulario para crear la base de datos, sólo tenemos que ingresar el nombre de la base de datos e indicar el cotejamiento. Seleccionaremos el cotejamiento utf8_spanish_ci ya que representará una mayor precisión al momento de ordenar los elementos (items) en Omeka.[^collate] Esto es particularmente relevante en las instalaciones en Linux que suelen seleccionar de manera predeterminada un cotejamiento latin1_.
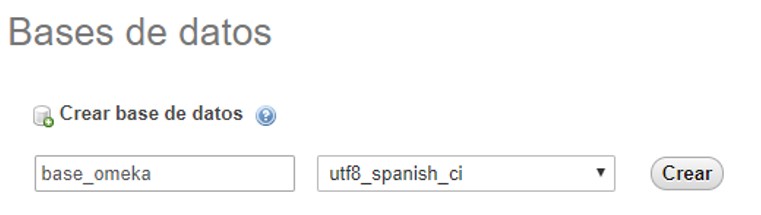
Crear base de datos en phpMyAdmin
Después de crear la base de datos la plataforma lo llevará al escritorio donde podrá gestionar las tablas, ejecutar código SQL, importar y exportar tablas, gestionar los permisos de los usuarios, entre otras acciones. Por el momento la base de datos estará vacía puesto que no hemos creado ninguna tabla. Asegúrese de que haya un usuario vinculado a la base de datos (pestaña “Privilegios”) y que tenga todos los privilegios. En caso contrario puede seleccionar “editar privilegios” y hacer clic en la casilla “Seleccionar todo”. También puede crear y dar permisos a otros usuarios (sólo en caso de administrar colaborativamente la base de datos) desde el menú “Agregar cuenta de usuario”.
Antes de salir anota los siguientes datos que te servirán para configurar el archivo db.ini:
- Nombre del servidor
- Nombre de la base de datos
- Nombre de usuario
- Contraseña del usuario
Cambiar el idioma a español
La configuración predeterminada de Omeka hace que la interface del respositorio se muestre en inglés. Lastimosamente, el panel de administración no tiene una opción para seleccionar el idioma y hacer que el sitio se muestre en español. Por lo tanto, debemos hacer este cambio de manera manual modificando el archivo config.ini que se encuentra en el directorio application/config. Desde un editor de texto o de código abre el archivo y busca la línea que dice locale.name = "" y entre paréntesis escribe la palabra “es”, que corresponde al código de lenguaje ISO 639 para el castellano.
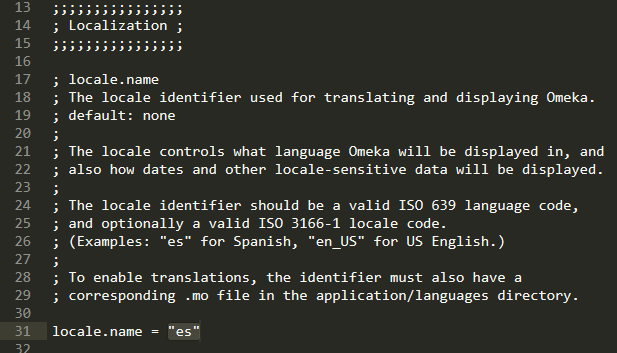
cambiar idioma a español en la configuración
Paso extra en Linux
Aunque la instalación de Omeka no debería representar un problema, es necesario tener en cuenta que para las instalaciones en Linux se deben asegurar los permisos de escritura de los directorios que almacenarán los archivos. Para ello, antes de iniciar la instalación ejecute el siguiente comando en la terminal:
sudo chmod -R 777 /opt/lampp/htdocs/dirección_del_repositorio/files
Esto debería permitir el inicio de la instalación.
Otro paso extra
Es opcional, aunque muy recomendable, que en tanto el repositorio se encuentre en desarrollo se activen los mensajes de error. Existen dos opciones, una pública y una privada:
- Opción pública: En el archivo
.htaccessdel directorio raíz, retira el signo de comentario (#) en la línea#SetEnv APPLICATION_ENV development. Los mensajes de error se mostrarán en la página de inicio. - Opción privada: Edita el archivo
application/config/config.iniy cambia el valor de la opción ‘logging’ de falso a verdadero:log.errors = true. Los errores se verán en el archivoapplication/logs/errors.log. Asegúrate que el archivoerrors.logtiene permisos de escritura, de otro modo no funcionará.
Un vistazo al “esqueleto” de Omeka
Si vamos a phpMyAdmin veremos que la base de datos vacía está ahora llena con 19 tablas interdependientes. La estructura de la base de datos (database schema) puede describirse de manera sintética agrupando las tablas en cinco grupos de información: datos para los elementos y colecciones, etiquetas, metatados de los tipos de elementos, información de usuarios, texto para búsqueda, y tablas para procesos del sistema. Un mapa resumido de las interdependencias entre las tablas se puede ver en la siguiente imagen:

Esquema de la interdependencia de la base de datos de Omeka
Como en un circuito eléctrico, cada tabla contiene información necesaria para un conjunto de procesos, por ejemplo, cuando se muestra un elemento se toma información de las tablas omeka_collections y omeka_elements_text, pero, para saber cuál texto corresponde a cual elemento y colección las interrelaciona en la tabla omeka_items que cruza el número de identificación de la colección con el del elemento. A medida que vayamos progresando en esta lección se hará más claro el funcionamiento de la base de datos.
Además de la base de datos, Omeka funciona gracias a los archivos que permiten leer la información para mostrarla en una página web y los formularios que hacen posible ingresar nueva información en la base de datos sin necesidad de hacerlo directamente en las tablas, un proceso que sería demasiado tedioso como para ser funcional.
Al instalar Omeka exploramos un poco el directorio raíz de la plataforma, específicamente la carpeta application\config. No vamos a explorar a profundidad la estructura de archivos de Omeka, pero quisiera indicar algunos directorios claves para el manejo avanzado de la plataforma:
/plugins: En esta dirección se almacenan los paquetes de “plugins” o complementos que añaden capacidades adicionales a la plataforma. De manera predeterminada vienen incorporados “CoinS” (lectura de metadatos bibliográficos en HTML), “ExhibitBuilder” (crear presentaciones) y “SimplePages” (crear páginas). Otros “plugins” pueden descargarse de https://omeka.org/classic/plugins//themes: El directorio de las plantillas de Omeka. Con la instalación se incluyen tres temas: “default” (“Thanks, Roy”), Berlin y Seasons. Estos tres temas presentan las configuraciones clásicas de Omeka a partir de las cuales se desarrollan las plantillas disponibles en https://omeka.org/classic/themes/, que para instalarse deben subirse o copiarse a este directorio./files: En este directorio se guardan las imágenes en sus diferentes tamaños después de haberse subido y pasado por ImageMagick, también los PDF y cualquier otro archivo que se haya subido por medio de la plataforma. Cada archivo es renombrado con una cadena alfanumérica aleatoria que asegura la identificación del objeto. El nombre original con el cual fue subido el archivo se almacena en la columnaoriginal_filenamede la tablaomeka_files./application: Este directorio puede considerarse como el corazón de la plataforma y contiene los archivos que hacen funcionar los complementos, los temas, las páginas de búsqueda, etc. Sólo mencionaré dos subcarpetas de cierta relevancia:\application\configque ya conocemos, yapplication\languages, que alberga los archivos de traducción de la plataforma en formato.mo. El archivo para el idioma español se llamaes.moy puede ser editado en caso de requerirse modificar alguna expresión o palabra5.
La mayoría de los proyectos que involucran Omeka tendrán que interactuar con los dos primeros directorios y, dependiendo de la complejidad del desarrollo, con los demás.
Lo importante, tanto para la base de datos como para el directorio de archivos, consiste en familiarizarse con la plataforma y de esta manera responder ante una falla de manera más rápida, lo cual es además de gran utilidad al momento de hacer una consulta en un foro de soporte o buscar una posible solución en la web.
Exportar e importar información de la base de datos
Crear una copia de seguridad de la base de datos
Cuando vas a actualizar la plataforma, modificar un archivo de la instalación, editar la base de datos, o probar con un plugin experimental; siempre es recomendable realizar una copia de seguridad de la base de datos. De hecho, es una buena práctica hacerlo periódicamente para así tener un respaldo de nuestra información.
La manera más recomendable para respaldar la base de datos consiste en exportarla a una dirección local o remota. Para ello, solamente tenemos que seleccionar la opción “Exportar” en phpMyAdmin. El método rápido de exportación es recomendado para realizar los respaldos ya que incluye todas las tablas y el contenido de estas. Si solamente deseas exportar una parte, renombrar la base de datos, tablas o columnas; agregar opciones para reescribir y crear tablas, o escoger un tipo de sintaxis; puedes escoger el modo perdonalizado de exportación.
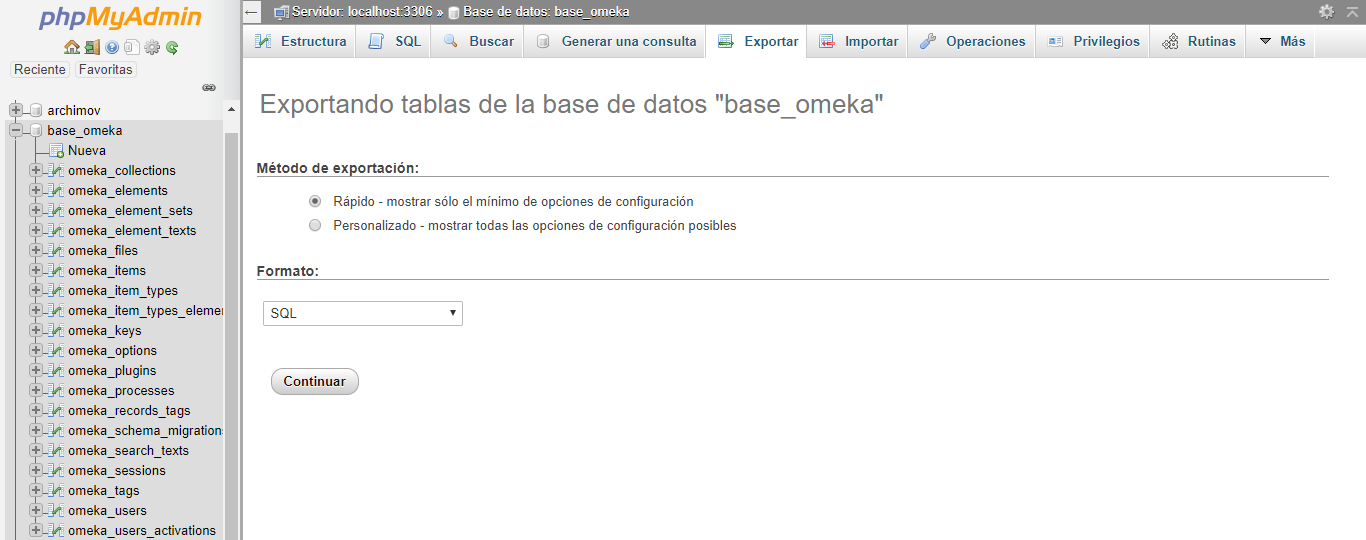
Exportar tablas de la base de datos de Omeka
También puedes exportar la información en formatos como csv, JSON, xml, e incluso en YAML. Sin embargo, las opciones personalizadas son mucho más limitadas en estos formatos, por lo que no son ideales para realizar copias de seguridad.
Si realizas una exportación personalizada es recomendable que evites seleccionar la opción CREATE DATABASE, ya que esto podría generar problemas de importación.
Importar el dataset
Para mayor comodidad en la experimentación, creé un pequeño dataset con elementos, colecciones, etiquetas y tipos de elemento. Este contiene exclusivamente las tablas omeka_collections, omeka_elements, omeka_element_sets, omeka_element_texts, omeka_items, omeka_item_types, omeka_item_types_elements, omeka_search_texts, omeka_tags.
Añadí la opción DROP TABLE, de tal manera que al hacer la importación se reemplacen las tablas existentes. <div class="alert alert-warning">No importe este dataset en una instalación que tenga contenido o borrará la información existente.</div>
Para importar el dataset, lo haremos también en phpMyAdmin desde la pestaña “Importar”. Solamente deberemos seleccionar el archivo y comprobar que la opción “Conjunto de caracteres del archivo” sea “utf-8” y que el “Formato” sea “SQL”.
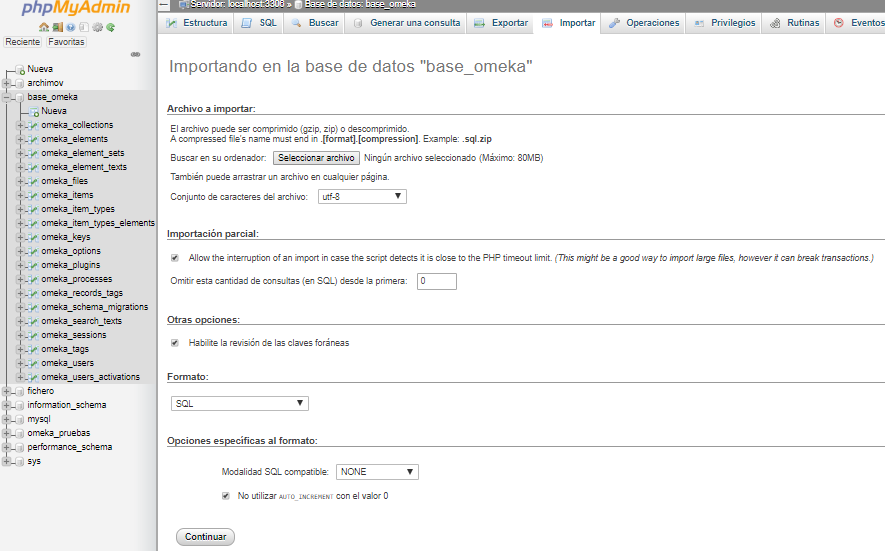
Importar tablas de la base de datos de Omeka
Para comprobar que la instalación ha sido exitosa, solamente debe navegar a su página de Omeka y desde allí revisar que los elementos hayan sido instalados.
Solución de problemas
Es probable que al importar una base de datos aparezca el mensaje de error #1050 la tabla 'xyz' ya existe. En ese caso será necesario eliminar las tablas o toda la base de datos desde la pestaña “Estructura” para poder proseguir con la importación.
Metadatos en Omeka
Para muchos la palabra “Metadatos” suena oscura y “metafísica”, algo que está más allá de los datos. Sin embargo, el sentido de los metadata es mucho más sencillo, signfica simplemente datos acerca de los datos (data about data) que tienen la función de indicarle a las computadoras dónde se encuentra un objeto digital. Por ejemplo, una fotografía de la capilla sixtina es sólo un conjunto de bits compilados en un archivo de imagen, por ejemplo jpg o png; pero el nombre que le otorgamos al archivo (por ejemplo, “capilla_sixtina-jpg”) ya es un metadato que ayuda a humanos y máquinas a encontrar la fotografía de ese edificio. Ahora, si a ese archivo, además del nombre le asociamos otros indicadores como fecha, lugar, quién tomó la fotografía, algunas palabras que describan el tipo de objeto de la imagen (por ejemplo: capilla católica, religión, arquitectura del siglo XV), otros objetos con los que está relacionada, etc.; estamos hablando entonces de un “conjunto de metadatos” o metadata set.
Los metadatos son independientes del lenguaje de máquina o de programación, es decir, son categorías completamente personalizables que funcionan de manera independiente de la plataforma. Esta libertad conlleva una gran desventaja y es que si cada usuario creara sus elementos de manera arbitraria no habría manera de intercambiar información entre sistemas. Por esa razón, se creó una estrategia de estandarización de los conjuntos de metadatos de tal manera que facilite la interacción entre plataformas, la actualización del software y, sobre todo, el compartir y encontrar información en grandes repositorios.
Omeka Classic se fundamenta en el estándar Dublin Core, específicamente en el esquema básico de 15 descriptores Dublin Core Metadata Element Set Version 1.1:
Título (title)
Autor (creator)
Palabras claves (subject)
Descripción (description)
Editor (publisher)
Colaborador (contributor)
Fecha (date)
Tipo de recurso (type)
Formato (format)
Identificador (identifier)
Fuente (source)
Lenguaje (language)
Relación con otros objetos (relation)
Cobertura espacial (coverage)
Derechos (rights)
Por medio de estos elementos es posible describir la mayoría de los objetos digitales: textos, imágenes, audio, video y multimedia. Esto no implica que todo elemento tenga que tener un archivo adjunto para visualizar en la plataforma (aunque es lo ideal). Puede funcionar de modo similar a un catálogo de una biblioteca, archivo o museo.
Sin embargo, como habrás notado, este listado de descriptores es bastante limitado. ¿Dónde indicarías una dirección Web, un nombre, un texto? Para eso, Omeka diseñó la opción “tipos de elemento”, en la cual se pueden agrupar los objetos por sus características generales. De manera predeterminada se encuentran disponibles los tipos texto, imagen en movimiento, historia oral, sonido, imágen estática, sitio Web, evento, correo electrónico, plan de curso, hiperenlace, entre otros. El usuario puede añadir otros tipos según sus necesidades a través del menú “tipos de elemento” en el panel de administración (/admin/item-types) o editar los tipos disponibles agregando descriptores disponibles de manera predeterminada o creando nuevos elementos.
Los tipos de metadatos son importantes porque nos ayudan a agrupar la información. Por ejemplo, si tenemos varios tipos de texto en un mismo repositorio podría se útil crear una categoría para aquellos que tengan una estructura particular. Por ejemplo, si estamos guardando descripciones de cartas y expedientes judiciales en un mismo proyecto sería recomendable separar ambos tipos para que no se agrupen todos como “texto”. Para ello, crearemos un tipo de elemento con las siguientes categorías: delito, índice, sindicado, juez, sentencia, y texto.
Desde el menú “Agregar tipo de elemento” rellenamos el formulario con un nombre para el nuevo tipo de elemento y una descripción opcional.
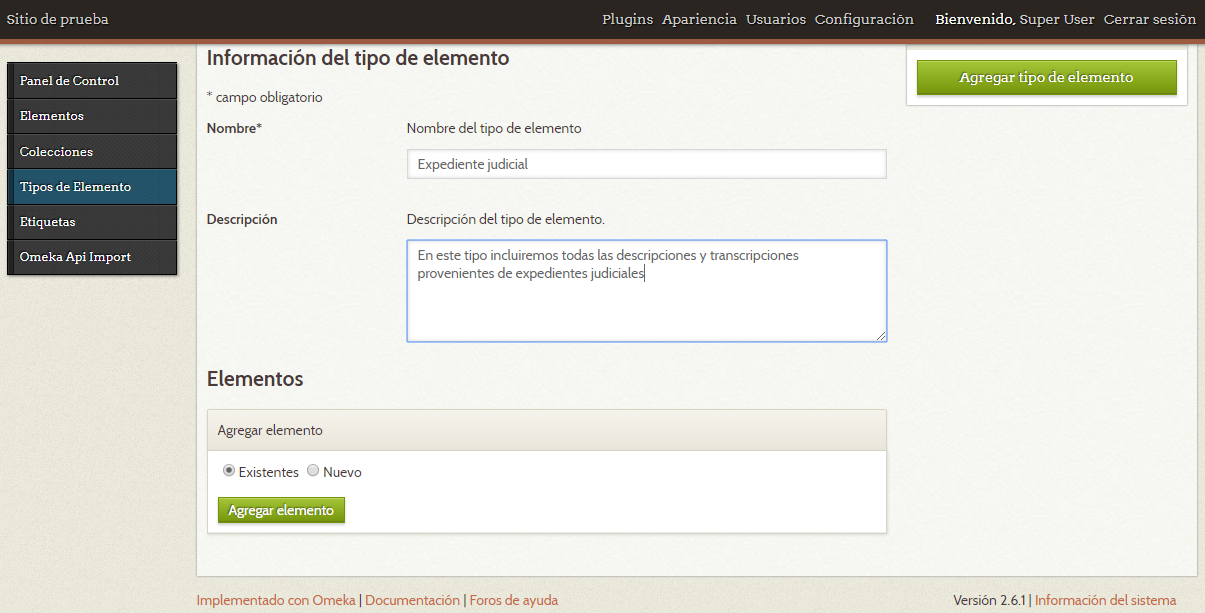
Agregar tipo de elemento
Para incluir los descriptores debemos utilizar el menú “Agregar elementos”, ubicado al final del formulario. Si el elemento ya existe en el vocabulario predeterminado simplemente dejamos señalada la opción “Existentes” y lo escogemos desde la lista desplegable.
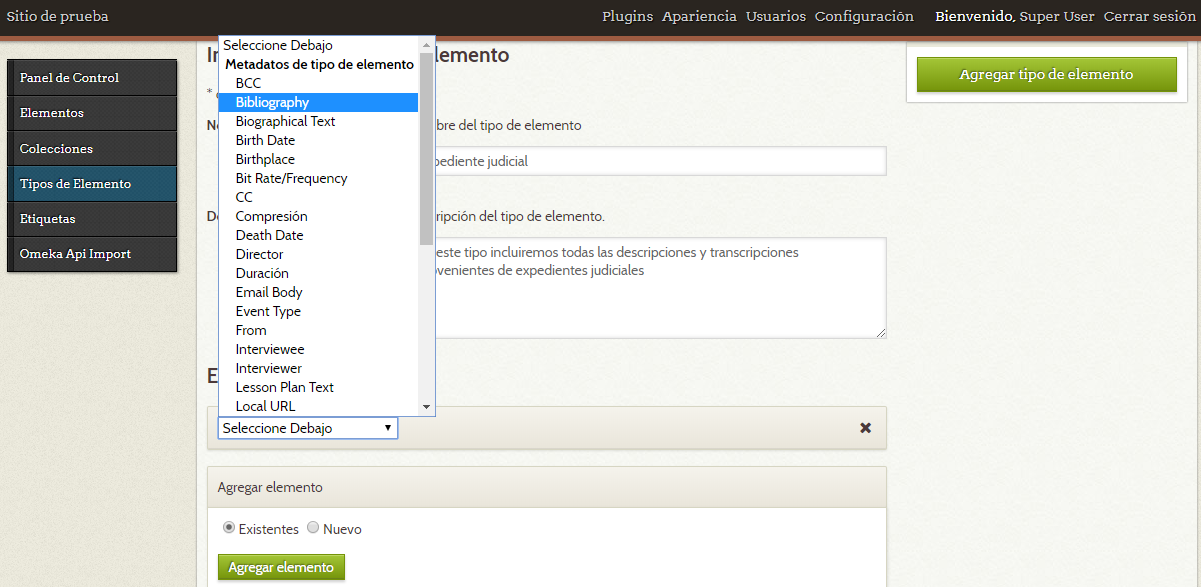
Agregar elementos existentes
Para crear los descriptores personalizados simplemente marcamos la opción “Nuevo” y rellenamos el formulario.
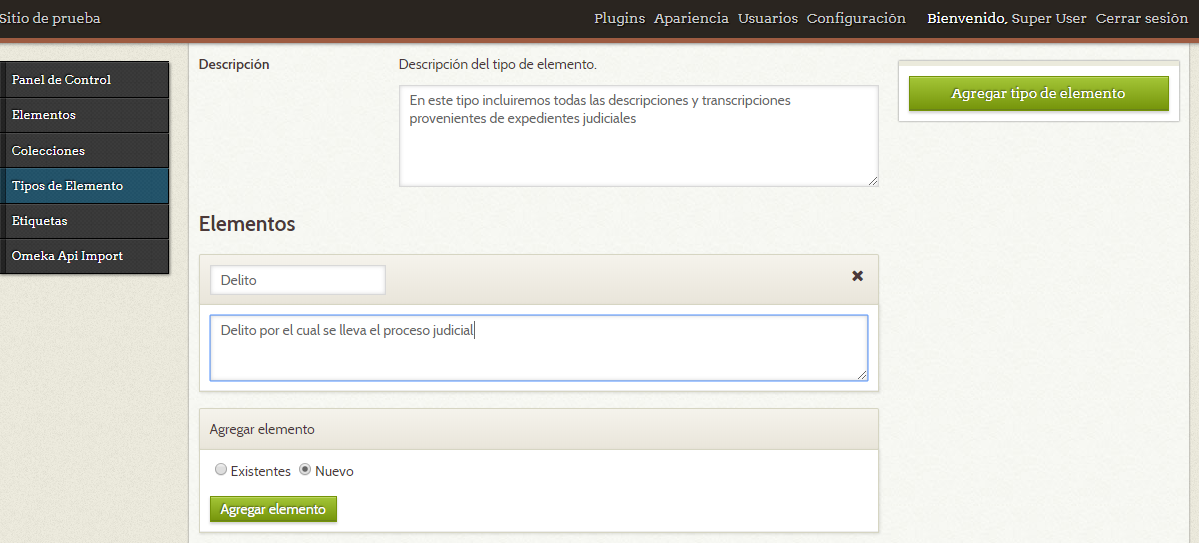
Agregar elementos nuevos
Al finalizar debe aparecer un listado con los formularios diligenciados y los elementos existentes escogidos. Para completar el tipo pulsa el botón “Agregar tipo de elemento”, tras lo cual se mostrará una pantalla de confirmación, con la descripción del tipo y los elementos asociados.
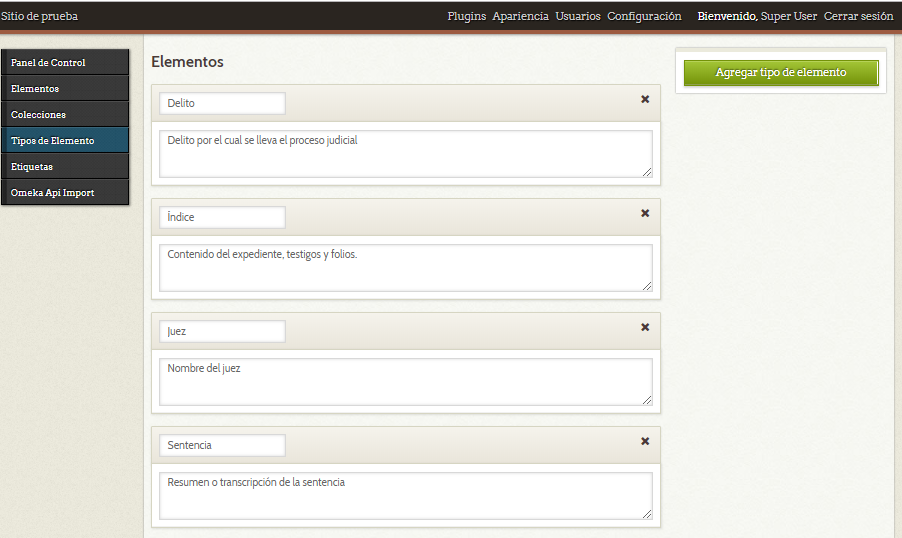
Agregar tipo de elemento
Para utilizar el tipo de elemento, solamente debes seleccionar la pestaña “Metadatos de tipo de elemento” al momento de agregar un nuevo elemento, y en el menú desplegable seleccionar el tipo que creaste.
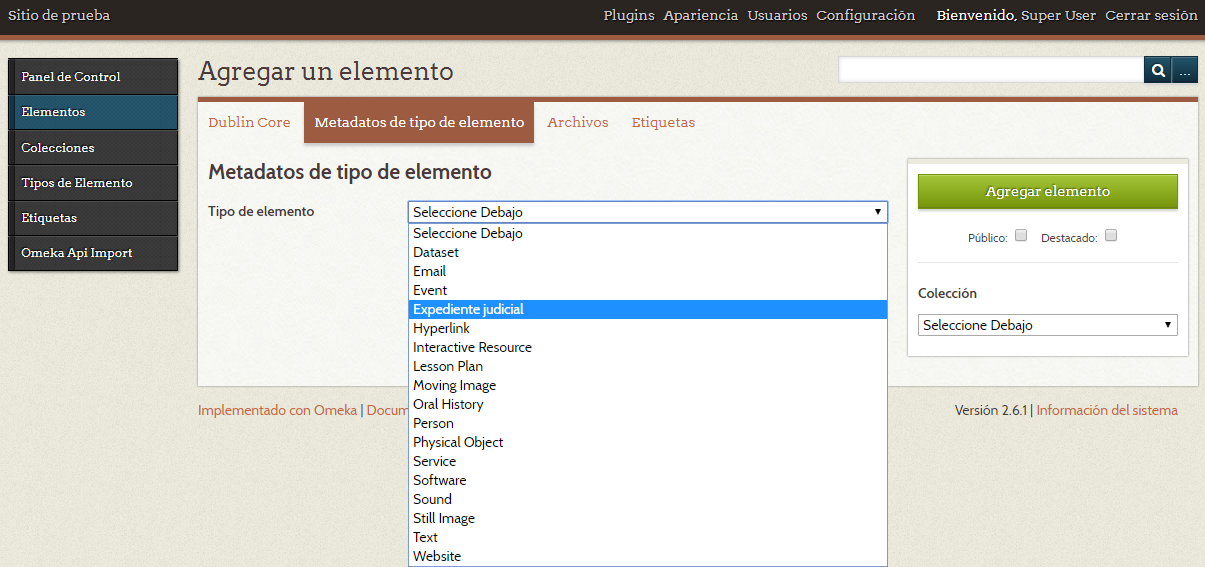
Seleccionar tipo de elemento
Vocabulario controlado y ontologías
Para terminar con el tema de los metadatos, es importante entender que toda la información que guardamos en las categorías son cadenas de texto, es decir, si en el elemento “Fuente” escribimos “Casa” no hay ninguna advertencia que indique que esa palabra no corresponde con el elemento. Para evitar lo anterior, se recomienda recurrir a vocabularios controlados, que no son otra cosa sino los términos que coinciden con cada elemento y que son consistentes a lo largo del repositorio. Para los proyectos institucionales se requiere de un esfuerzo importante en términos de interoperabilidad para que los objetos puedan ser recuperados de manera correcta. También es necesario en este sentido la adopción o desarrollo de “ontologías”, es decir, de una organización jerárquica de los componentes que representan un objeto de información (también denominada “taxonomía”). Al respecto, un buen punto de partida puede ser la lección de Jonathan Blaney Introducción a los Datos abiertos enlazados.
Si estamos construyendo un sitio personal no es necesario (aunque sería lo ideal) recurrir a un vocabulario controlado o una ontología; sin embargo, es casi imprescindible ser consistentes con la forma de insertar la información. Por ejemplo, si incluimos en el elemento Autor el nombre “Pérez, Pedro” debemos tener la cautela de que todos los nombres que ingresemos posteriormente cumplan con el formato “Apellido, Nombre”. De la misma manera, la gestión de los metadatos debe evitar la ambigüedad, de tal manera que si el nombre no es de un autor sino, por ejemplo, un juez, pueda hacer la búsqueda en ese campo y no en otro. Por otra parte, como la información se almancena en formato de texto las fechas se ordenan alfabéticamente, por ello es indispensable seguir la recomendación de Dublin Core que señala el formato año, mes, día (AAAA/MM/DD) para los elementos temporales. Igualmente, es importante ser riguroso al ingresar la información para evitar que la fecha de un evento se confunda con la fecha de publicación de la fuente, por ejemplo.
Plugins o complementos
Un plugin es un pequeño programa que añade una función específica a otro programa, por ejemplo, un CMS tipo Wordpress o Joomla puede incorporar una casilla de comentarios, pero un plugin puede hacer que esta casilla se conecte con las redes sociales y comentar desde su perfil de Facebook o Twitter. En esta lección sólo veremos cómo añadir plugins a nuestra instalación de Omeka[^omeka.net], si desea profundizar en la manera de desarrollar un complemento lo más recomendable es consultar la documentación disponible en la página de Omeka.
Las dos fuentes principales de plugins para Omeka son el repositorio oficial de complementos https://omeka.org/classic/plugins/ y Github. Ambos listados son dinámicos, por lo que recomendamos visitar periódicamente estos lugares para conocer novedades y actualizaciones.
Para instalar un plugin sólo es necesario descargar el complemento de nuestro interés, descomprimirlo (se encuentran almacenados en archivos *.zip) y copiarlo en el interior de la carpeta plugins 6. Después ingresamos al panel de control de Omeka y a la administración de plugins (/admin/plugins) donde aparecerá el nombre de cada plugin que hayamos copiado en la carpeta, de manera similar a la siguiente imagen:
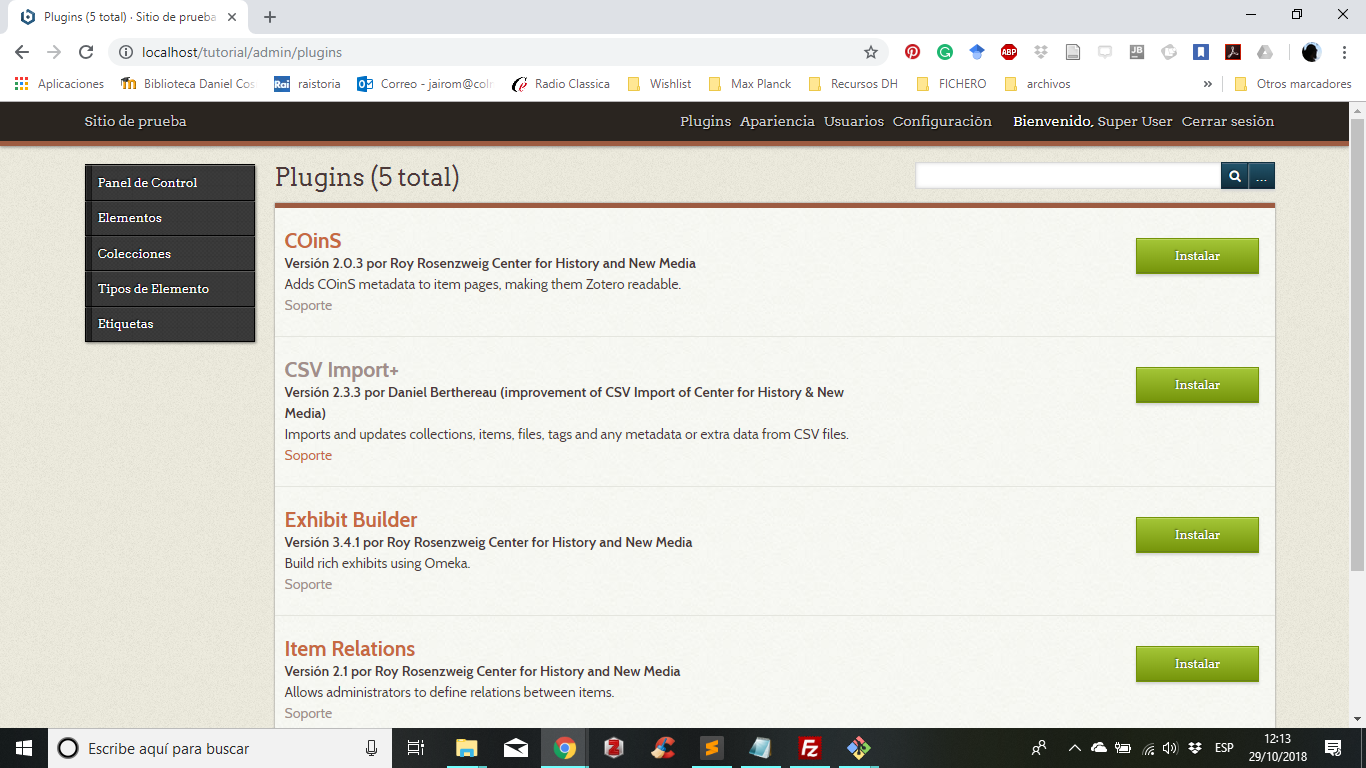
Panel de administración de plugins
Para instalar un complemento desde Github necesitamos tener instalado Git en el ordenador 7.
Como ejemplo, instalaremos el plugin “Csv Import+” desarrollado por Daniel Berthereau, el cual es una mejora del complemento oficial CSV Import. Para ello, iremos al repositorio del plugin que está ubicado en Github y copiamos el enlace para clonarlo. Después, desde la carpeta plugins ejecutamos el comando clonar, git clone y le indicamos la ruta de descarga:
git clone https://github.com/Daniel-KM/Omeka-plugin-CsvImportPlus.git
Al terminar de clonar veremos una carpeta con el nombre Omeka-plugin-CsvImportPlus. Para que funcione correctamente debemos cambiar el nombre a CsvImportPlus, tras lo cual será posible ver activado el botón Instalar.
Desde el panel de administración de plugins es posible:
- Instalar: Con este botón se ejecuta el script que instala el plugin.
- Desinstalar: Desinstala el plugin y borra la información de configuración del mismo.
- Desactivar: Todos los plugins quedan activos después de instalados, si por alguna razón no van a ser usados en el momento pero no quiere desinstalarlos puede aplicar esta opción y dejar el contenido de configuración y los archivos intactos.
- Activar: Revierte la anterior acción.
- Configurar: Enlaza con la página de configuración del plugin. Algunos complementos necesitan cierta información para poder funcionar, otros pueden ser personalizados para que su funcionamiento o presentación se adapte a los requerimientos de los usuarios.
Solución de problemas
Cuando se descarga un plugin directamente de Github puede aparecer la advertencia “No es un plugin válido.” En ese caso, asegúrese de que el nombre del directorio no contenga la palabra -master o -plugin. También puede comprobar que el nombre del directorio corresponda con el archivo del plugin que obligatoriamente tiene esta forma: NombreComplementoPlugin.php. Si estas opciones no funcionan lo más probable es que el plugin simplemente no corresponda a la versión o aún se encuentre en desarrollo, en cuyo caso no podrá instalarse.
También puede suceder que un plugin se instale y genere conflictos en la plataforma que generarán un mensaje de error o incluso impedirán que se cargue el sitio. En este caso solamente deberá borrar los archivos del plugin y el sitio regresará a la normalidad.
Seleccionar los plugins
Para usar Omeka no es realmente necesario ningún complemento, sin embargo, el crecimiento del repositorio hace necesario incorporar “plugins” que permitan ampliar las capacidades de la plataforma. Una buena práctica consiste en instalar solamente aquellos plugins que realmente utilizaremos y desintalar aquellos que no necesitamos, con ello evitamos conflictos entre complementos y posibles problemas de seguridad por utilizar plugins obsoletos.
La selección de plugins dependerá en buena medida de los objetivos del repositorio, para nuestro caso se requerirán complementos que permitan:
- Mostrar los documentos y hacerlos legibles a los usuarios, ya sean imágenes, archivos PDF u otros. Por ejemplo, PDF Embed y Universal Viewer.
- Gestionar los metadatos de cada documento: procedencia, cobertura, fechas, nombres, etc. Por ejemplo Dublin Core Extended y Hide Elements.
- Buscar información: complementos que contribuyan a ampliar las capacidades de las búsquedas de Omeka. Por ejemplo Search by Metadata y PDF Text.
- Interrelacionar elementos y colecciones. Por ejemplo Item Relations, Collection Tree y Geolocation, Reference.
- Permitir la transcripción de documentos. Scripto es la opción más recomendada, pero también es posible apoyar el proceso de transcripción con el plugin Contribution
- Analizar la información disponible. Por ejemplo Ngram y Text Analysis.
- Exportar e importar información. Las opciones pueden ser Export, CSV Export Format, Omeka API Import, CSV Import, Import, o Zotero Import.
Explicar el funcionamiento de cada plugin extendería demasiado este tutorial. La estrategia recomendable consiste en instalar los complementos en la medida que vaya surgiendo la necesidad de cada proyecto.
Temas o plantillas
Hasta el momento nos hemos enfocado en la manera de tratar la información desde el plano de la administración del contenido. Los temas o plantillas comprenden los archivos que permiten mostrar de una manera dinámica la información contenida en la base de datos e interpretada con PHP, de tal manera que si se realizan cambios en la interface del sitio no afectan los archivos del lado del servidor. Sin los temas, la información sería presentada en forma de HTML simple, por lo que éstos son necesarios para permitir que la presentación del sitio sea agradable a quiénes la consultan, sea posible presentar de manera correcta los contenidos, y
Instalar un tema en Omeka es muy similar a la instalación de plugins. Los temas oficiales de Omeka están disponibles en el sitio del proyecto. A diferencia de otras plataformas, Omeka tiene una oferta vbastante limitada; aunque puede ampliarse si se explora GitHub. Familiarizarse con los temas puede representar una ventaja para personalizar el sitio y añadir algunas funciones que no vienen incluidas de manera predeterminada.
Instalar un tema
Descarga desde la colección de temas de Omeka, o clona desde GitHub, el tema que quieras instalar en el directorio /themes de la instalación de Omeka. Después de descomprimir el archivo tema.zip ve a la pestaña Apariencia del panel de administración o a la dirección /admin/themes/browse, podrás ver que el tema ya está listo para ser seleccionado. Sólo debes hacer clic en el botón “Hacer uso de esta plantilla” y el sitio cambiará de imagen.
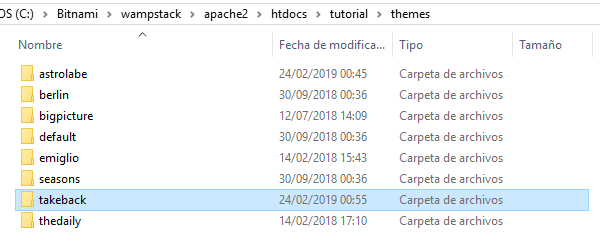
Directorio de temas
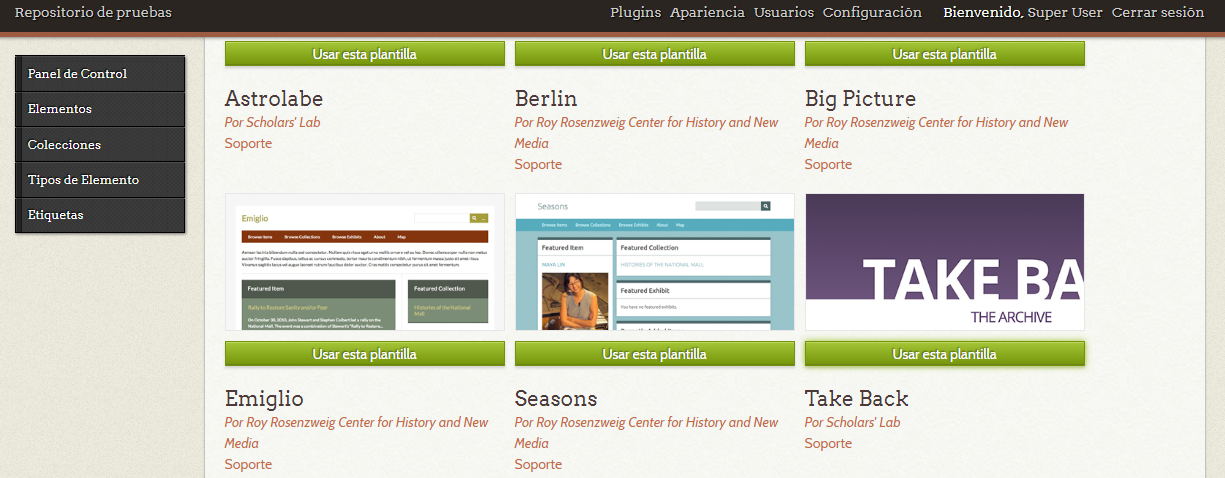
Panel de administración de temas
Posteriormente, dependiendo del tema escogido, podrás ir al panel de configuración del tema haciendo clic en el botón configurar plantilla. Allí tendrás la opción de personalizar ciertos aspectos del tema como el logotipo, la cabecera y “footer” del sitio, la configuración de la página de inicio y algunas opciones para mostrar los elementos. Otras plantillas más complejas pueden brindar opciones para la presentación de imágenes o para agregar códigos de seguimiento.
Edición de la plantilla
En este ejercicio vamos a crear una opción en la plantilla “Berlin” que nos permitirá ordenar los elementos por su fecha de creación. De manera predeterminada, Omeka ordena los elementos por la fecha en que fueron agregados a la plataforma, de tal manera que muestra de las entradas más recientes a las más antiguas. Cuando trabajamos con documentos históricos, por lo general, nos interesa poder ordenar por la fecha del documento, ya sea en orden ascendente o descendente.
Lo primero que podemos hacer será editar la navegación de los elementos para que se muestren por fecha en orden ascendente 8. Para ello debemos ir al panel de administración, de allí a la ventana “Apariencia” y escoger la pestaña “Navegación”. Retiramos la selección del enlace “elementos” y vamos al final de la página. En el formulario que dice “Agregar un vínculo a la navegación” pondremos como “Etiqueta” el nombre “Elementos” y en la “URL” la ruta /nombre_del_repositorio/items/browse/?sort_field=Dublin+Core%2CDate&sort_dir=a. Hacemos clic en el botón “Añade un enlace” y arrastramos el nuevo vínculo hasta el inicio de la página. Finalmente damos “Guardar” y debe aparecer el mensaje de confirmación “La configuración sobre la navegación ha sido actualizada.”
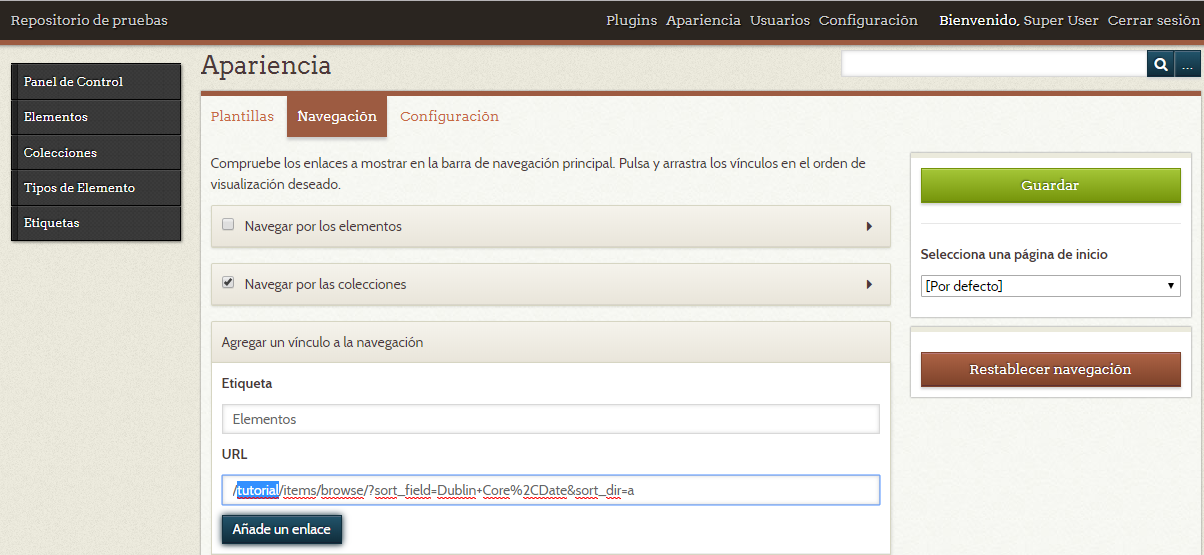
Agregar vínculo personalizado
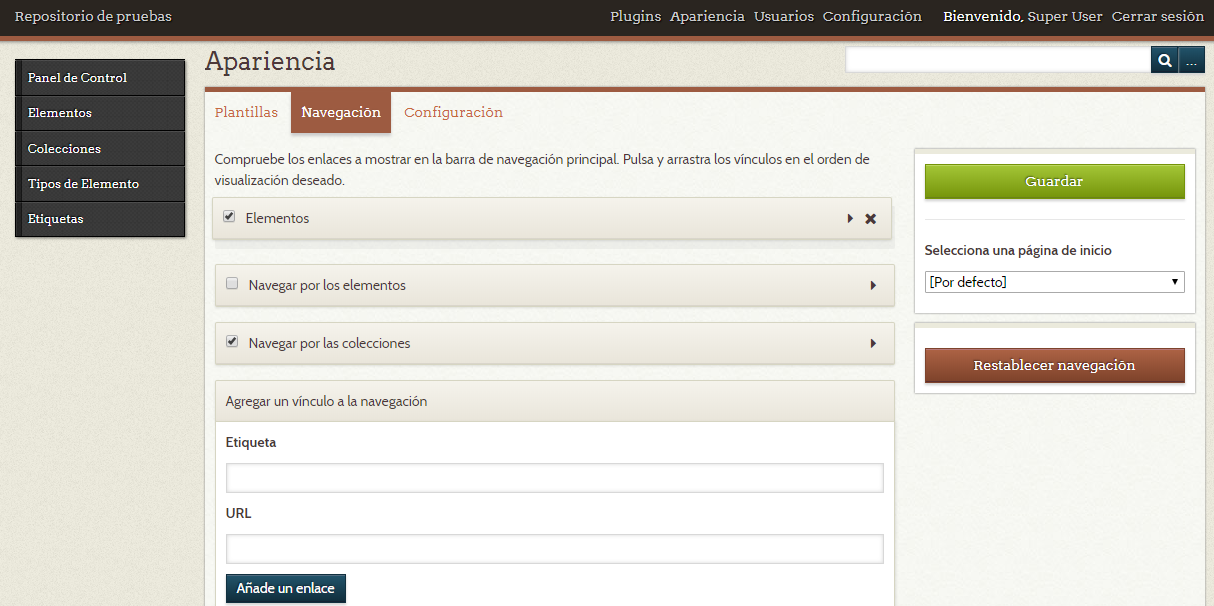
Personalizar menú de navegación
De esta manera le estamos diciendo a Omeka cada vez que entremos a la página “Navegar por los elementos” (/items/browse) que ordene los elementos por un campo (?sort_field), que en este caso será la categoría “Fecha” (CDate) de Dublin Core (Dublin+Core), y que este orden sea ascendente (&sort_dir=a).
Siguiendo esta lógica podemos hacer otro tipo de ordenación, por ejemplo, por descripción (?sort_field=Dublin+Core%2CDescription), e incluso por categorías que no estén en el Dublin Core sino como tipos de metadatos del elemento, como el texto (?sort_field=Item+Type+Metadata%2CText).
Esta opción, sin embargo, no evitará que en los resultados de búsqueda o en las colecciones se ordenen los elementos por fecha de agregación. Por esta razón una buena estrategia consiste en habilitar la opción general para ordenar por fecha del documento.
Sin importar lo compleja que sea una plantilla de Omeka, la estructura básica de la plantilla exige cumplir con una estructura básica que incluye una carpeta para los archivos de navegación de los elementos llamada items. Dentro de ella, dependiendo de la plantilla, habrá una serie de archivos php y uno de ellos se llama browse.php, responsable por mostrar los ítems en la página “Navegar por los elementos”. Como verás, la ruta se asemeja a la del sitio público que es /items/browse.
Abrimos el archivo browse.php en nuestro editor de código. Si no estás muy familiarizado con php este código parecerá escrito en Klingon. No importa que no sepas php (o Klingon), sólo nos vamos a concentrar en estas pocas líneas de código que se encuentran al inicio del código (aprox. después de la línea 18):
<?php
$sortLinks[__('Title')] = 'Dublin Core,Title';
$sortLinks[__('Creator')] = 'Dublin Core,Creator';
$sortLinks[__('Date Added')] = 'added';
?>
<div id="sort-links">
<span class="sort-label"><?php echo __('Sort by: '); ?></span><?php echo browse_sort_links($sortLinks); ?>
</div>
Para saber dónde empieza y termina cada script de php sólo tienes que fijarte en las etiquetas de apertura <?php y de cierre ?>. Todo lo que esté entre esos símbolos constituye un script de php. Las tres opciones que vemos en la esquina derecha del listado de ítems página “Navegar por los elementos” son “impresas” por el script <?php echo browse_sort_links($sortLinks); ?>, que básicamente le dice a php que muestre (echo) un grupo o array según la función browse_sort_links que se encuentra almacenado en la variable $sortLinks.
Para modificar las opciones de ordenación debemos editar la variable $sortLinks, que es la que guarda las opciones de ordenación. Para añadir nuestra opción de ordenar por fecha del documento vamos a crear un enlace que se llame “Fecha del documento” y un valor de ordenación que corresponda a la categoría Fecha del esquema Dublin Core.
En una línea nueva antes del cierre del primer script vamos a escribir el siguiente código: $sortLinks[__('Fecha del documento')] = 'Dublin Core,Date';
El código deberá quedar como sigue:
<?php
$sortLinks[__('Title')] = 'Dublin Core,Title';
$sortLinks[__('Creator')] = 'Dublin Core,Creator';
$sortLinks[__('Date Added')] = 'added';
$sortLinks[__('Fecha del documento')] = 'Dublin Core,Date';
?>
Guarda el archivo y carga nuevamente la página de navegación. Si todo salió según el plan, deberá aparecer el enlace con la opción “Fecha del documento”. Haz clic y prueba que la ordenación sea correcta. En caso de no obtener los resultados deseados revisa que los metadatos hayan sido escritos correctamente (comprueba que no hay espacios en blanco antes del texto y que el formato de las fechas sea coherente en todos los elementos).
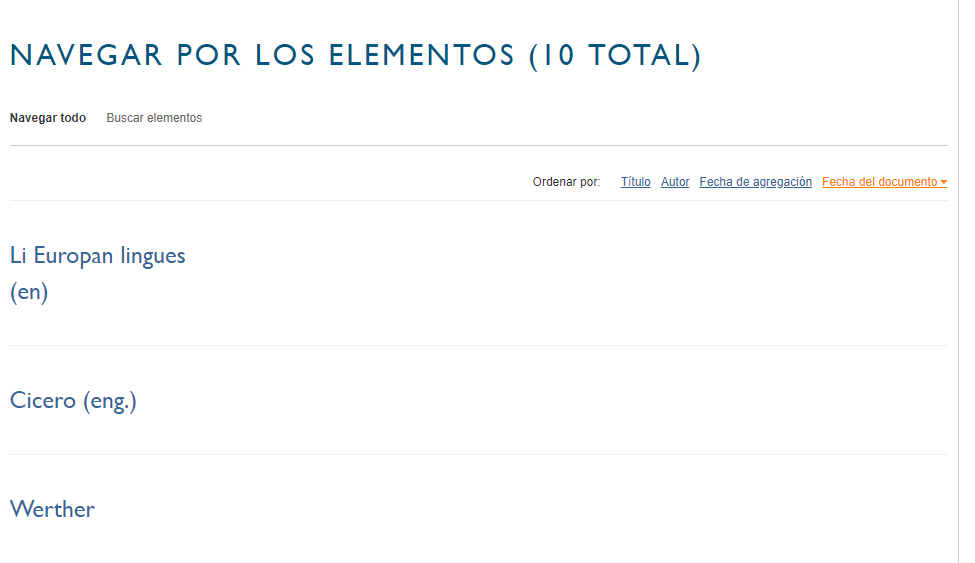
Ordenar por fecha del documento
También podemos hacer que sea posible ver la fecha del documento en la navegación. Para ello, agregaremos unas cuantas líneas al loop que está a continuación de la sección que acabamos de editar. La sección de código que editaremos será la siguiente:
<?php foreach (loop('items') as $item): ?>
<div class="item record">
<h2><?php echo link_to_item(metadata('item', array('Dublin Core', 'Title')), array('class'=>'permalink')); ?></h2>
<div class="item-meta">
<?php if (metadata('item', 'has files')): ?>
<div class="item-img">
<?php echo link_to_item(item_image()); ?>
</div>
<?php endif; ?>
<?php if ($description = metadata('item', array('Dublin Core', 'Description'), array('snippet'=>250))): ?>
<div class="item-description">
<?php echo $description; ?>
</div>
<?php endif; ?>
<?php if (metadata('item', 'has tags')): ?>
<div class="tags"><p><strong><?php echo __('Tags'); ?>:</strong>
<?php echo tag_string('items'); ?></p>
</div>
<?php endif; ?>
<?php fire_plugin_hook('public_items_browse_each', array('view' => $this, 'item' =>$item)); ?>
</div><!-- end class="item-meta" -->
</div><!-- end class="item hentry" -->
<?php endforeach; ?>
Después del segundo <?php endif; ?> ingresa el siguiente código:
<!--agrega la fecha a cada elemento -->
<?php if ($date = metadata('item', array('Dublin Core', 'Date'))): ?>
<div class="item-description">
<?php echo $date; ?>
</div>
<?php endif; ?>
Lo único que hacemos consiste en decirle a la plantilla que si el elemento tiene información sobre la fecha en el Dublin Core la inserte dentro de la división que tiene la clase “item-description”.
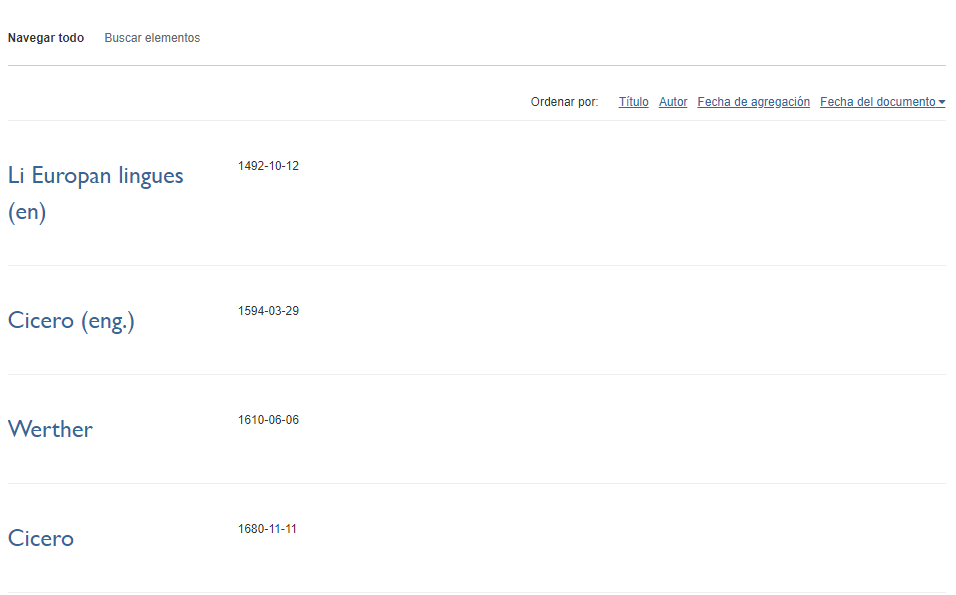
Visualizar la fecha del documento en la navegación
Edición de la plantilla “default”
Si tienes instalada la plantilla predeterminada no encontrarás el archivo items\browse en el fichero del tema. Para realizar la edición deberás buscar el archivo \application\views\scripts\items\browse.php. Sigue los pasos indicados anteriormente y tendrás los mismos resultados.
Editar el Core de Omeka
En ocasiones será necesario modificar un poco más que la plantilla de Omeka para adaptarla a las necesidades de nuestro proyecto.
Cambiar entre tipos de elemento y colecciones
Los tipos de elementos sirven para describir objetos diferenciables, en tanto las colecciones sirven para agrupar elementos sin importar el objeto asociado. Así, una colección denominada “administración de justicia” puede agrupar textos, expedientes judiciales, cartas, fotografías, personas, etc. Si hubiese un tipo de elemento que quisiera agrupar todos los documentos relacionados con la administración de justicia tendría que crear demasiados descriptores como para que fuese funcional.
Por ejemplo, al construir el repositorio de fuentes para mi investigación doctoral, agrupé bajo la categoría “Reales cédulas y órdenes” a este tipo de documentos. El problema es que construí con ello una colección que agrupa una variopinta cantidad de decisiones que afectaban el comercio, la administración de justicia, la policía, la fiscalidad, etc.
Corregir este problema no es sencillo ya que la plataforma no tiene una opción que convierta colecciones en tipos de elemento o viceversa. La opción más simple para solventar este problema consiste en “actualizar” la tabla que relaciona los elementos con sus colecciones y tipos: omeka_items.
Para ello solamente necesitamos los identificadores de la colección y del tipo de elemento. Supongamos que la colección “reales cédulas” está identificada con el número 2 (/admin/collections/show/2) y el tipo de elemento “legislación” con el número 18 (/admin/item-types/show/18). Vamos a asociar todos los elementos de la colección 2 al tipo de elemento 18.
Vamos a phpMyAdmin y desde la base de datos de Omeka entramos a la tabla omeka_items. Al entrar, encontraremos una tabla con ocho columnas, para este ejercicio sólo nos interesan las tres primeras. id es el identificador de cada elemento, item_type_id corresponde al tipo de elemento y collection_id a la colección a la que está asociada dicha entrada. En nuestro ejemplo, el elemento 1 está asociado con el tipo de elemento 1, que corresponde a “texto” y a la colección 2, “reales cédulas”.
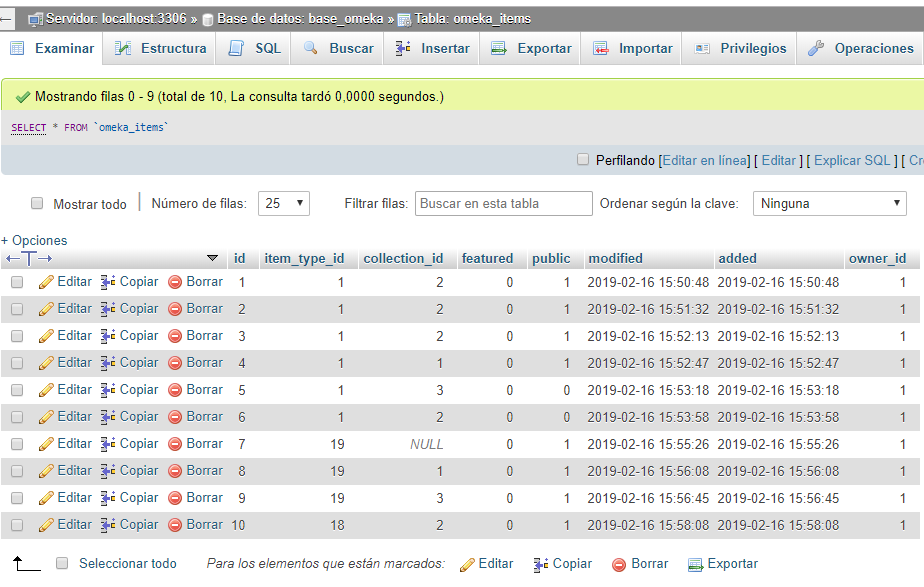
tabla omeka_items
Ahora, vamos a la pestaña SQL y desde allí ejecutamos lo siguiente:
UPDATE `omeka_items`
SET `item_type_id` = 18
WHERE `collection_id` = 2
Lo que le estamos diciendo a la consola es que queremos actualizar la columna item_type_id con el valor 18 en la tabla omeka_items en las filas donde el valor de la colección sea igual a 2. Si todo salió correctamente se imprimirá un mensaje indicando cuántas filas fueron afectadas y la tabla se habrá actualizado.
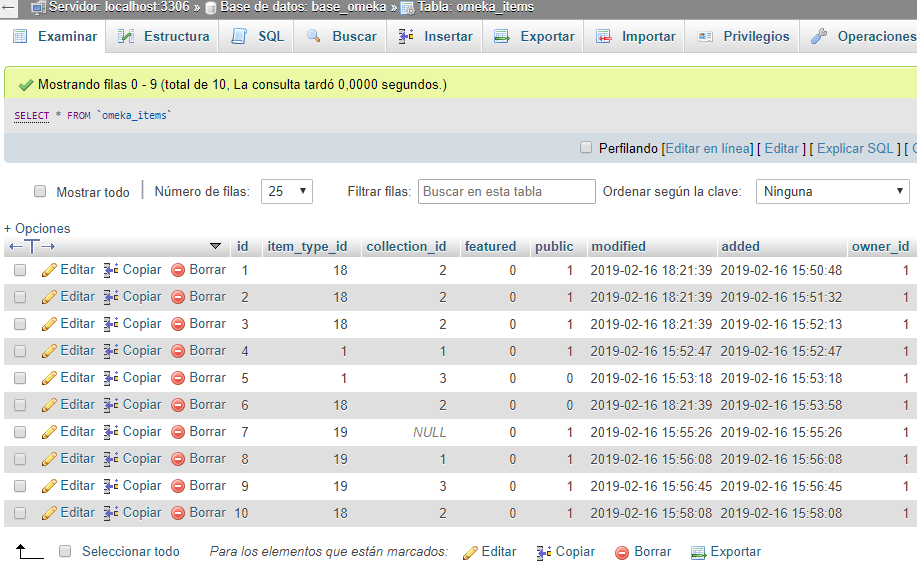
resultado edición tabla
Si entendemos la lógica de este script podemos hacer la operación inversa. Digamos que ahora queremos que los elementos agrupados en “legislación” sean incluidos en la colección 3, que hemos denominado “Nueva colección”. Solamente tendremos que modificar el orden de las variables así:
UPDATE `omeka_items`
SET `collection_id` = 3
WHERE `item_type_id` = 18
La tabla habrá sido modificada, de tal manera que el elemento 1 ahora estará asociado al tipo de elemento 18 y la colección 3.
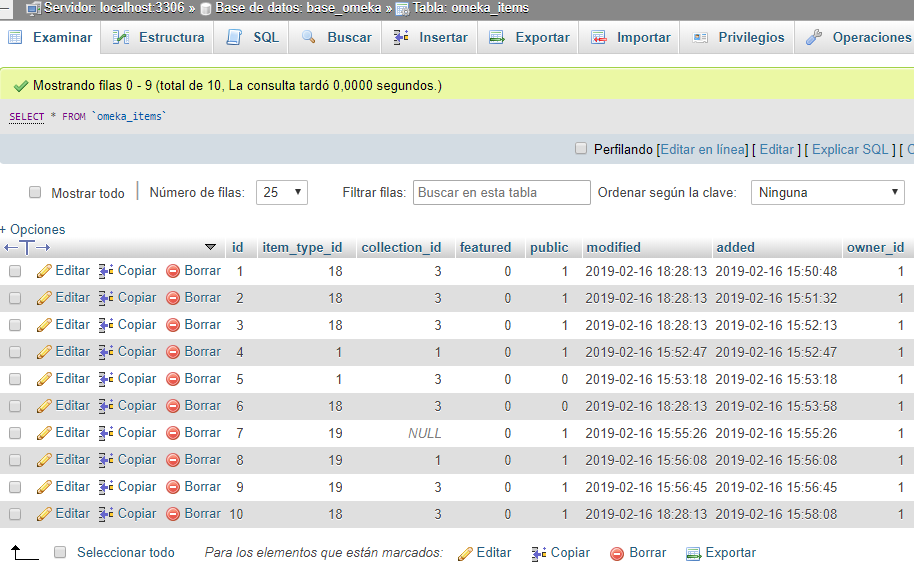
resultado edición tabla
Ten cuidado al actualizar los registros de no olvidar la cláusula WHERE. Si lo olvidas se actualizarán TODOS los registros de esa columna.
En ciertas plataformas diferentes a phpMyAdmin puede requerirse el añadir un punto y coma (;) al final del código. Si marca un error de sintáxis es posible que se deba a eso.
Editar el “DublinCore”
Aunque no se recomienda modificar el esquema de metadatos Dublin Core y sea preferible personalizar los tipos de elementos y sus descriptores, es posible que por las necesidades específicas del proyecto se quiera agregar un descriptor al formulario inicial de cada elemento. Para mi caso personal, quise ingresar un campo denominado “capítulo” al formulario principal porque al agrupar la información por colecciones sólo me permitía asociar un elemento a una colección. De esta manera, podía crear un campo donde un elemento pudiera estar asociado a dos o más secciones de mi proyecto doctoral.
El procedimiento en sí es bastante sencillo. En primer lugar, hay que entender cómo se relacionan los elementos y los estándares de metadatos. Como se muestra en la imagen, en la tabla omeka_elements_sets se define el estándar de metadatos, en este caso DublinCore, en tanto omeka_elements incluye cada uno de los elementos del estándar, por ejemplo “título”, “descripción”, “autor”, “contribuidor”, etcétera. Modificar cualquiera de estos elementos creará de inmediato un error al momento de desplegar el formulario para crear un nuevo ítem por lo que la mejor estrategia es crear un nuevo elemento en el estándar de metadatos.
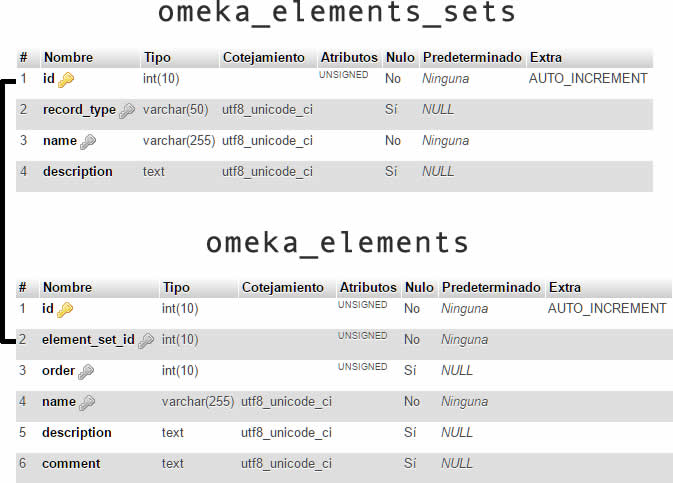
relación de los datos del Dublin Core
Para ingresar un nuevo elemento vamos a recurrir nuevamente a SQL y phpMyAdmin, pero esta vez utilizaremos la condición INSERT INTO.
INSERT INTO
`omeka_elements`(`id`, `element_set_id`,`order`,`name`, `description`,`comment`)
VALUES(NULL,'1',NULL,'Capítulo','El número y tema del capítulo al que le sirve este elemento',NULL);
De este modo, ya estará disponible la opción “capítulo” en el formulario principal.
Nueva opción en el formulario principal
A modo de cierre
En esta lección nos enfocamos en los requisitos básicos para construir un repositorio de fuentes primarias con Omeka desde una instalación local. Aprendiste a instalar y desinstalar componentes, identificar los archivos del programa, y entender un poco más la base de datos. También habrás tenido una probadita de cómo editar los archivos escritos en PHP y modificar la base de datos con SQL. Además de buenas prácticas para el ingreso de la información para que sea consistente y fácilmente recuperable. Ahora la labor queda en tus manos, ingresa información y experimenta con la plataforma para que descubras las potencialidades y limitaciones de Omeka.
Notas
-
Esta lección se probó en la versión 2.6.1. (02/05/2018). En caso de tener una instalación anterior a Omeka 2.x se recomienda actualizar según las instrucciones del manual de usuario. ↩
-
Un video que explica la instalación del software puede consultarse en https://www.youtube.com/watch?v=h6DEDm7C37A. ↩
-
La ventana de gestión de servidores (manage servers) en Linux muestra la opción de activar el servidor
ProFTPD. Como Omeka se ejecuta con Apache no es necesario iniciarlo. ↩ -
En Bitnami de manera predeterminada el usuario de phpMyAdmin será “root” y la contraseña será la que fue solicitada en la instalación de la máquina virtual. ↩
-
Es recomendable que antes de iniciar una tarea de traducción completa de la plataforma se consulte el sitio oficial del proyecto de traducción de omeka en Transifex. ↩
-
Hasta enero de 2018 era común utilizar el “Escher” como complemento para instalar “plugins” con un sólo clic en Omeka Classic, sin embargo, las modificaciones en el registro y publicación de plugins (además de algunos problemas de la versión 1.0.1) lo eliminaron del listado oficial de Omeka. En el momento su mantenimiento corre a cargo de Daniel Berthereau (Daniel-KM en GitHub) y se puede clonar desde https://github.com/Daniel-KM/Omeka-plugin-Escher.git. ↩
-
En caso de no estar familiarizado con el uso de Git o Github te recomendamos revisar la lección Introducción al control de versiones con GitHub Desktop de Daniel van Strien. ↩
-
También es posible modificar el orden predeterminado con el plugin DefaultSort. Cualquier método que se use no afecta el ejercicio aquí presentado. ↩
