Conteúdos
- Objetivos do Módulo
- Para Quem isso é Útil?
- Aplicando nosso Conhecimento Histórico
- A Investigação Avançada no OBO
- Entendendo Queries de URL
- Fazendo o Download de Ficheiros Sistematicamente
- Fazendo o Download das Páginas de Resultados de Busca
- Leituras Adicionais
Objetivos do Módulo
Fazer o download de um único registro de um website é fácil, mas fazer o download de vários registros de uma vez - uma necessidade cada vez mais frequente para um historiador - é muito mais eficiente usando uma linguagem de programação como o Python. Nesta lição, escreveremos um programa que fará o download de uma série de registros do Old Bailey Online usando critérios de investigação personalizados e irá armazená-los num diretório no nosso computador. Esse processo envolve interpretar e manipular Query Strings de URL. Nesse caso, o tutorial buscará fazer o download de fontes que contenham referências a afrodescendentes que foram publicadas no Old Bailey Proceedings entre 1700 e 1750.
Para Quem isso é Útil?
Automatizar o processo de download de registros de uma base de dados online será útil para qualquer um que trabalhe com fontes históricas armazenadas online de forma ordenada e acessível e que deseje salvar cópias dessas fontes no seu próprio computador. É particularmente útil para alguém que deseja fazer o download de vários registros específicos, em vez de apenas um punhado. Caso deseje fazer o download de todos ou da maioria dos registros de uma base de dados em particular, pode achar o tutorial de Ian Milligan sobre Automated Downloading with WGET mais adequado.
O presente tutorial permitirá que faça download de forma isolada e discriminada de registros específicos que atendam às suas necessidades. Fazer o download de múltiplas fontes de forma automática economiza um tempo considerável. O que faz com as fontes baixadas depende dos seus objetivos de investigação. Pode desejar criar visualizações ou realizar uma série de métodos de análise de dados, ou simplesmente reformatá-las para facilitar a navegação. Ou pode desejar apenas manter uma cópia de backup para poder acessá-las sem acesso à internet.
Essa lição é voltada para usuários de Python com nível intermediário. Caso ainda não tenha tentado as lições do Básico de Programação em Python, pode achá-las um ponto de partida útil.
Aplicando nosso Conhecimento Histórico
Nesta lição, estamos tentando criar o nosso próprio corpus de casos relacionados com pessoas afrodescendentes. A partir do caso de Benjamin Bowsey no Old Bailey em 1780, podemos notar que “black” pode ser uma palavra-chave útil para usarmos para localizar outros casos envolvendo réus de ascendência africana. No entanto, quando buscamos por black no website do Old Bailey, percebemos que esta palavra às vezes se refere a outros usos: black horses ou black cloth. A tarefa de desambiguar esse uso da linguagem terá que esperar por outra lição. Por enquanto, vamos nos voltar para casos mais fáceis. Como historiadores, provavelmente, podemos pensar em palavras-chave de termos historicamente racializados relacionados com afrodescendentes as quais valeria a pena buscar. A infame “n-word”, é claro, não é útil, já que esse termo não era comumente utilizado até meados do século XIX. Outras expressões racializadas como “negro” e “mulatto” são, porém, muito mais relevantes para o início do século XVIII. Essas palavras-chave são menos ambíguas do que “black” e são muito mais propensas a serem referências imediatas a pessoas no nosso público-alvo. Se testarmos esses dois termos em buscas separadas simples no Old Bailey website, temos resultados como nessa captura de tela:
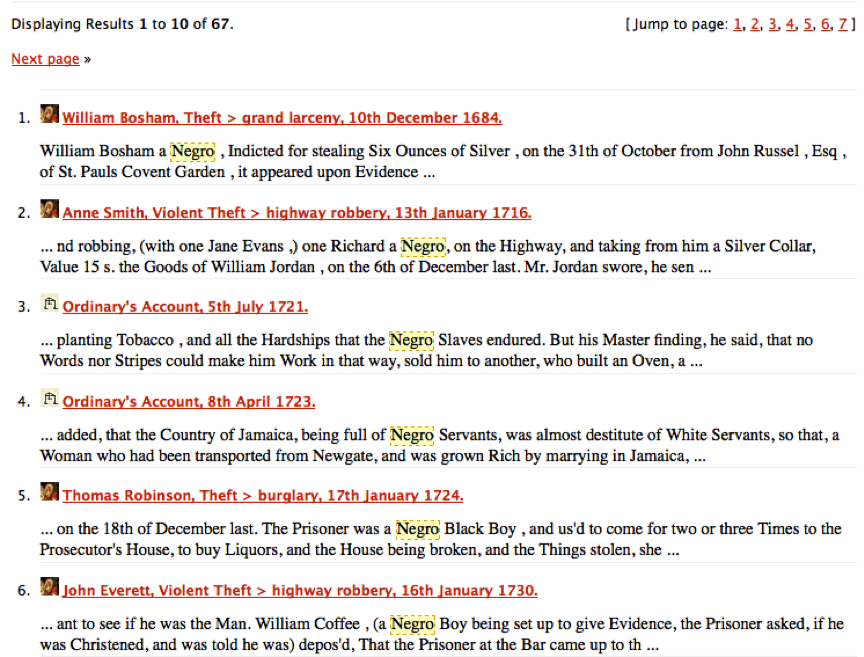
Resultados de investigação para ‘negro’ no Old Bailey Online

Resultados de investigação para ‘mulatto’ no Old Bailey Online
Depois de examinar estes resultados de busca, parece evidente que são referências a pessoas e não a cavalos, panos ou qualquer outra coisa que seja preta. Desejamos fazer o download de todas para usar na nossa análise. Poderíamos, é claro, fazer o download de uma por uma manualmente. Mas vamos encontrar uma maneira programática de automatizar essa tarefa.
A Investigação Avançada no OBO
As ferramentas de pesquisa de cada site funcionam de maneira diferente. Embora as pesquisas funcionem de forma semelhante, as complexidades das pesquisas numa base de dados podem não ser totalmente óbvias. Portanto, é importante pensar criticamente sobre as opções de busca de uma base de dados e, quando disponível, ler a documentação fornecida pelo website. Investigadores de história prudentes sempre interrogam suas fontes; os procedimentos por trás das suas caixas de pesquisa devem receber a mesma atenção. O formulário de busca avançada do Old Bailey Online permite refinar as suas buscas com base em dez campos diferentes, incluindo palavras-chave simples, um intervalo de datas e um tipo de crime. Como as ferramentas de busca de cada website são diferentes, vale sempre a pena reservar um momento ou dois para testar e ler a respeito das opções de investigação disponíveis. Uma vez que já fizemos buscas simples por “negro” e “mulatto”, sabemos que haverá resultados. No entanto, vamos usar a busca avançada para limitar os nossos resultados aos registros publicados no Old Bailey Proceedings que dizem respeito a julgamentos apenas de 1700 até 1750. É claro que pode alterá-lo para o que desejar, mas isso tornará o exemplo mais simples de ser acompanhado. Faça a busca mostrada na imagem abaixo. Certifique-se de que marcou o botão “Advanced” e incluiu as wildcards * para incluir entradas pluralizadas ou com um “e” extra no final.
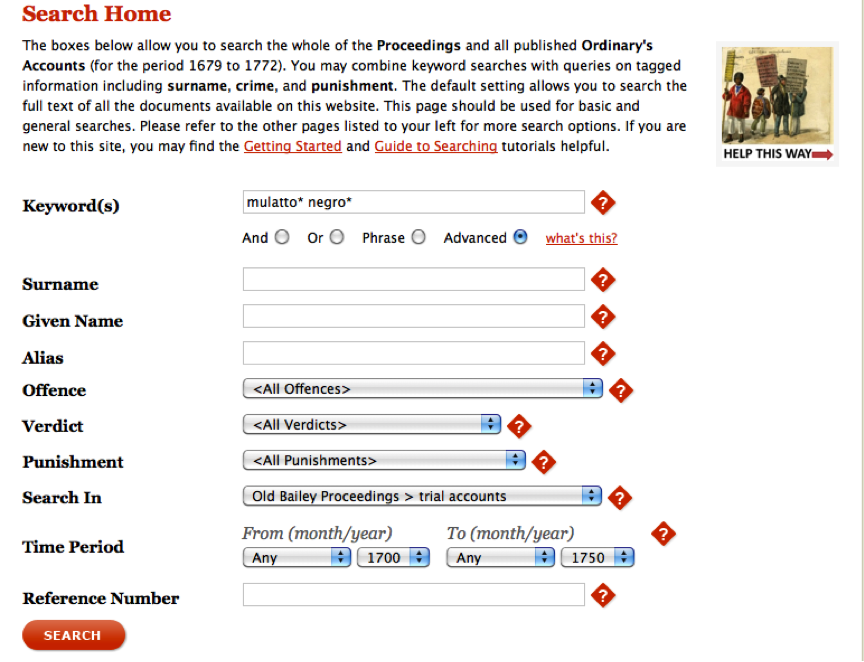
Exemplo de Busca Avançada no Old Bailey
Execute a busca e depois clique no link “Calculate Total” para ver quantas entradas existem. Agora temos 13 resultados (caso tenha um número diferente, volte e certifique-se de que copiou o exemplo acima da forma exata). O que queremos fazer neste ponto é o download de todos esses ficheiros de julgamento e analizá-los mais profundamente. Mais uma vez, para apenas 13 registros, também pode fazer o download de cada registro manualmente. Mas à medida que mais e mais dados são disponibilizados online, torna-se mais comum a necessidade de baixar 1.300 ou até 130.000 registros, caso no qual o download individual dos registros se torna impraticável e entender como automatizar o processo se torna muito valioso. Para automatizar o processo, precisamos de dar um passo atrás e lembrar como as URLs de busca são criadas no Old Bailey website, um método comum para muitas bases de dados online e websites.
Entendendo Queries de URL
Observe a URL produzida com a última página de resultado de busca. Ela deve se parecer com isso:
https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext=mulatto*+negro*&kwparse=advanced&_divs_div0Type_div1Type=sessionsPaper_trialAccount&fromYear=1700&fromMonth=00&toYear=1750&toMonth=99&start=0&count=0
Vimos sobre URLs em Noções básicas de páginas web e HTML, mas isso parece muito mais complexo. Ainda que mais longo, não é verdadeiramente muito mais complexo. Mas é mais fácil de entender observando como os nossos critérios de busca são representados na URL.
https://www.oldbaileyonline.org/search.jsp
?gen=1
&form=searchHomePage
&_divs_fulltext=mulatto*+negro*
&kwparse=advanced
&_divs_div0Type_div1Type=sessionsPaper_trialAccount
&fromYear=1700
&fromMonth=00
&toYear=1750
&toMonth=99
&start=0
&count=0
Nessa visão, vemos com mais clareza as 12 informações importantes que precisamos para realizar a nossa busca (uma por linha). Na primeira há a URL base do Old Bailey website, seguida por uma query “?” (não se preocupe com o bit gen=1; os desenvolvedores do Old Bailey Online dizem que ele não faz nada) e uma série de 10 pares nome/valor unidos por caracteres &. Juntos, esses 10 pares de nome/valor compõem a query string (expressão de busca), que informa ao mecanismo de busca quais variáveis usar em etapas específicas da investigação. Observe que cada par nome/valor contém um nome de variável: toYear e, em seguida, atribui a essa variável um valor: 1750. Isso funciona exatamente da mesma forma que os Argumentos de Função, passando certas informações para variáveis específicas. Nesse caso, a variável mais importante é _divs_fulltext=, para a qual foi dado o valor:
mulatto*+negro*
Esta contém o termo que digitamos na caixa de busca. O programa adicionou automaticamente um sinal de soma + no lugar de um espaço em branco (URLs não podem conter espaçamentos); dito de outro modo, isso é exatamente o que pedimos que o site do Old Bailey encontrasse. As outras variáveis carregam valores que nós também definimos. fromYear e toYear contém o nosso intervalo de datas. Já que nenhum ano possui 99 meses, como sugerido na variável toMonth, podemos assumir que esse seja o modo através do qual o algoritmo garante que todos os registros daquele ano são incluídos. Não há regras difíceis ou rápidas para descobrir o que cada variável faz, porque a pessoa que criou o site as nomeou. Muitas vezes pode fazer uma suposição razoável. Todos os campos de busca possíveis na página de busca avançada possuem os seus próprios pares nome/valor. Caso deseje descobrir o nome da variável de modo a que possa utilizá-la, faça uma nova busca e certifique-se de colocar um valor no campo no qual está interessado. Após submeter a sua busca, verá o seu valor e o nome associado a ele como parte da URL da página dos resultados de busca. Com o Old Bailey Online, assim como com noutros websites, o formulário de busca (avançada ou não) ajuda, essencialmente, a construir URLs que informam à base de dados o que está buscando. Se puder entender como os campos de busca estão representados no URL - o que geralmente é algo bem direto -, então torna-se relativamente simples construir esses URLs programaticamente e automatizar o processo de download de registros.
Agora tente alterar o start=0 para start=10 e pressione enter. Deve agora ter os resultados 11-13. A variável start informa ao website qual a entrada que deve ser mostrada no início da lista de resultados de busca. Nós devemos ser capazes de utilizar esse conhecimento para criar uma série de URLs que nos permitirão fazer o download de todos os 13 ficheiros. Vamos nos voltar para isso agora.
Fazendo o Download de Ficheiros Sistematicamente
Na lição Download de Páginas Web com Python, aprendemos que o Python pode fazer o download de uma página web desde que tenhamos a URL. Naquela lição, usamos a URL para fazer o download da transcrição do julgamento de Benjamin Bowsey. Nesse caso, estamos tentando fazer o download de múltiplas transcrições de julgamentos que atendem aos critérios de busca descritos acima sem precisar executar o programa repetidamente. Ao invés disso, queremos um programa que faça o download de tudo de uma vez. Neste ponto, temos a URL para a página de resultados de busca que contém as 10 primeiras entradas na nossa investigação. Também sabemos que ao mudarmos o valor de start na URL, podemos sequencialmente chamar cada uma das páginas de resultados de busca e finalmente recuperar todos os ficheiros de julgamento que elas possuem. É claro que os resultados de busca não nos oferecem os ficheiros do julgamento em si, mas apenas links para eles. Então precisamos de extrair esses links para os registros subjacentes dos resultados de busca. No Old Bailey Online website, as URLs para os registros individuais (os ficheiros de transcrição de julgamento) podem ser encontrados como links na página de resultados de busca. Sabemos que todas as transcrições de julgamento possuem um id de julgamento que assume a forma: “t” seguido por, pelo menos, 8 números (ex.: t17800628-33). Ao buscar links que contenham esse padrão, podemos identificar URLs de transcrição de julgamento. Como em lições anteriores, vamos desenvolver um algoritmo de modo a que possamos começar a enfrentar esse problema de uma maneira que o computador possa lidar. Parece que a tarefa pode ser realizada em 4 passos. Precisaremos:
- Gerar as URLs para cada página de resultados de busca incrementando a variável
startnuma quantidade fixa um número apropriado de vezes. - Fazer o download de cada página de resultados de busca como um ficheiro HTML.
- Extrair os URLs de cada transcrição de julgamento (usando o ID do julgamento como descrito acima) de cada ficheiro HTML de resultados de busca.
- Percorrer essas URLs extraídas para baixar cada transcrição de avaliação e salvá-las num diretório no nosso computador.
Perceberá que isso é razoavelmente similiar às tarefas que realizamos em Download de Páginas Web com Python e De HTML para Lista de Palavras (parte 2). Primeiro, fazemos o download e, então, analisamos as informações que procuramos. E, nesse caso, fazemos mais alguns downloads.
Fazendo o Download das Páginas de Resultados de Busca
Primeiro, precisamos de gerar as URLs para fazer o download de cada página de resultados de busca. Já temos a primeira usando a forma do próprio website.
https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext=mulatto*+negro*&kwparse=advanced&_divs_div0Type_div1Type=sessionsPaper_trialAccount&fromYear=1700&fromMonth=00&toYear=1750&toMonth=99&start=0&count=0
Poderíamos escrever essa URL duas vezes e alterar a variável start para obter todas as 13 entradas, mas vamos escrever um programa que funcionaria independentemente de quantas páginas de resultados de busca ou registros precisássemos de fazer download, não importando o que decidíssemos investigar. Estude esse código e, depois, adicione essa função ao seu módulo chamado obo.py (crie um ficheiro com esse nome e armazene-o no diretório onde deseja trabalhar). Os comentários no código destinam-se a ajudá-lo a decifrar as várias partes.
# obo.py
def getSearchResults(query, kwparse, fromYear, fromMonth, toYear, toMonth):
import urllib.request
startValue = 0
# cada parte do URL. Dividido para facilitar a leitura
url = 'https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext='
url += query
url += '&kwparse=' + kwparse
url += '&_divs_div0Type_div1Type=sessionsPaper_trialAccount'
url += '&fromYear=' + fromYear
url += '&fromMonth=' + fromMonth
url += '&toYear=' + toYear
url += '&toMonth=' + toMonth
url += '&start=' + str(startValue)
url += '&count=0'
# faz o download da página e armazena o resultado
response = urllib.request.urlopen(url)
webContent = response.read().decode('UTF-8')
filename = 'search-result'
f = open(filename + ".html", 'w')
f.write(webContent)
f.close
Nessa função, separamos os vários componentes da Query String e usamos Argumentos de Função para que a função possa ser reutilizada além dos nossos objetivos específicos atuais. Quando chamarmos por essa função, substituiremos os argumentos pelos valores que desejamos buscar. Depois, fazemos o download das páginas dos resultados de busca de maneira similiar a como foi feito em Download de Páginas Web com Python. Agora, crie um novo ficheiro: download-searches.py e copie o código a seguir dentro dele. Observe: os valores que passamos como argumentos são exatamente os mesmos dos utilizados no exemplo acima. Sinta-se livre para testá-los para receber resultados diferentes ou ver como funcionam.
#download-searches.py
import obo
query = 'mulatto*+negro*'
obo.getSearchResults(query, "advanced", "1700", "00", "1750", "99")
Quando executar esse código, deve encontrar um novo ficheiro: search-result.html no seu diretório programming-historian contendo a primeira página dos resultados de busca da sua investigação. Certifique-se de que o download foi realizado apropriadamente e apague o ficheiro. Vamos adaptar o nosso programa para fazer o download da outra página contendo as outras 3 entradas ao mesmo tempo, assim queremos ter certeza que obteremos as duas. Vamos refinar a nossa função getSearchResults adicionando outro argumento de função chamado entries, de modo a que possamos dizer ao programa quantas páginas de resultados de busca precisamos fazer o download. Usaremos o valor das entradas e matemática simples para determinar quantas páginas de resultado de busca existem. Isso é algo bastante direto uma vez que sabemos que há dez transcrições de julgamento listadas por página. Podemos calcular o número de páginas de resultados de busca dividindo o valor das entradas por 10. Armazenaremos esse resultado na variável chamada pageCount. Ela se parecerá com isso:
# determina quantos ficheiros precisam ser baixados
pageCount = entries / 10
No entanto, em casos em que o número de entradas não é um múltiplo de 10, isso resultará num número decimal. Pode testá-lo executando esse código no seu Terminal (Mac & Linux) / Linha de Comandos Python (Windows) e exibindo o valor mantido em pageCount. (Observe que, daqui em diante, usaremos a palavra Terminal para referir esse programa).
entries = 13
pageCount = entries / 10
print(pageCount)
-> 1.3
Sabemos que a contagem do número de página deve ser 2 (uma página contendo as entradas 1-10 e uma página contendo as entradas 11-13). Uma vez que sempre queremos o maior inteiro mais próximo, podemos arredondar o resultado da divisão.
# determina quantos ficheiros precisam ser baixados
import math
pageCount = entries / 10
pageCount = math.ceil(pageCount)
Se adicionarmos isso à nossa função getSearchResults abaixo da linha startValue=0, agora o código é capaz de calcular o número de páginas cujo download precisa de ser realizado. No entanto, nesta etapa ele irá fazer somente o download da primeira página, já que informamos à seção de download da função para executar somente uma vez. Para corrigir isso, podemos adicionar o código de download a um for loop que fará o download uma vez para cada número na variável pageCount. Caso ele leia 1, fará o download uma vez; caso ele leia 5, fará o download cinco vezes e assim por diante. Imediatamente após o if statement que acabou de escrever, adicione a linha a seguir e indente tudo antes de f.close com um espaçamento adicional de modo que tudo fique dentro do for loop:
for pages in range(1, pageCount+1):
print(pages)
Uma vez que isso é um for loop, todo o código que desejamos executar repetidamente também precisa de ser planejado. Pode-se certificar de que fez isso corretamente verificando o código finalizado no exemplo abaixo. Esse loop aproveita a função range do Python. Para entender esse for loop é melhor, provavelmente, pensar em pageCount igual a 2 como no exemplo. Portanto, essas duas linhas de código significam: comece a executar com um valor de loop inicial 1 e, a cada vez que executar, adicione uma unidade a esse valor. Quando o valor do loop é o mesmo de pageCount, executa mais uma vez e para. Isso é particularmente valioso porque significa que podemos dizer ao nosso programa para executar exatamente uma vez para cada página de resultados de busca e oferece uma nova habilidade flexível para controlar quantas vezes um for loop é executado. Caso deseje praticar essa nova e poderosa maneira de escrever loops, pode abrir o seu Terminal e brincar.
pageCount = 2
for pages in range(1, pageCount+1):
print(pages)
-> 1
-> 2
Antes de adicionar todo esse código à nossa função getSearchResults, temos que fazer dois ajustes finais. No final do for loop (mas ainda dentro do loop) e depois que o nosso código de download for executado, precisamos de mudar nossa variável startValue, que é usada na construção da URL da página que desejamos fazer o download. Se nos esquecermos de fazer isso, o nosso programa fará repetidamente o download da primeira página de resultados de busca, já que não estamos verdadeiramente mudando nada na URL inicial. A variável startValue, como discutido acima, é o que controla em que página de resultados de busca desejamos fazer o download. Portanto, podemos solicitar a próxima página de resultados de busca incrementando o valor de startvalue em 10 unidades depois que o download inicial for concluído. Caso não tenha certeza de onde adicionar essa linha, pode espiar adiante o código finalizado no exemplo abaixo.
Finalmente, queremos garantir que os nomes do ficheiros que fizemos o download são diferentes entre si. De outro modo, cada download será armazenado em cima do download anterior, deixando apenas um único ficheiro de resultados de busca. Para resolver isso, podemos ajustar os conteúdos da variável filename para incluir o valor armazenado em startValue de modo que a cada vez que fizermos o download de uma nova página, ela recebe um nome diferente. Já que a variável startValue é um inteiro, precisaremos de convertê-la para uma string antes de adicioná-la à variável filename. Ajuste a linha no seu programa que pertence à variável filename para ficar assim:
filename = 'search-result' + str(startValue)
Agora deve ser capaz de adicionar essas novas linhas de código à sua função getSearchResults. Lembre-se de que fizemos as adições a seguir:
- Adicionar
entriescomo um argumento de função adicional logo depois detoMonth - Calcular o número de páginas de resultados de pesquisa e adicionar isso imediatamente após a linha que começa com
startValue = 0(antes de construirmos a URL e começarmos o download) - Imediatamente após isso, adicione um
forloop que informará ao programa para executar uma vez para cada página de resultados de busca, e indentar o resto do código de modo a que ele esteja dentro do novo loop - A última linha no
forloop deve agora incrementar o valor da variávelstartValuea cada vez que o loop é executado - Ajustar a variável
filenameexistente de modo que a cada vez que for feito o download de uma página de resultados de busca ela forneça um nome único ao ficheiro.
A função finalizada no seu ficheiro obo.py deve-se parecer com isso:
# cria URLs para páginas de resultados de busca e armazena os ficheiros.
def getSearchResults(query, kwparse, fromYear, fromMonth, toYear, toMonth, entries):
import urllib.request, math
startValue = 0
# isso é novo! determina quantos ficheiros precisam ser baixados.
pageCount = entries / 10
pageCount = math.ceil(pageCount)
# essa linha é nova!
for pages in range(1, pageCount +1):
# cada parte do URL. Dividido para facilitar a leitura.
url = 'https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext='
url += query
url += '&kwparse=' + kwparse
url += '&_divs_div0Type_div1Type=sessionsPaper_trialAccount'
url += '&fromYear=' + fromYear
url += '&fromMonth=' + fromMonth
url += '&toYear=' + toYear
url += '&toMonth=' + toMonth
url += '&start=' + str(startValue)
url += '&count=0'
# faz o download da página e salva o resultado.
response = urllib.request.urlopen(url)
webContent = response.read().decode('UTF-8')
filename = 'search-result' + str(startValue)
f = open(filename + ".html", 'w')
f.write(webContent)
f.close
# essa linha é nova!
startValue = startValue + 10
Para executar essa nova função, adicione o argumento extra ao download-searches.py e execute o programa novamente:
#download-searches.py
import obo
query = 'mulatto*+negro*'
obo.getSearchResults(query, "advanced", "1700", "00", "1750", "99", 13)
Ótimo! Agora temos as duas páginas de resultados de busca, chamadas search-result0.html e search-result10.html. Mas antes de seguirmos para o próximo passo do algoritmo, vamos cuidar de algumas “tarefas de organização”. O nosso diretório programming-historian rapidamente se tornará difícil de controlar se fizermos o download de múltiplas páginas de resultados de busca e transcrições de julgamento. Vamos fazer com que o Python crie um novo diretório nomeado a partir dos nossos termos de busca.
Desejamos adicionar essa nova funcionalidade em getSearchResults, de modo que os downloads das nossas páginas de resultados de busca sejam direcionadas a diretórios com o mesmo nome da nossa query de busca. Isso manterá o nosso diretório programming-historian mais organizado. Para fazê-lo, criaremos um novo diretório usando a biblioteca os, abreviação de “operating system” (sistema operacional). Essa biblioteca contém uma função chamada makedirs que, não surpreendentemente, cria um novo diretório. Pode testar usando o Terminal:
import os
query = "meuNovoDiretório"
if not os.path.exists(query):
os.makedirs(query)
Esse programa irá verificar se o seu computador já possui um diretório com esse nome. Caso não possua, agora deve possuir um diretório chamado meuNovoDiretório no seu computador. Num Mac provavelmente está localizado no seu diretório /Users/username/, e no Windows deve ser capaz de encontrá-lo no diretório Python no seu computador, o mesmo no qual abriu o programa da linha de comandos. Se isso funcionou, pode deletar o diretório do seu disco rígido, já que isso foi só uma prática. Uma vez que desejamos criar um novo diretório nomeado a partir da query que inserimos no Old Bailey Online website, vamos usar diretamente esse argumento de função query da função getSearchResults. Para fazer isso, importe a biblioteca os após as outras e, depois, adicione o código que acabou de escrever imediatamente abaixo. A sua função getSearchResults deve agora se parecer com isso:
# cria URLs para páginas de resultados de busca e armazena os ficheiros.
def getSearchResults(query, kwparse, fromYear, fromMonth, toYear, toMonth, entries):
import urllib.request, math, os
# Essa linha é nova! Cria um novo diretório.
if not os.path.exists(query):
os.makedirs(query)
startValue = 0
# Determina quantos ficheiros precisam ser baixados.
pageCount = entries / 10
pageCount = math.ceil(pageCount)
for pages in range(1, pageCount +1):
# cada parte do URL. Dividido para facilitar a leitura.
url = 'https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext='
url += query
url += '&kwparse=' + kwparse
url += '&_divs_div0Type_div1Type=sessionsPaper_trialAccount'
url += '&fromYear=' + fromYear
url += '&fromMonth=' + fromMonth
url += '&toYear=' + toYear
url += '&toMonth=' + toMonth
url += '&start=' + str(startValue)
url += '&count=0'
# faz o download da página e salva o resultado.
response = urllib.request.urlopen(url)
webContent = response.read().decode('UTF-8')
# armazena o resultado num novo diretório.
filename = 'search-result' + str(startValue)
f = open(filename + ".html", 'w')
f.write(webContent)
f.close
startValue = startValue + 10
O último passo para essa função é garantir que, quando salvarmos as nossas páginas de resultados de busca, as armazenaremos nesse novo diretório. Para fazer isso, podemos fazer um pequeno ajuste à variável filename de modo a que o ficheiro termine no lugar certo. Há muitas formas de o fazer e a mais fácil é simplesmente adicionar o nome do novo diretório mais uma barra no nome do ficheiro:
filename = query + '/' + 'search-result' + str(startValue)
Caso o seu computador esteja executando o Windows, precisará de uma barra invertida em vez da barra do exemplo acima. Adicione a linha acima à sua função getSearchResults no lugar da descrição atual do filename.
Se estiver executando o Windows, é provável que o seu programa downloadSearches.py falhe quando o executar porque está tentando criar um diretório com um * nele. O Windows não gosta disso. Para resolver esse problema podemos usar expressões regulares para remover qualquer caractere não compatível com o Windows. Usamos expressões regulares anteriormente em Contagem de Frequências de Palavras com Python. Para remover caracteres não-alfanuméricos da query, primeiro importe a biblioteca de expressões regulares imediatamente após importar a biblioteca os e, depois, use a função re.sub() para criar uma nova string chamada cleanQuery que contém apenas caracteres alfanuméricos. Depois precisará de substituir cleanQuery como a variável usada nas declarações de os.path.exists(), os.makedirs() e filename.
import urllib.request, math, os, re
cleanQuery = re.sub(r'\W+', '', query)
if not os.path.exists(cleanQuery):
os.makedirs(cleanQuery)
...
filename = cleanQuery + '/' + 'search-result' + str(startValue)
A versão final da sua função deve-se parecer com isso:
# cria URLs para páginas de resultados de busca e armazena os ficheiros.
def getSearchResults(query, kwparse, fromYear, fromMonth, toYear, toMonth, entries):
import urllib.request, math, os, re
cleanQuery = re.sub(r'\W+', '', query)
if not os.path.exists(cleanQuery):
os.makedirs(cleanQuery)
startValue = 0
# Determina quantos ficheiros precisam ser baixados
pageCount = entries / 10
pageCount = math.ceil(pageCount)
for pages in range(1, pageCount +1):
# cada parte do URL. Dividido para facilitar a leitura.
url = 'https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext='
url += query
url += '&kwparse=' + kwparse
url += '&_divs_div0Type_div1Type=sessionsPaper_trialAccount'
url += '&fromYear=' + fromYear
url += '&fromMonth=' + fromMonth
url += '&toYear=' + toYear
url += '&toMonth=' + toMonth
url += '&start=' + str(startValue)
url += '&count=0'
# faz o download da página e salva o resultado.
response = urllib.request.urlopen(url)
webContent = response.read().decode('UTF-8')
filename = cleanQuery + '/' + 'search-result' + str(startValue)
f = open(filename + ".html", 'w')
f.write(webContent)
f.close
startValue = startValue + 10
Dessa vez dizemos ao programa para fazer o download dos julgamentos e armazená-los num novo diretório ao invés do nosso diretório programming-historian. Execute o programa download-searches.py mais uma vez para se certificar de que ele funcionou e que entendeu como armazenar os ficheiros num diretório particular usando Python.
Fazendo o Download das Entradas de Julgamento Individuais
A este ponto, criamos uma função que é capaz de fazer o download de todos os ficheiros HTML de resultados de busca a partir do website Old Bailey Online para uma busca avançada que definimos e desenvolvemos de forma programática. Agora o próximo passo do algoritmo: extrair as URLs de cada transcrição de julgamento dos ficheiros HTML de resultados de busca. Nas lições que precedem esta (ex.: Download de Páginas Web com Python), trabalhamos com as versões para exibição das transcrições dos julgamentos e continuaremos a fazer isso. Sabemos que a versão de exibição do julgamento de Benjamin Bowsey está localizada na URL:
http://www.oldbaileyonline.org/print.jsp?div=t17800628-33
Da mesma forma que alterar as query strings nas URLs gera resultados de busca diferentes, alterar a URL dos registros de julgamento - no caso, substituir um ID de julgamento por outro - nos fará obter a transcrição para aquele novo julgamento. Isso significa que, para encontrar e fazer o download dos 13 ficheiros que buscamos, tudo o que precisamos são esses IDs de julgamento. Uma vez que sabemos que essas páginas de resultados de busca geralmente contém um link para as páginas descritas, há uma boa chance de que consigamos encontrar esses links integrados ao código HTML. Se formos capazes de raspar essa informação das páginas de resultados de busca em que fizemos download, podemos então usar essa informação para gerar uma URL que nos permitirá fazer o download de cada transcrição de julgamento. Essa é uma técnica que irá utilizar para a maioria das páginas de resultados de busca, não só o Old Bailey Online! Para fazer isso, primeiro precisamos encontrar onde os IDs de julgamento estão no código HTML dos ficheiros que fizemos o download e, depois, determinar uma maneira de isolá-los consistentemente usando código de modo a que, independentemente de qual página de resultado de busca fizermos o download, sejamos capazes de encontrar as transcrições de julgamento. Primeiro, abra search-results0.html no Komodo Edit e dê uma olhada na lista de julgamentos. A primeira entrada começa com “Anne Smith”, então pode usar o recurso find no Komodo Edit para pular imediatamente para o lugar certo. Observe que o nome de Anne faz parte de um link:
browse.jsp?id=t17160113-18&div=t17160113-18&terms=mulatto*_negro*#highlight
Perfeito, o link contém o ID do julgamento! Percorra as entradas restantes e verá que isso é verdade em todos os casos. Para nossa sorte, o site é bem formatado e parece que cada link começa com browse.jsp?id= seguido pelo ID do julgamento e termina com um &, no caso de Anne: browse.jsp?id=t17160113-18&. Podemos escrever algumas linhas de código que sejam capazes de isolar esses IDs. Veja a função a seguir. Essa função também usa a biblioteca os, nesse caso para listar todos os ficheiros localizados no diretório criado na seção anterior. A biblioteca os possui uma gama de funções úteis que imitam os tipos de tarefas que esperaria ser capaz de fazer com o seu mouse no Mac Finder ou Windows, como abrir, fechar, criar, deletar e mover ficheiros e diretórios, e é uma boa biblioteca a ser masterizada - ou pelo menos para se familiarizar.
def getIndivTrials(query):
import os, re
cleanQuery = re.sub(r'\W+', '', query)
searchResults = os.listdir(cleanQuery)
print(searchResults)
Crie e execute um novo programa chamado extract-trials-ids.py com o código a seguir. Certifique-se de inserir o mesmo valor nos argumentos da query como fez no exemplo anterior:
import obo
obo.getIndivTrials("mulatto*+negro*")
Se tudo correu bem, deve ver uma lista contendo o nome de todos os ficheiros no seu novo diretório mulatto*+negro*, que a essa altura devem ser as duas páginas de resultados de busca. Certifique-se de que isso funcionou antes de prosseguir. Uma vez que armazenamos todas as páginas de resultados de busca com um nome de ficheiro que inclui search-results, agora desejamos abrir todos os ficheiros cujo nome contenha search-results e extrair todos os IDs de julgamento encontrados neles. Nesse caso sabemos que temos 2, mas desejamos que o nosso código seja o mais reutilizável possível (com razão, é claro!). Restringir essa ação a ficheiros denominados search-results significará que este programa funcionará como pretendido, mesmo que o diretório contenha muitos outros ficheiros não relacionados, já que o programa ignorará qualquer coisa com nome diferente.
Adicione o código a seguir à sua função getIndivTrials(), que verificará se cada ficheiro contém search-results no seu nome. Em caso verdadeiro, o ficheiro será aberto e o conteúdo será salvo na variável chamada text. Essa variável text será analisada na busca por um ID de julgamento, que sabemos que sempre segue browse.jsp?id=. Se e quando o ID de julgamento for encontrado, ele será armazenado numa lista e exibido na Saída de Comando, que nos deixa com todas as informações que precisamos para então escrever o programa que fará o download dos julgamentos desejados.
def getIndivTrials(query):
import os, re
cleanQuery = re.sub(r'\W+', '', query)
searchResults = os.listdir(cleanQuery)
urls = []
# encontra as páginas de resultados de busca.
for files in searchResults:
if files.find("search-result") != -1:
f = open(cleanQuery + "/" + files, 'r')
text = f.read().split(" ")
f.close()
# busca os IDs de julgamento.
for words in text:
if words.find("browse.jsp?id=") != -1:
# isola o ID
urls.append(words[words.find("id=") +3: words.find("&")])
print(urls)
Essa última linha do for loop pode parecer confusa, mas certifique-se de que entendeu antes de seguir em frente. A variável words é verificada para saber se contém os caracteres id= (sem aspas), que obviamente se referem a um ID específico de transcrição de julgamento. Caso contenha, usamos o método de string slice para capturar apenas o trecho entre id= e & e o adicionamos à lista de url. Se soubéssemos as posições exatas dos índices dessa substring, poderíamos ter usado esses valores numéricos no lugar. No entanto, ao utilizar o método de string find(), criamos um programa muito mais flexível. O código a seguir faz exatamente a mesma coisa que essa última linha, mas de maneira menos condensada:
idStart = words.find("id=") + 3
idEnd = words.find("&")
trialID = words[idStart: idEnd]
urls.append(trialID)
Ao executar novamente o programa extract-trial-ids.py, deve ver uma lista de todos os IDs de julgamento. Podemos adicionar algumas linhas extra para transformá-los em URLs propriamente ditos e fazer o download de toda a lista para o nosso novo diretório. Também vamos usar a biblioteca time para pausar o nosso programa por 3 segundos entre cada download - uma técnica chamada throttling (em português, estrangulamento). É considerada uma boa forma de não sobrecarregar o servidor de alguém com muitas solicitações por segundo; e o pequeno retardamento torna mais fácil que todos esses ficheiros sejam, de fato, baixados ao invés de ocorrer um time out. Adicione o código a seguir ao final da sua função getIndivTrials(). Esse código vai gerar uma URL para cada página individualmente, fará o download da página no seu computador, irá colocá-lo no seu diretório, armazenar o ficheiro e pausar por 3 segundos antes de continuar para o próximo julgamento. Todo esse trabalho está contido num for loop e será executado uma vez para cada julgamento na sua lista de urls.
def getIndivTrials(query):
#...
import urllib.request, time
# importa funções python built-in para criar caminhos de ficheiro.
from os.path import join as pjoin
for items in urls:
# gera a URL.
url = "http://www.oldbaileyonline.org/print.jsp?div=" + items
# faz o download da página.
response = urllib.request.urlopen(url)
webContent = response.read().decode('UTF-8')
# cria o nome do ficheiro e coloca-o no novo diretório.
filename = items + '.html'
filePath = pjoin(cleanQuery, filename)
# armazena o ficheiro.
f = open(filePath, 'w')
f.write(webContent)
f.close
# pausa por 3 segundos.
time.sleep(3)
Se unirmos tudo numa única função, ela deve-se parecer com isso (note que adicionamos todas as chamadas por import no início para manter as coisas claras):
def getIndivTrials(query):
import os, re, urllib.request, time
# importa funções python built-in para criar caminhos de ficheiro.
from os.path import join as pjoin
cleanQuery = re.sub(r'\W+', '', query)
searchResults = os.listdir(cleanQuery)
urls = []
# encontra páginas de resultados de busca.
for files in searchResults:
if files.find("search-result") != -1:
f = open(cleanQuery + "/" + files, 'r')
text = f.read().split(" ")
f.close()
# busca por IDs de julgamento.
for words in text:
if words.find("browse.jsp?id=") != -1:
# isola o id
urls.append(words[words.find("id=") +3: words.find("&")])
# novo daqui em diante!
for items in urls:
# gera o URL
url = "http://www.oldbaileyonline.org/print.jsp?div=" + items
# faz o download da página.
response = urllib.request.urlopen(url)
webContent = response.read().decode('UTF-8')
# cria o nome do ficheiro e coloca-o no novo diretório.
filename = items + '.html'
filePath = pjoin(cleanQuery, filename)
# armazena o ficheiro.
f = open(filePath, 'w')
f.write(webContent)
f.close
# pausa por 3 segundos.
time.sleep(3)
Vamos adicionar a mesma pausa de três segundos à nossa função getSearchResults para ser amigável aos servers do Old Bailey Online:
# cria URLs para páginas de resultados de busca e armazena os ficheiros.
def getSearchResults(query, kwparse, fromYear, fromMonth, toYear, toMonth, entries):
import urllib.request, math, os, re, time
cleanQuery = re.sub(r'\W+', '', query)
if not os.path.exists(cleanQuery):
os.makedirs(cleanQuery)
startValue = 0
# Determina quantos ficheiros precisam de ser baixados.
pageCount = entries / 10
pageCount = math.ceil(pageCount)
for pages in range(1, pageCount +1):
# cada parte da URL. Dividida para facilitar a leitura.
url = 'https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext='
url += query
url += '&kwparse=' + kwparse
url += '&_divs_div0Type_div1Type=sessionsPaper_trialAccount'
url += '&fromYear=' + fromYear
url += '&fromMonth=' + fromMonth
url += '&toYear=' + toYear
url += '&toMonth=' + toMonth
url += '&start=' + str(startValue)
url += '&count=0'
# faz o download da página e armazena o resultado.
response = urllib.request.urlopen(url)
webContent = response.read().decode('UTF-8')
filename = cleanQuery + '/' + 'search-result' + str(startValue)
f = open(filename + ".html", 'w')
f.write(webContent)
f.close
startValue = startValue + 10
# pausa por 3 segundos.
time.sleep(3)
Finalmente, chame a função no programa download-searches.py:
#download-searches.py
import obo
query = 'mulatto*+negro*'
obo.getSearchResults(query, "advanced", "1700", "00", "1750", "99", 13)
obo.getIndivTrials(query)
Agora criou um programa que é capaz de fazer a solicitação e o download de ficheiros do Old Bailey website, baseado em parâmetros de busca que definiu, tudo sem visitar o site!
No Caso de um Ficheiro Não Ser Baixado
Verifique se o download dos treze ficheiros foi realizado corretamente. Se esse for o caso, ótimo! No entanto, há a possibilidade de que esse programa tenha parado no meio do caminho. Isso porque o nosso programa, ao ser executado na nossa máquina, depende de dois fatores além do nosso controle imediato: a velocidade da internet e a o tempo de resposta do server do Old Bailey Online naquele momento. Uma coisa é pedir que o Python faça o download de um único ficheiro, mas quando começamos a solicitar um ficheiro a cada três segundos, há grandes chances de ocorrer um time out no server ou que ele falhe em nos enviar o ficheiro que estamos buscando.
Se estivermos usando um navegador web para fazer essas solicitações, eventualmente receberíamos uma mensagem de que “a conexão expirou” ou algo do tipo. Todos nós vemos isso de tempos em tempos. No entanto, o nosso programa não foi desenvolvido para lidar ou retransmitir essas mensagens de erro, então só perceberá o problema quando o programa não tiver retornado o número esperado de ficheiros ou simplesmente não fizer nada. Para evitar frustrações e incertezas, queremos um sistema à prova de falha no nosso programa, que tentará baixar cada julgamento. Se por alguma razão ele falhar, apontaremos o problema e passaremos para o próximo julgamento.
Para fazer isso, utilizaremos os mecanismos para lidar com erros do Python, try / except, bem como uma nova biblioteca: socket. Try e Except são muito parecidos com um if / else statement. Quando solicita que o Python try (em português, tente) algo, ele tentará executar o código; caso o código falhe em alcançar o que definiu, ele executará o código em except (em português, exceção). Isso é frequentemente usado ao lidar com erros, conhecido como “error handling”. Podemos usá-lo a nosso favor dizendo ao programa para tentar fazer o download de uma página. Caso o programa falhe, solicitaremos que ele nos informe qual ficheiro falhou e depois prossiga. Para fazer isso precisamos de usar a biblioteca socket, que nos permitirá definir um limite de tempo para um download antes de seguir em frente. Isso envolve alterar a função getIndivTrials.
Primeiro, precisamos de carregar a biblioteca socket, o que deve ser feito da mesma forma que todos as outras importações de biblioteca. Depois, precisamos de importar a biblioteca urllib.error, que nos permite lidar com erros de download. Também precisamos de definir o tamanho do timeout padrão do socket - por quanto tempo desejamos tentar fazer o download de uma página antes de desistirmos. Isso deve entrar imediatamente após o comentário que começa com # faz o download da página:
import os, re, urllib.request, urllib.error, time, socket
#...
# faz o download da página.
socket.setdefaulttimeout(10)
Então, precisamos de uma nova lista de Python que armazenará todas as urls cujo download falhou. Vamos chamá-la de failedAttempts e pode inserí-la imediatamente após as instruções de importação:
failedAttempts = []
Finalmente, podemos adicionar o try / except statement de forma muito similar a como um if / else statement seria adicionado. Nesse caso, vamos colocar todo o código desenvolvido para fazer o download e armazenar os julgamentos no try statement, e no except statement vamos dizer ao programa o que desejamos que ele faça caso falhe. Aqui, vamos adicionar a url cujo download falhou à nossa nova lista, failedAttempts:
#...
socket.setdefaulttimeout(10)
try:
response = urllib2.urlopen(url)
webContent = response.read().decode('UTF-8')
# cria o nome de ficheiro e coloca-o no novo diretório "trials".
filename = items + '.html'
filePath = pjoin(newDir, filename)
# armazena o ficheiro.
f = open(filePath, 'w')
f.write(webContent)
f.close
except urllib.error.URLError:
failedAttempts.append(url)
Finalmente, diremos ao programa para exibir os conteúdos da lista na Saída de Comando de modo que saibamos quais ficheiros falharam no download. Isso deve ser adicionado nas linhas finais da função:
print("failed to download: " + str(failedAttempts))
Agora ao executarmos o programa, caso haja algum problema no download de um ficheiro específico, receberá uma mensagem na janela de Saída de Comando do Komodo Edit. Essa mensagem irá conter quaisquer URLs dos ficheiros que falharam no download. Caso haja apenas um ou dois, provavelmente é mais fácil simplesmente visitar as páginas manualmente e usar o recurso de “Salvar Como” do seu navegador. Caso se esteja sentindo aventureiro, poderia modificar o programa para automaticamente fazer o download dos ficheiros faltantes. A versão final das suas funções getSearchResults() e getIndivTrials() deve-se parecer com isso:
# cria URLs para páginas de resultados de busca e armazena os ficheiros.
def getSearchResults(query, kwparse, fromYear, fromMonth, toYear, toMonth, entries):
import urllib.request, math, os, re, time
cleanQuery = re.sub(r'\W+', '', query)
if not os.path.exists(cleanQuery):
os.makedirs(cleanQuery)
startValue = 0
# determina quantos ficheiros precisam de ser baixados.
pageCount = entries / 10
pageCount = math.ceil(pageCount)
for pages in range(1, pageCount +1):
# cada parte da URL. Dividida para facilitar a leitura.
url = 'https://www.oldbaileyonline.org/search.jsp?gen=1&form=searchHomePage&_divs_fulltext='
url += query
url += '&kwparse=' + kwparse
url += '&_divs_div0Type_div1Type=sessionsPaper_trialAccount'
url += '&fromYear=' + fromYear
url += '&fromMonth=' + fromMonth
url += '&toYear=' + toYear
url += '&toMonth=' + toMonth
url += '&start=' + str(startValue)
url += '&count=0'
# faz o download da página e salva o resultado.
response = urllib.request.urlopen(url)
webContent = response.read().decode('UTF-8')
filename = cleanQuery + '/' + 'search-result' + str(startValue)
f = open(filename + ".html", 'w')
f.write(webContent)
f.close
startValue = startValue + 10
# pausa por 3 segundos.
time.sleep(3)
def getIndivTrials(query):
import os, re, urllib.request, urllib.error, time, socket
failedAttempts = []
# importa funções python built-in para criar caminhos de ficheiro.
from os.path import join as pjoin
cleanQuery = re.sub(r'\W+', '', query)
searchResults = os.listdir(cleanQuery)
urls = []
# encontra páginas de resultados de busca.
for files in searchResults:
if files.find("search-result") != -1:
f = open(cleanQuery + "/" + files, 'r')
text = f.read().split(" ")
f.close()
# busca por IDs de julgamento.
for words in text:
if words.find("browse.jsp?id=") != -1:
#isolate the id
urls.append(words[words.find("id=") +3: words.find("&")])
for items in urls:
# gera a URL.
url = "http://www.oldbaileyonline.org/print.jsp?div=" + items
# faz o download da página.
socket.setdefaulttimeout(10)
try:
response = urllib.request.urlopen(url)
webContent = response.read().decode('UTF-8')
# cria o nome do ficheiro e coloca-o no novo diretório.
filename = items + '.html'
filePath = pjoin(cleanQuery, filename)
# armazena o ficheiro.
f = open(filePath, 'w')
f.write(webContent)
f.close
except urllib.error.URLError:
failedAttempts.append(url)
# pausa por 3 segundos.
time.sleep(3)
print("failed to download: " + str(failedAttempts))
Leituras Adicionais
Para usuários mais avançados, ou para se tornar um usuário mais avançado, pode achar que vale a pena ler sobre como alcançar esse mesmo processo usando Interfaces de Programação de Aplicações (API). Geralmente, um website com uma API dá instruções de como solicitar certos documentos. É um processo bastante similar ao que acabamos de fazer interpretando a Query String de URL, mas sem o trabalho de investigação adicional necessário para decifrar o que cada variável faz. Caso esteja interessado no Old Bailey Online, recentemente liberaram uma API e a documentação pode ajudar bastante:
- Old Bailey Online API (http://www.oldbaileyonline.org/static/DocAPI.jsp)
- Melhor maneira de criar um diretório para gravação de ficheiros, se ele não existir, usando Python? (http://stackoverflow.com/questions/273192/python-best-way-to-create-directory-if-it-doesnt-exist-for-file-write)