
Conteúdos
- Objetivos
- Antes de começar
- Obter valores de sentimentos e emoções
- Análise das emoções em um texto
- Visualizando a evolução dos sentimentos em um texto
- Outras funcionalidades e suas limitações
- Referências
- Notas
Objetivos
Esta lição usa a metodologia de análise de sentimentos e emoções através da linguagem de programação R para investigar documentos textuais de modo individual. Embora a lição não seja destinada a usuários avançados de R, é necessário que se tenha algum conhecimento dessa linguagem; assumimos que se tenha o R instalado e saiba como importar pacotes. Também recomendamos o download do RStudio. Se não estiver familiarizado com R, é melhor trabalhar primeiro através das lições Processamento básico de texto em R, Noções básicas de R com dados tabulares ou Data Wrangling and Management in R (em inglês). Ao final desta lição, o(a) pesquisador(a) será capaz de:
- Colocar perguntas de pesquisa com base na análise quantitativa de sentimentos em textos de tipo ensaístico e/ou narrativo.
- Usar a linguagem de programação R, o ambiente RStudio e o pacote
syuzhetcom o dicionário NRC para gerar o indicador de sentimento de um texto em diferentes linguagens. - Analisar criticamente os resultados do processamento de texto.
- Visualizar os dados gerais e sua evolução ao longo de um texto.
Esta lição foi construída com a versão R 4.0.2, mas acreditamos que funcionará corretamente em versões futuras do programa.
O uso do R é geralmente o mesmo para Windows, Mac e Linux. Entretanto, como vamos trabalhar com textos em português, precisaremos escrever algum código extra para indicar o formato UTF-8 em máquinas Windows. Nesses casos, o código para o sistema operacional correspondente é exibido.
Antes de começar
Análise de sentimentos
A análise dos sentimentos ou a mineração de opinião é utilizada para extrair automaticamente informações sobre a conotação negativa ou positiva da linguagem de um documento. Embora seja uma tarefa que vem sendo utilizada há muito tempo no campo do marketing ou da política, em estudos literários ainda é uma abordagem recente e não há um método único. Além disso, há a possibilidade de extrair a polaridade dos sentimentos e também das emoções.
É importante especificar o que estamos procurando com os termos “sentimento” e “emoções”, pois eles são frequentemente usados de forma intercambiável, de modo geral, mas são diferentes. Para Antonio R. Damasio, as emoções são reações corporais instigantes de nosso corpo, determinadas por estímulos ambientais e derivadas do desenvolvimento da regulamentação biológica (12). Elas podem ser divididas em primárias e secundárias. Embora não haja um acordo final sobre o número de emoções básicas, geralmente são seis: raiva, alegria, repugnância, medo, tristeza e surpresa, embora Damasio considere esta última como sendo secundária. Além disso, no caso do sistema automático que utilizaremos, as emoções secundárias de antecipação e confiança também aparecem.
Por outro lado, podemos definir sentimento como a ação e o efeito de sentir uma emoção ou, em outras palavras, é o resultado do fato de que “quando um objeto, uma pessoa, uma situação ou um pensamento provoca em nós a emoção da alegria, começa um processo que pode concluir no sentimento de estar alegre ou feliz” (Pereira Zazo 32) porque é uma emoção positiva. Durante a lição faremos uma distinção entre os dois termos, pois usaremos o resultado do sentimento para ver a sua evolução ao longo do texto e as emoções para ver o uso das palavras em geral.
Dicionário de léxicos NRC
O pacote syuzhet funciona com quatro dicionários de sentimentos: Bing, Afinn, Stanford e NRC. Nesta lição, trabalharemos com este último, pois é o único disponível em vários idiomas, incluindo o português. Este vocabulário com valores de sentimentos negativos ou positivos e oito emoções foi desenvolvido por Saif M. Mohammad, um cientista do Conselho Nacional de Pesquisa do Canadá (NRC). O conjunto de dados foi construído manualmente através de pesquisas usando a técnica Maximum Difference Scaling ou MaxDiff, que avalia a preferência por uma série de alternativas (Mohammad e Turney). Assim, o léxico tem 14.182 palavras com as categorias de sentimentos positivos e negativos e as emoções de raiva, antecipação, repugnância, medo, alegria, tristeza, surpresa e confiança. Além disso, está disponível em mais de 100 idiomas (através de tradução automática).
Seus termos de uso estabelecem que o vocabulário pode ser usado gratuitamente para fins de pesquisa, portanto, todos os dados estão disponíveis para download.
Se trabalhamos com o inglês, podemos interagir com as diferentes categorias no site do NRC Word-Emotion Association Lexicon. Lá também podemos encontrar trabalhos publicados sobre a obtenção dos valores para o vocabulário, sua organização, extensão, etc.
Pacote syuzhet
O pacote syuzhet foi desenvolvido em 2015 por Matthew Jockers; que o mantém funcionando até hoje e continuamente apresenta novas versões (no momento da preparação desta lição, foi usada a versão de dezembro de 2017). Uma série de posts no blog acompanham o desenvolvimento do pacote, e estão disponíveis no blog do professor desde 5 de junho de 2014 (em inglês).
Naturalmente, o pacote foi desenvolvido com testes em textos escritos ou traduzidos para o inglês e não sem debate sobre sua utilidade, para atribuir valores a textos literários que muitas vezes são, por natureza, bastante subjetivos.
Atenção: A lista de palavras do dicionário está sendo preparada em inglês como língua principal e os dados quantitativos atribuídos a cada palavra são o resultado da avaliação humana pelos participantes americanos. Portanto, vários fatores devem ser levados em consideração ao utilizar esta metodologia:
- O léxico em português é uma tradução direta realizada por tradução automática (estes sistemas já são muito confiáveis entre o inglês e o português, mas não em outros idiomas que o NRC afirma ser capaz de analisar como, por exemplo, o basco).
- A pontuação de cada palavra, ou seja, a valência sentimental e emocional, tem um viés cultural e temporal que deve ser levado em conta, e um termo que pareceu positivo para os participantes da pesquisa pode nos parecer negativo.
- O uso desta metodologia não é recomendado para textos que são altamente metafóricos e simbólicos.
- O método não vai captar a negação de um sentimento positivo como, por exemplo, a frase “Eu não estou feliz”.
Seguindo o espírito de adaptabilidade das lições do Programming Historian a outras línguas, foi decidido usar
syuzhetem sua forma original, mas ao final da lição indicamos algumas funções avançadas para usar seu próprio dicionário de sentimentos com o mesmo pacote.
Como os resultados nos dataframes aparecerão em inglês, se achar necessário, dedique um momento para aprender esta tradução:
| anger | anticipation | disgust | fear | joy | sadness | surprise | trust | negative | positive |
|---|---|---|---|---|---|---|---|---|---|
| raiva | anticipação | desgosto | medo | alegria | tristeza | surpresa | confiança | negativo | positivo |
Um pequeno exemplo
Antes de começar a realizar a análise de nossos textos, é útil saber de forma geral qual é o processo de análise realizado pela função de obter sentimentos de syuzhet, com o dicionário NRC e os resultados obtidos sobre os quais trabalharemos.
O sistema irá processar nosso texto e transformá-lo em um vetor de caracteres (aqui palavras), para analisá-los individualmente (também é possível fazê-lo por sentenças). Sem entrar ainda no código para realizar a análise, dê uma olhada neste breve exemplo (nota de tradução: para a versão em português foi usado o texto Dom Casmurro de Machado de Assis, mantendo o tipo de exercícios e o código da lição original):
“Contando aquela crise do meu amor adolescente, sinto uma coisa que não sei se explico bem, e é que as dores daquela quadra, a tal ponto se espiritualizaram com o tempo, que chegam a diluir-se no prazer. Não é claro isto, mas nem tudo é claro na vida ou nos livros. A verdade é que sinto um gosto particular em referir tal aborrecimento, quando é certo que ele me lembra outros que não quisera lembrar por nada.”
Dom Casmurro de Machado de Assis.
Este fragmento é transformado em um vetor de caracteres:
> print(exemplo_2)
[1] "contando" "aquela" "crise" "do" "meu"
[6] "amor" "adolescente" "sinto" "uma" "coisa"
[11] "que" "não" "sei" "se" "explico" ...
Com a função de obter sentimentos, obtém-se a valência positiva e negativa de cada palavra, assim como a valência das oito emoções classificadas pelo NRC. O resultado para este fragmento é o seguinte:
> print(sentimentos_exemplo_df, row.names = exemplo_2)
anger anticipation disgust fear joy sadness surprise trust negative positive
contando 0 0 0 0 0 0 0 0 0 0
aquela 0 0 0 0 0 0 0 0 0 0
crise 1 0 0 0 0 1 0 0 3 0
do 0 0 0 0 0 0 0 0 0 0
meu 0 0 0 0 0 0 0 0 0 0
amor 0 1 0 0 1 1 0 1 0 1
adolescente 0 0 0 0 0 0 0 0 0 0
sinto 0 0 0 0 0 0 0 0 0 0
uma 0 0 0 0 0 0 0 0 0 0
coisa 0 0 0 0 0 0 0 0 0 0
que 0 0 0 0 0 0 0 0 0 0
não 0 0 0 0 0 0 0 0 0 0
sei 0 0 0 0 0 0 0 0 0 0
se 0 0 0 0 0 0 0 0 0 0
explico 0 0 0 0 0 0 0 0 0 0
bem 0 0 0 0 0 0 0 0 0 0
...
Nota de tradução: na lição original, os autores não explicaram o passo a passo para se obter esses resultados em um primeiro momento. Apesar de a lição explicar detalhadamente o processo, julguei ser interessante demonstrar aqui como obtive esses outputs:
exemplo <- "Contando aquela crise do meu amor adolescente, sinto uma coisa que não sei se explico bem, e é que as dores daquela quadra, a tal ponto se espiritualizaram com o tempo, que chegam a diluir-se no prazer. Não é claro isto, mas nem tudo é claro na vida ou nos livros. A verdade é que sinto um gosto particular em referir tal aborrecimento, quando é certo que ele me lembra outros que não quisera lembrar por nada."
exemplo_2 <- get_tokens(exemplo)
print(exemplo_2)
sentimentos_exemplo_df <- get_nrc_sentiment(exemplo_2, lang="portuguese")
print(sentimentos_exemplo_df, row.names = exemplo_2)
Como podemos ver nos resultados deste objeto tipo data frame ou tabela, cada palavra ou ficha tem um valor padrão de 0 nas dez colunas. Se houver um valor maior que 0 significa, em primeiro lugar, que este termo existe no dicionário NRC e, em segundo lugar, que tem um valor atribuído para alguma emoção e/ou sentimento. Neste exemplo, podemos ver que a palavra “amor” é entendida de forma positiva, ainda que represente tristeza (sadness). Por outro lado, a palavra “crise” possui uma conotação negativa muito forte, pois há menos margem para dúvidas.
As possibilidades de explorar, analisar e visualizar estes resultados dependem, em grande parte, das suas habilidades de programação mas, acima de tudo, da sua questão de pesquisa. Para ajudar o pesquisador, nesta lição introdutória aprenderemos como analisar os dados utilizando várias formas de visualização.
Pergunta de pesquisa
Para essa lição, vamos utilizar o romance Dom Casmurro, escrito por Machado de Assis, publicado em 1899, de caráter realista e ambientado no Rio de Janeiro na segunda metade do século XIX. O protagonista e narrador é Bento Santiago (também conhecido como Bentinho ou Dom Casmurro), que apresenta relatos desde a sua juventude até à sua vida adulta, quando escreve. Nesse intervalo de tempo passa por experiências como viver em um seminário e se preparar para ser Padre, mas também desistir dessa vida ao se apaixonar por Capitu. O enredo central da trama é o ciúme envolvido nessa relação.
É possível observar a queda emocional desta trama ao se extrair automaticamente os valores de sentimento do romance? Ou, em outras palavras, nossa recepção dos ciúmes de Bentinho coincide com os resultados desse cálculo automático? Além disso, quais são as palavras mais usadas na descrição das emoções do texto?
Obter valores de sentimentos e emoções
Instalar e carregar pacotes
A primeira coisa que precisamos fazer para poder obter o sentimento de nosso texto, é instalar e carregar o pacote R correspondente, neste caso, o syuzhet. Além disso, para facilitar a visualização dos dados, vamos utilizar os pacotes RColorBrewer, wordcloud, tm e NLP. Para fazer isto, digite e execute os dois comandos seguintes em seu console; o primeiro para instalar o pacote e o segundo para carregá-lo (se já os tiver instalado, só precisa carregá-los). Note que a instalação destes pacotes pode levar alguns minutos.
# Instale os pacotes:
install.packages("syuzhet")
install.packages("RColorBrewer")
install.packages("wordcloud")
install.packages("tm")
# Carregue os pacotes
library(syuzhet)
library(RColorBrewer)
library(wordcloud)
library(tm)
Carregar e preparar o texto
Faça o download do texto do romance Dom Casmurro. Como podemos ver, o documento está em formato de texto simples, pois isto é essencial para realizar seu processamento e análise em R.
Com o texto em mãos, a primeira coisa que vamos fazer é carregá-lo como um objeto de string. Certifique-se de mudar o caminho para o texto para corresponder ao seu computador.
Em Mac e Linux
Em sistemas Mac podemos usar a função get_text_as_string integrada no pacote syuzhet:
texto <- get_text_as_string("https://raw.githubusercontent.com/programminghistorian/jekyll/gh-pages/assets/domCasmurro.txt")
Em Windows
Os sistemas Windows não lêem diretamente caracteres com acentos ou outras marcações típicas do espanhol, português ou francês, então temos que dizer ao sistema que o nosso texto está no formato UTF-8 usando a função scan.
texto <- scan(file = "https://raw.githubusercontent.com/programminghistorian/jekyll/gh-pages/assets/domCasmurro.txt", fileEncoding = "UTF-8", what = character(), sep = "\n", allowEscapes = T)
Como a análise que vamos realizar precisa de uma lista, seja de palavras ou de frases (aqui só prestaremos atenção a palavras individuais), precisamos de um passo intermediário entre o carregamento do texto e a extração dos valores de sentimento. Assim, vamos dividir o texto (string) em uma lista de palavras (tokens). Isto é muito comum na análise distante de textos.
Para isso, usamos a função get_tokens() do pacote e geramos um novo objeto, neste caso um vetor de tokens (palavras). Conforme veremos, com esta função nos livramos da pontuação no texto e temos uma lista de palavras.
texto_palavras <- get_tokens(texto)
head(texto_palavras)
[1] "dom" "casmurro" "texto" "de" "referência" "obras"
Agora podemos ver quantas palavras ou tokens estão neste texto com a função length():
length(texto_palavras)
[1] 66931
Se quiser realizar a análise para orações, utilize a função get_sentences() e siga o mesmo processo, com exceção da criação da nuvem de palavras:
oracoes_vetor <- get_sentences(texto)
length(oracoes_vetor)
[1] 8637
Extração de dados com o NRC Sentiment Lexicon
Agora podemos executar a função get_nrc_sentiment para obter os sentimentos no romance Dom Casmurro. Como a função executa por padrão o vocabulário inglês, nós a escrevemos com o argumento “lang” (de language, ou idioma) para usar o vocabulário português (“portuguese”). Por sua vez, criamos um novo objeto para armazenar os dados extraídos. Este será um objeto do tipo data frame. Esta função procura a presença das oito emoções e dos dois sentimentos para cada palavra em nosso vetor, e atribui um número maior que 0 se elas existirem. Dependendo do desempenho de seu computador e de acordo com as características de nosso texto, este processo pode levar de 15 a 30 minutos.
sentimentos_df <- get_nrc_sentiment(texto_palavras, lang="portuguese")
Quando o código terminar de ser executado, um aviso aparecerá porque o syuzhet usa uma função que é descontinuada dentro de sua função get_nrc_sentiment:
Warning message:
`data_frame()` is deprecated as of tibble 1.1.0.
Please use `tibble()` instead.
This warning is displayed once every 8 hours.
Call `lifecycle::last_warnings()` to see where this warning was generated.
Quando o processo terminar, se desejarmos, podemos ler os resultados no novo objeto, simplesmente selecionando o objeto e executando-o. Mas para evitar “imprimir” milhares de linhas no console, também podemos usar a função head() para ver os primeiros seis tokens. No caso do texto que estamos usando, quando executarmos essa função, devemos ver o seguinte, que não é nada interessante:
> head(sentimientos_df)
anger anticipation disgust fear joy sadness surprise trust negative positive
1 0 0 0 0 0 0 0 1 0 1
2 0 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0 0 0 0
6 0 0 0 0 0 0 0 0 0 0
Resumo do texto
O que é interessante é ver um resumo de cada um dos valores que obtivemos utilizando a função geral summary(). Isto pode ser muito útil ao comparar vários textos, pois permite ver diferentes medidas, tais como a média dos resultados para cada uma das emoções e os dois sentimentos. Por exemplo, podemos ver que o romance Dom Casmurro é, em média (mean), um pouco mais positivo (0,03892) do que negativo (0,03559). Mas se olharmos para as emoções, parece que a tristeza (0,02116) aparece em mais momentos do que a alegria (0,01593). Vários dos valores fornecidos pela função de resumo do texto aparecem com um valor igual a 0, incluindo a mediana (median). Isto indica que poucas palavras do romance aparecem no dicionário que estamos usando (NRC) ou, inversamente, que poucas têm uma atribuição de sentimento ou emoção no dicionário.
> summary(sentimentos_df)
anger anticipation disgust fear joy
Min. :0.00000 Min. :0.00000 Min. :0.000000 Min. :0.00000 Min. :0.00000
1st Qu.:0.00000 1st Qu.:0.00000 1st Qu.:0.000000 1st Qu.:0.00000 1st Qu.:0.00000
Median :0.00000 Median :0.00000 Median :0.000000 Median :0.00000 Median :0.00000
Mean :0.01116 Mean :0.01337 Mean :0.008815 Mean :0.01288 Mean :0.01593
3rd Qu.:0.00000 3rd Qu.:0.00000 3rd Qu.:0.000000 3rd Qu.:0.00000 3rd Qu.:0.00000
Max. :5.00000 Max. :2.00000 Max. :3.000000 Max. :4.00000 Max. :7.00000
sadness surprise trust negative positive
Min. :0.00000 Min. :0.000000 Min. :0.00000 Min. :0.00000 Min. :0.00000
1st Qu.:0.00000 1st Qu.:0.000000 1st Qu.:0.00000 1st Qu.:0.00000 1st Qu.:0.00000
Median :0.00000 Median :0.000000 Median :0.00000 Median :0.00000 Median :0.00000
Mean :0.02116 Mean :0.008965 Mean :0.02299 Mean :0.03559 Mean :0.03892
3rd Qu.:0.00000 3rd Qu.:0.000000 3rd Qu.:0.00000 3rd Qu.:0.00000 3rd Qu.:0.00000
Max. :4.00000 Max. :2.000000 Max. :3.00000 Max. :5.00000 Max. :7.00000
Parabéns! Já temos os resultados da análise de sentimentos! E, agora, o que podemos fazer com esses números?
Análise das emoções em um texto
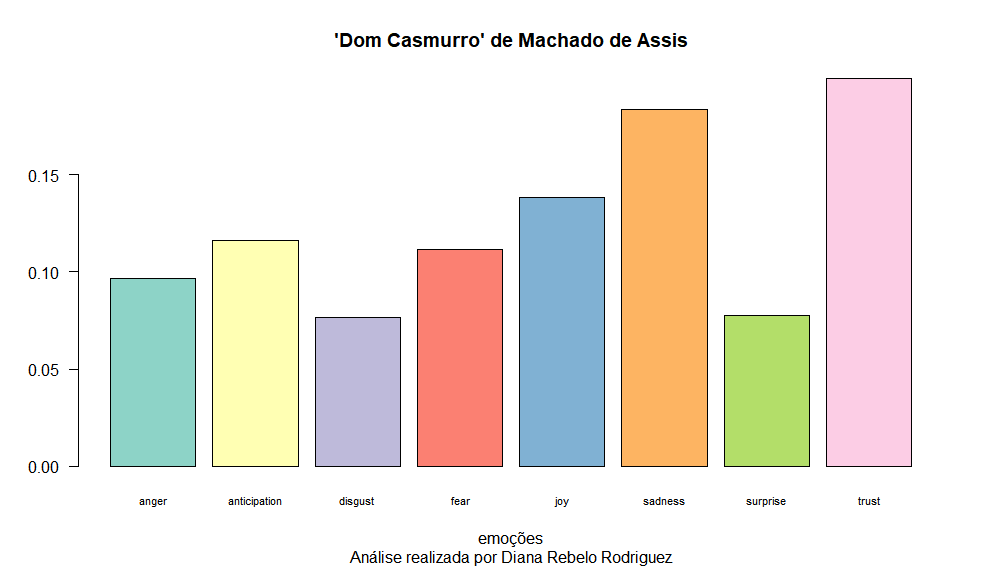
Gráfico de barras
Para ver quais as emoções que estão mais presentes no texto, a maneira mais simples é criar um barplot. Para isso, usamos a função barplot() com o resumo das colunas 1 a 8, ou seja, as colunas de raiva (anger), antecipação (antecipation), desgosto (disgust), medo (fear), alegria (joy), tristeza (sadness), surpresa (surprise) e confiança (trust). Os resultados obtidos vêm do processamento da função prop.table() dos resultados das oito colunas com cada uma das palavras da tabela.
Para cada barra, todos os valores da coluna de emoções correspondentes são somados. Então, o resultado de todas as emoções que adicionamos na saída do gráfico é somado. No final, a soma de cada emoção é dividida pelo total de todas as colunas ou emoções. Isto não acrescenta as colunas negativas e positivas. 1
barplot(
colSums(prop.table(sentimentos_df[, 1:8])),
space = 0.2,
horiz = FALSE,
las = 1,
cex.names = 0.7,
col = brewer.pal(n = 8, name = "Set3"),
main = "'Dom Casmurro' de Machado de Assis",
sub = "Análise realizada por Diana Rebelo Rodriguez",
xlab="emoções", ylab = NULL)
O resto dos parâmetros que vemos no código são “extras”, pois são uma forma de configurar o formato visual do gráfico. Assim, indicamos um espaço (space) de 0,2 entre as barras, que estará na posição vertical ao indicar falsamente (FALSE) sua horizontalidade (horiz) e, ao contrário, a horizontalidade para os valores no eixo Y com las = 1. Além disso, reduzimos o tamanho do nome de cada barra (cex.names) para 0,7 para evitar que elas desapareçam, por exemplo, se fizermos um pequeno gráfico. Graças ao pacote que instalamos no início, RColorBrewer, podemos dar cor às colunas automaticamente, neste caso, com a paleta de cores (brewer.pal) do conjunto número 3 do pacote, com oito cores, uma para cada coluna. Finalmente, vamos colocar um título e subtítulo em nosso gráfico com os parâmetros main e sub, assim como a palavra “emoções” no eixo X e nada no eixo Y.
Se esses parâmetros não forem do seu interesse, basta executar o seguinte código para obter o gráfico padrão:
barplot(colSums(prop.table(sentimentos_df[, 1:8])))
Certifique-se de que há espaço suficiente na seção de exibição de gráficos do R para poder ver os nomes de cada coluna.
Estas informações já indicam que as emoções de tristeza e confiança prevalecem mais do que as de desgosto ou surpresa. Mas quais são as palavras usadas por Machado na expressão dessa tristeza? Com que frequência cada uma aparece no romance como um todo?
Contando o número de palavras com cada emoção
A fim de realizar uma análise do texto, é muito interessante saber quais são as palavras usadas com mais frequência no texto em relação à sua identificação com cada emoção. Para isso, primeiro temos que criar um objeto de caracteres com todas as palavras que tenham um valor maior que 0 na coluna “tristeza” (sadness). Para selecionar somente essa coluna, usamos o sinal de dólar após o nome do data frame:
palavras_tristeza <- texto_palavras[sentimentos_df$sadness > 0]
O conteúdo de palavras_tristeza nos indica que esta lista não diz muito, pois retorna apenas a listagem de palavras sem maiores informações. Para obter a contagem das vezes que cada palavra relacionada à tristeza aparece no romance, geramos uma tabela do primeiro conjunto de caracteres com as funções unlist e table, que depois ordenamos em ordem decrescente (se quisermos uma ordem ascendente mudamos TRUE para FALSE); criamos um novo objeto de tipo tabela e imprimimos as primeiras 12 palavras da lista com sua frequência:
palavras_tristeza_ordem <- sort(table(unlist(palavras_tristeza)), decreasing = TRUE)
head(palavras_tristeza_ordem, n = 12)
head(palavras_tristeza_ordem, n = 12)
nada mal tarde entre
135 80 53 50
caso morte sair medo
34 34 32 23
amor pecado pena defunto
20 17 17 14
Se quisermos saber quantas palavras únicas foram relacionadas à tristeza, basta usar a função length no objeto que agora agrupa as palavras em ordem:
length(palabras_tristeza_orden)
[1] 163
Podemos repetir a mesma operação com o resto das emoções ou com aquela que nos interessa, assim como com os sentimentos positivos e negativos. Tente obter os resultados para a emoção “alegria” e compare os resultados 2.
Dependendo do tipo de análise que se deseje fazer, tal resultado é eficiente. Agora, para o propósito introdutório da lição, vamos gerar uma nuvem de palavras que ajuda a visualizar facilmente os termos associados a cada emoção (embora iremos visualizar aqui apenas quatro para facilitar a leitura).
Nuvem de emoções
A fim de gerar uma nuvem com as palavras que correspondem a cada emoção em Dom Casmurro, criaremos primeiro um vetor no qual armazenaremos todas as palavras que, nas colunas que indicamos após o símbolo $, têm um valor maior que 0. É gerado um novo objeto do tipo vetor, que contém um elemento para a lista de cada emoção.
Neste caso, devemos indicar novamente à função que temos caracteres acentuados se for uma máquina Windows.
Em Mac e Linux
nuvem_emocoes_vetor <- c(
paste(texto_palavras[sentimentos_df$sadness> 0], collapse = " "),
paste(texto_palavras[sentimentos_df$joy > 0], collapse = " "),
paste(texto_palavras[sentimentos_df$anger > 0], collapse = " "),
paste(texto_palavras[sentimentos_df$fear > 0], collapse = " "))
Em Windows
Uma vez gerado o vetor, deve convertê-lo em caracteres UTF-8 utilizando a função iconv.
nuvem_emocoes_vetor <- c(
paste(texto_palavras[sentimentos_df$sadness> 0], collapse = " "),
paste(texto_palavras[sentimentos_df$joy > 0], collapse = " "),
paste(texto_palavras[sentimentos_df$anger > 0], collapse = " "),
paste(texto_palavras[sentimentos_df$fear > 0], collapse = " "))
nuvem_emocoes_vetor <- iconv(nuvem_emocoes_vetor, "latin1", "UTF-8")
Agora que temos o vetor, criamos um corpus de palavras com quatro “documentos” para a nuvem:
nuvem_corpus <- Corpus(VectorSource(nuvem_emocoes_vetor))
Em seguida, transformamos este corpus em uma matriz termo-documento com a função TermDocumentMatrix(). Com isto, agora usamos a função as.matrix() para converter o TDM em uma matriz que, como podemos ver, lista os termos no texto com um valor maior que zero para cada uma das quatro emoções que extraímos aqui. Para ver o início desta informação, use novamente a função head:
nuvem_tdm <- TermDocumentMatrix(nuvem_corpus)
nuvem_tdm <- as.matrix(nuvem_tdm)
head(nuvem_tdm)
Docs
Terms 1 2 3 4
abismo 1 0 0 1
acidente 1 0 1 1
afligir 3 0 0 3
agonia 1 0 1 1
amargamente 1 0 1 0
amor 20 20 0 0
Agora, atribua um nome a cada um dos grupos de palavras ou documentos (Docs) em nossa matriz. Aqui vamos usar o termo em português para as colunas que selecionamos para exibir na nuvem. Mais uma vez, podemos ver a mudança feita ao executar a função head.
colnames(nuvem_tdm) <- c('tristeza', 'felicidade', 'raiva', 'confiança')
head(nuvem_tdm)
Docs
Terms tristeza felicidade raiva confiança
abismo 1 0 0 1
acidente 1 0 1 1
afligir 3 0 0 3
agonia 1 0 1 1
amargamente 1 0 1 0
amor 20 20 0 0
Finalmente, podemos visualizar a nuvem de palavras que estamos acostumados a ver na mídia ou em estudos académicos. O tamanho e a localização da palavra correspondem à sua maior ou menor ocorrência com valor emocional atribuído no texto. Primeiro, executamos a função set.seed() para que quando reproduzirmos o resultado visual seja o mesmo que o nosso (se não o fizer, será o mesmo, mas as palavras aparecerão em posições diferentes). E, para gerar a nuvem, vamos usar a função comparison.cloud do pacote wordcloud. Indicamos o objeto a representar, aqui ‘nuvem_tdm’, indicamos uma ordem não aleatória das palavras, atribuímos uma cor para cada grupo de palavras e damos tamanhos ao título e à escala geral, e atribuímos um número máximo de termos que serão exibidos.
set.seed(757) # pode ser qualquer número
comparison.cloud(nuvem_tdm, random.order = FALSE,
colors = c("green", "red", "orange", "blue"),
title.size = 1, max.words = 50, scale = c(2.5, 1), rot.per = 0.4)
O resultado deve ser semelhante à imagem abaixo, mas a localização das palavras pode ser diferente uma vez que a figura é gerada segundo o tamanho da tela:
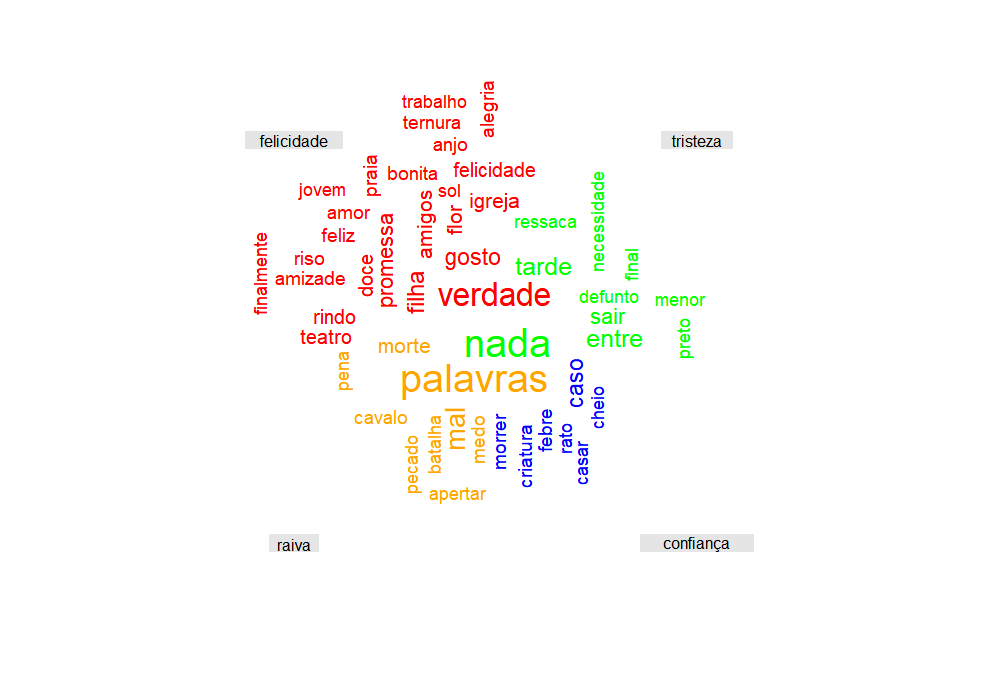
O que sugere o resultado desta nuvem? Ficamos impressionados com o aparecimento de palavras como “entre” no conjunto da tristeza e “cavalo” no conjunto da raiva. Este “disparate” está relacionado com o aviso já anunciado no início da lição. O vocabulário para análise de sentimentos que estamos usando aqui é traduzido do inglês, um tradutor automático que não é “perfeito”.
Visualizando a evolução dos sentimentos em um texto
Para complementar a leitura isolada das emoções, estudando a flutuação dos sentimentos positivos e negativos ao longo de um texto, há uma maneira de normalizar e visualizar estas informações. Como a análise da função de extração de sentimento atribui um valor positivo tanto ao sentimento positivo quanto ao negativo, precisamos gerar dados entre um intervalo de -1 para o momento mais negativo e 1 para o mais positivo, e onde 0 é neutro. Para isso, calculamos a valência do texto multiplicando os valores na coluna de valores negativos de nosso data frame com os resultados por -1 e adicionamos o valor na coluna de valores positivos.
sentimentos_valencia <- (sentimentos_df$negative * -1) + sentimentos_df$positive
Finalmente, podemos gerar um gráfico com a função simple_plot() integrada no pacote syuzhet, que nos dará duas imagens diferentes; a primeira, tem todas as medidas que o algoritmo calcula e, a segunda, é uma normalização das mesmas. O eixo horizontal apresenta o texto em 100 fragmentos normalizados e o eixo vertical nos informa sobre a valência do sentimento no texto. Dependendo das características de seu computador, este gráfico pode levar até 20-30 minutos para ser gerado.
simple_plot(sentimentos_valencia)
Assegure-se de possuir espaço suficiente no espaço de visualização de gráficos do R para que ele seja gerado. Caso contrário, aparecerá o erro: Error in plot.new() : figure margins too large
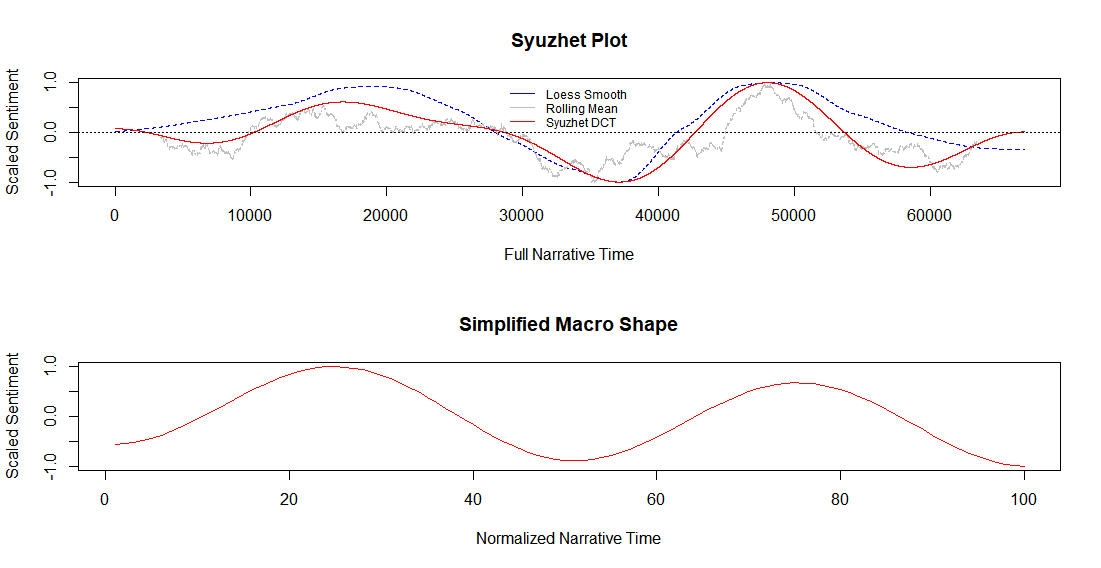
Assim, neste caso, podemos interpretar que o romance Dom Casmurro varia bastante entre momentos positivos e negativos. Começa de forma mais negativa, fica mais positivo, sendo seguido por um novo momento negativo e um segundo positivo (porém menos do que o primeiro) para um desfecho negativo. Qualquer pessoa que tenha lido o romance pode confirmar esta variação de sentimentos vivida pelo protagonista.
Salvar seus dados
Se quiser salvar seus dados para retornar a eles mais tarde, é possível fazê-lo em um ficheiro de valores separados por vírgula (CSV) com a função write.csv(). Aqui dizemos para salvar o data frame, que contém o resultado das oito emoções e os dois sentimentos de texto em um ficheiro com uma extensão .csv. Além disso, podemos acrescentar a palavra à qual cada linha de resultados corresponde, em uma coluna à esquerda usando a palavra vetor feita no início da análise.
write.csv(sentimentos_df, file = "analise_sent_domCasmurro.csv", row.names = texto_palavras)
Agora, pode começar a analisar seus próprios textos e compará-los uns com os outros!
Outras funcionalidades e suas limitações
Talvez esteja trabalhando em um projeto onde já tem um dicionário de sentimentos criado, ou talvez precise personalizar o vocabulário e sua valência sentimental por razões culturais ou temporais, ou talvez esteja procurando melhorar os resultados traduzidos automaticamente do NRC usado aqui. Em qualquer um destes casos, a partir do final de 2020, também é possível usar o seu próprio conjunto de dados no script graças à função custom e realizar algumas das operações que foram aprendidas nesta lição.
Para carregar seu próprio “dicionário de sentimentos”, é preciso primeiro criar (ou modificar) uma tabela contendo, pelo menos, uma coluna para palavras e uma coluna para sua valência, por exemplo:
| word | value |
|---|---|
| amor | 1 |
| cólera | -1 |
| tapete | 0 |
| catástrofe | -2 |
Em seguida, carregue os seus dados salvos como um CSV com a função read.csv, que criará um novo conjunto disponível como data.frame, no qual é possível verificar seu texto:
vocabulario_personalizado <- read.csv("ficheiro.csv")
method <- "custom"
sentimentos_oracoes <- get_sentiment(oracoes_vetor, method = method, lexicon = vocabulario_personalizado)
Se quiser visualizar o progresso do sentimento ao longo de seu texto, podemos usar a função plot com outros parâmetros que já vimos:
plot(sentimentos_oracoes,
type = "l",
main = "'Dom Casmurro' de Machado de Assis",
sub = "Análise realizada por Diana Rebelo Rodriguez",
xlab="emocoes", ylab = " "
)
Entretanto, tenha em mente que esta forma de análise será limitada e não será possível realizar as mesmas operações como explicado acima. Por exemplo, seguindo o modelo do exemplo, não conseguimos as informações sobre emoções, portanto não somos capazes de fazer uma nuvem de palavras.
Referências
Assis, Machado de. Dom Casmurro. São Paulo: Editora Ática, 1996.
Jockers, Matthew L. Syuzhet: Extract Sentiment and Plot Arcs from Text, 2015. https://github.com/mjockers/syuzhet
Jockers, Matthew L. “Introduction to the Syuzhet Package”, CRAN R Project, 2017. https://mran.microsoft.com/snapshot/2017-12-31/web/packages/syuzhet/vignettes/syuzhet-vignette.html
Damasio, Antonio R. El error de Descartes: La razón de las emociones. Barcelona: Andres Bello, 1999.
Mohammad, Saif, and Peter D. Turney. “Crowdsourcing a Word–Emotion Association Lexicon”. Computational intelligence 29 (2013): 436-465, doi: 10.1111/j.1467-8640.2012.00460.x
Pereira Zazo, Óscar. El analisis de la comunicación en español. Iowa: Kendal Hunt, 2015.
Rodríguez Aldape, Fernando Manuel. Cuantificación del Interés de un usuario en un tema mediante minería de texto y análisis de sentimiento. Tese de Mestrado, Universidad Autónoma de Nuevo León, 2013.