
Contenus
- Introduction
- Recherche de mots-clés en contexte
- Discussion : Faire des comparaisons significatives
- Ressources supplémentaires pour ce tutoriel
Introduction
L’analyse de corpus est un type d’analyse textuelle qui permet de faire des comparaisons d’objets textuels à grande échelle — la fameuse “lecture à distance” (distant reading). Cela nous permet de voir des choses que nous n’observons pas nécessairement lorsque nous lisons à l’oeil nu. Si vous avez une collection de documents, vous voudrez peut-être trouver des schémas grammaticaux ou les phrases récurentes dans votre corpus. Vous voudrez peut-être aussi identifier de manière statistique les expressions probables ou improbables chez un(e) auteur(e) ou dans un genre particulier, trouver des exemples spécifiques de structures grammaticales ou encore examiner beaucoup d’occurrences d’un concept particulier à travers une série de documents. L’analyse de corpus est surtout utile pour vérifier des intuitions et/ou trianguler des résultats issus d’autres méthodes digitales.
À la fin de ce tutoriel, vous serez en mesure de :
- créer et télécharger un corpus de texte
- conduire une recherche de mot-clé-en-contexte (keyword-in-context)
- identifier les schémas récurrents autour d’un mot particulier
- utiliser des requêtes de recherche plus spécifiques
- examiner les différences statistiquement significatives entre les corpus
- effectuer des comparaisons multimodales à l’aide de méthodes de linguistique de corpus
Vous avez déjà fait ce genre de choses auparavant, si vous avez déjà…
- recherché un terme spécifique dans un document .pdf ou .doc
- utilisé Voyant Tools pour analyser des schémas dans un texte
- suivi les tutoriels d’introduction à Python du Programming Historian
En quelque sorte, Voyant Tools est une passerelle vers la réalisation d’analyses plus sophistiquées et reproductibles, car l’esthétique de bricolage des scripts Python ou R peut ne pas convenir à tout le monde. AntConc comble ce vide en étant un logiciel autonome d’analyse linguistique de textes, disponible gratuitement pour Windows, Mac OS et Linux. Par ailleurs, il est régulièrement mis à jour par son créateur, Laurence Anthony. Il existe d’autres logiciels de concordance, mais AntConc est librement disponible sur toutes les plateformes et très bien maintenu. Voir la bibliographie pour d’autres ressources.
Ce tutoriel explore différentes façons d’aborder un corpus de textes. Il est important de noter que les approches issues de la linguistique de corpus sont rarement, voire jamais, l’unique possibilité. Ainsi, à chaque étape, il vaut la peine de réfléchir à ce que vous faites et comment cela peut vous aider à répondre à une question spécifique avec vos données. Bien que je présente dans ce tutoriel une approche modulaire qui explique ‘comment faire ceci puis cela pour atteindre x’, il n’est pas toujours nécessaire de suivre l’ordre exact décrit ici. Cette leçon donne un aperçu de certaines des méthodes disponibles, plutôt qu’une recette du succès.
Téléchargements nécessaires
-
Logiciel : AntConc. Dézippez le fichier si nécessaire, et lancez l’application. Les captures d’écran ci-dessous peuvent varier légèrement par rapport à la version que vous avez (et selon le système d’exploitation, bien sûr), mais les procédures sont plus ou moins les mêmes sur les plateformes et les versions récentes d’AntConc. Ce tutoriel a recours à une version plus ancienne d’AntConc, car je la trouve plus facile à utiliser dans un contexte d’introduction. Vous pouvez utiliser la version la plus récente, mais si vous souhaitez suivre avec les captures d’écran fournies, vous pouvez télécharger la version utilisée ici, version 3.2.4.
-
Corpus test : Téléchargez un fichier zip de critiques de films.
Les grandes lignes de ce tutoriel :
- Travailler avec des fichiers texte brut
- L’interface utilisateur d’AntConc, importer un corpus
- Recherche de mot-clé-en-contexte (keyword-in-context)
- Fonctions avancées de mot-clé-en-contexte (keyword-in-context)
- Cooccurrences et listes de mots
- Comparer des corpus
- Discussion : Faire des comparaisons significatives
- Ressources supplémentaires
Travailler avec des fichiers texte brut
- AntConc fonctionne avec des fichiers texte brut avec l’extension .txt (ex. : Hamlet.txt).
- AntConc ne lira pas les fichiers en .doc, .docx, .pdf. Vous allez devoir convertir ces fichiers en .txt.
- Il lira les fichiers XML qui sont enregistrés en tant que fichiers .txt (ce n’est pas grave si vous ne savez pas ce qu’est un fichier XML).
Visitez votre site Web d’actualités préféré, et cliquez sur un article (peu importe lequel, pourvu qu’il s’agisse principalement de texte). Sélectionnez tout le texte de l’article (en-tête, signature, etc.), et faites un clic droit sur “copier”.
Ouvrez un éditeur de texte tel que Notepad (sous Windows) ou TextEdit (sous Mac) et collez votre texte.
D’autres options gratuites pour les éditeurs de texte, telles que Notepad++ (Windows) ou TextWrangler (Mac), offrent des fonctionnalités plus avancées, et sont particulièrement utiles pour le nettoyage de texte. Par nettoyage de texte, j’entends la suppression des informations extratextuelles qui apparaissent régulièrement tout au long du texte. Si vous conservez cette information, elle va influencer vos données. Ainsi, les logiciels d’analyse de texte traiteront ces mots dans le compte de mots, les analyses statistiques et les relations lexicales. Par exemple, vous pouvez supprimer les en-têtes et pieds de page standards qui apparaîtront sur chaque page. Voir le tutoriel “Nettoyer ses données avec OpenRefine” pour plus d’informations sur la façon d’automatiser cette tâche. Sur des corpus plus petits, il peut être plus facile de le faire vous-même, et vous aurez une bien meilleure idée de l’allure de votre corpus de cette façon.
Enregistrez l’article en tant que fichier .txt sur le bureau. Vous pouvez faire un petit nettoyage de texte pour enlever d’autres informations, telles que le titre ou l’auteur(e) (supprimez-les, puis enregistrez de nouveau le fichier). Rappelez-vous que tout ce que vous laissez dans le fichier peut et sera traité comme du texte par un logiciel d’analyse de texte.
Allez sur votre bureau et vérifiez que vous pouvez trouver votre fichier texte.
Répétez la procédure plusieurs fois et c’est ainsi que vous construirez un corpus de fichiers texte brut. Ce processus s’appelle la construction de corpus, ce qui implique très souvent d’aborder des questions d’échantillonnage, de représentativité et d’organisation. Rappelez-vous, chaque fichier que vous voulez utiliser dans votre corpus doit être un fichier texte brut pour qu’AntConc puisse l’utiliser. Il est d’usage de nommer les fichiers avec le suffixe .txt pour que vous sachiez de quel type de fichier il s’agit.
Comme vous pouvez l’imaginer, il peut être assez fastidieux de constituer un corpus substantiel un fichier à la fois, surtout si vous avez l’intention de traiter un ensemble important de documents. Il est donc très courant d’utiliser l’extraction de contenus (webscraping) (en utilisant un petit programme pour télécharger automatiquement les fichiers sur le web pour vous) pour construire votre corpus. Pour en savoir plus sur les concepts et les techniques d’extraction, consultez les tutoriels du Programming Historian sur l’extraction avec Beautiful Soup et le téléchargement automatique avec wget (en anglais). Plutôt que de construire un corpus un document à la fois, nous allons utiliser un corpus préparé de critiques de films positives et négatives, emprunté au Natural Language Processing Toolkit. Le corpus des critiques de films de la NLTK compte 2000 critiques, organisées par résultats positifs et négatifs ; aujourd’hui, nous allons aborder un petit sous-ensemble d’entre eux (200 positifs, 200 négatifs).
La construction de corpus est un sous-domaine à part entière. Voir “Representativeness in Corpus Design”, Literary and Linguistic Computing, 8 (4) : 243-257 et Developing Linguistic Corpora : a Guide to Good Practice pour plus d’informations.
Premiers pas avec AntConc : importer un corpus, l’interface utilisateur d’AntConc
Quand AntConc sera lancé, il ressemblera à ceci.
Écran d’ouverture d’AntConc.
Sur le côté gauche, il y a une colonne (Corpus Files) qui affiche les différents fichiers chargés (que nous allons utiliser dans un instant).
Il y a 7 onglets en haut: Concordance (Concordance): Cela vous montrera ce que l’on appelle la vue mot-clé en contexte (KeyWord-In-Context, abréviation KWIC, plus d’informations à ce sujet dans une minute), en utilisant la barre de recherche en dessous. Concordance Plot (Graphe des concordances): Ceci vous montrera une visualisation très simple de votre recherche KWIC, où chaque occurence du mot recherché sera représentée par une petite ligne noire du début à la fin de chaque fichier contenant le terme. File View (Vue de fichier): Cela vous montrera une vue complète du fichier, pratique pour voir le contexte plus large d’un résultat. Clusters (Grappes): Cette vue vous montre les mots qui apparaissent souvent ensemble. Collocates (Cooccurrences): Les clusters nous montrent des mots qui apparaissent définitivement ensemble dans un corpus ; les cooccurrences (collocates) montrent des mots qui sont statistiquement susceptibles d’apparaître ensemble. Word List (Liste des mots): Tous les mots de votre corpus. Keyword List (Liste des mots-clés): Ceci permet des comparaisons entre deux corpus.
En guise d’introduction, ce tutoriel ne fait qu’effleurer la surface de ce que vous pouvez faire avec AntConc. Nous nous concentrerons sur les fonctions Concordance, Collocates, Keywords et Word List.
Chargement des corpus
Comme pour ouvrir un fichier ailleurs, nous allons commencer par File > Open (Ouvrir > Fichier), mais au lieu d’ouvrir UN seul fichier, nous voulons ouvrir le répertoire de tous nos fichiers. AntConc vous permet d’ouvrir des répertoires entiers, donc si vous êtes à l’aise avec ce concept, vous pouvez simplement ouvrir le dossier “All review” et passer à l’explication de l’interface, ci-dessous. Sinon, suivez les étapes suivantes.
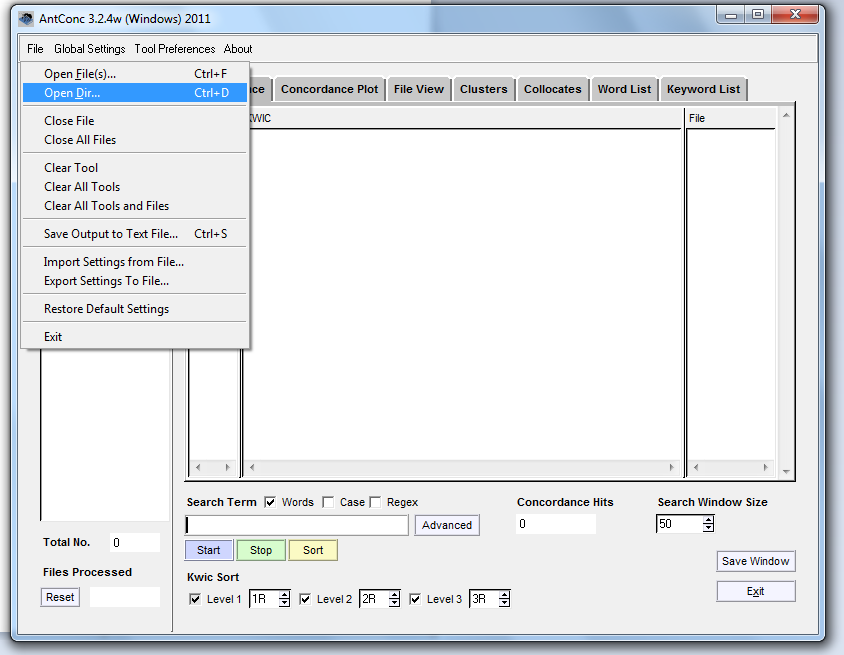
Ouvrir un répertoire de fichiers.
Rappelez-vous que nous avons mis nos fichiers sur le Bureau, alors naviguez dans le menu déroulant.
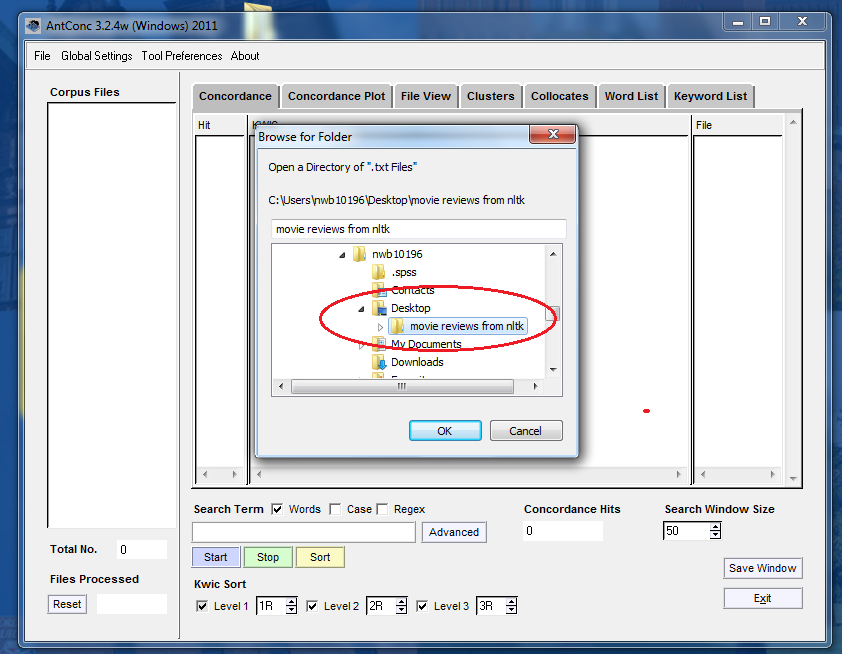
Ouvrir un répertoire de fichiers sur votre Bureau.
Depuis le Bureau, vous voulez aller vers notre dossier “movie reviews from nltk” :
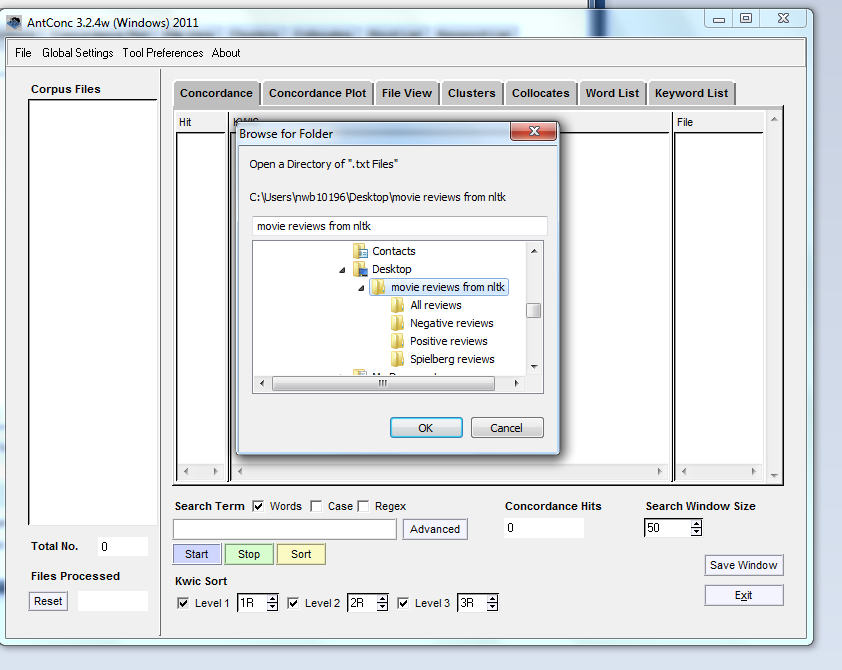
Trouvez les critiques de films.
Sélectionnez d’abord “Negative Review” et cliquez sur OK. 200 textes devraient être chargés dans la colonne de gauche nommée Corpus Files — regardez la case Total No. !
Importer les critiques négatives.
Ensuite, vous allez répéter le processus pour charger le dossier “Positive Reviews”. Vous devriez maintenant avoir 400 textes dans la colonne Corpus Files.
Importer les critiques positives.
Toutes les critiques importées.
Recherche de mots-clés en contexte
Commencez par une recherche de base
L’une des forces des outils de corpus comme AntConc, c’est de trouver des schémas de langage que nous avons du mal à identifier par une simple lecture. Les petits mots répétitifs comme le, la, les, je, il, elle, un, une, avoir, être, faire (the, I, he, he, she, a, a, an, is, have, will) sont particulièrement difficiles à suivre, parce qu’ils sont très communs, mais les ordinateurs sont très doués pour accomplir la tâche. Ces mots sont communément connus sous le nom de “mots vides” (stopwords) en humanités numériques ; ce sont souvent des marques caractéristiques d’un(e) auteur(e) ou d’un genre. Par conséquent, ils peuvent être des termes de recherche très puissants en eux-mêmes ou combinés à des termes plus axés sur le contenu, ce qui aide les chercheurs et chercheuses à identifier des tendances qui n’avaient peut-être pas été répérées.
Dans le champ de recherche en bas, tapez “the” et cliquez sur “start” (démarrer). La vue Concordance vous montrera chaque fois que le mot apparaît dans notre corpus de critiques de films, et un certain contexte pour cela. C’est ce qu’on appelle une visionneuse “mots-clés en contexte” (Key Words in Context).
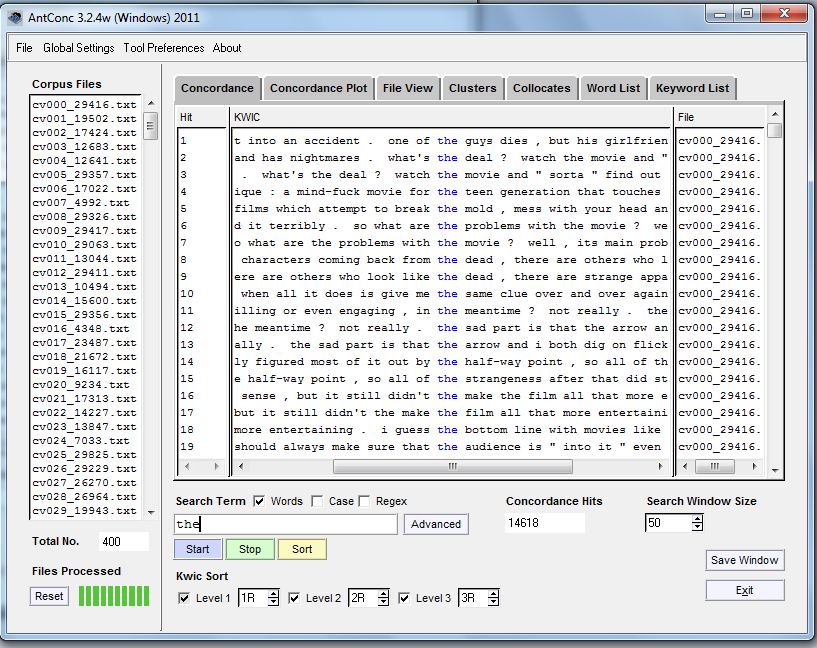
‘The’ est un mot commun.
(14618 fois, selon la case “Concordance Hits” en bas au centre qui indique le nombre d’occurrences.)
Comme ci-dessus, la liste KWIC est un bon moyen de commencer à chercher des schémas récurrents. Même s’il y a encore beaucoup d’informations, quels sont les mots qui apparaissent à proximité de “the” ?
Essayez une recherche similaire pour “a”. Les deux “a” et “the” sont des articles, mais l’un est un article défini et l’autre un article indéfini - et les résultats que vous obtiendrez vous en donneront une idée.
Maintenant que vous êtes à l’aise avec une ligne KWIC, recommencez avec le mot “shot” : vous obtiendrez des exemples à la fois du nom (“line up the shot”) et du verbe (“this scene was shot carefully”).
Que voyez-vous ? Je comprends que cela peut être difficille d’identifier des schémas. Essayez d’appuyer sur le bouton jaune “sort” (trier). Que se passe-t-il maintenant ?
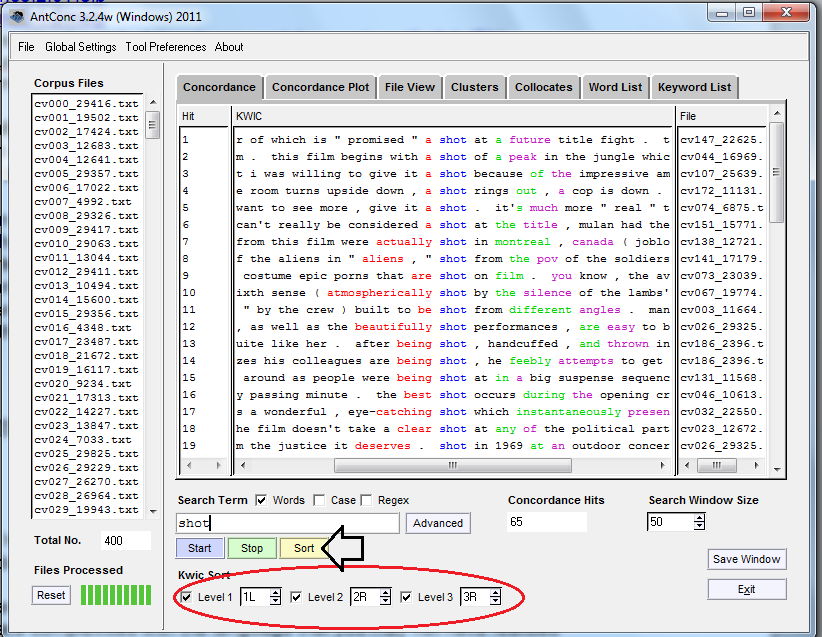
Les mots qui apparaissent près de ‘shot’.
(Ceci est peut-être plus facile à lire !) Vous pouvez ajuster la façon dont AntConc trie les informations en modifiant les paramètres dans le cercle rouge : L correspond à ‘gauche’ (pour left) et R à ‘droite’ (pour right) ; vous pouvez les étendre jusqu’à ±5 dans les deux sens. La valeur par défaut est 1 gauche, 2 droite, 3 droite, mais vous pouvez changer cela pour rechercher 3 gauche, 2 gauche, 1 droite (pour obtenir des phrases et/ou des trigrammes qui se terminent avec le terme qui vous intéresse, par exemple) en cliquant sur les boutons flèches haut ou bas. Si vous ne voulez pas inclure une option de tri, vous pouvez l’ignorer (comme par défaut : 1L, 2R, 3R) ou l’inclure comme un 0. Des options de tri moins linéaire sont disponibles, telles que 4 gauche, 3 droite, 5 droite, qui comprend beaucoup d’autres informations contextuelles. Ces paramètres peuvent être lents à réagir, mais soyez patients. Si vous n’êtes pas sûr(e) du résultat de la recherche, appuyez simplement sur “sort” (trier) pour voir ce qui s’est passé et ajuster en conséquence.
Opérateurs de recherche
L’opérateur * (métacaractère)
L’opérateur * (qui trouve zéro ou plus de caractères) peut aider, par exemple, à trouver les formes singulière et plurielle des noms.
Exercice : Recherchez “qualit*”, puis triez cette recherche. Qu’est-ce qui tend à précéder et à suivre la quality (qualité) et les qualities (qualités) ? (Indice : en anglais, ce sont des mots différents, et ils ont des contextes différents. Encore une fois, recherchez les modèles d’utilisation à l’aide du KWIC !)
Pour obtenir la liste complète des opérateurs de replacement disponibles et ce qu’ils signifient, allez à Global Settings > Wildcard Settings (Paramètres globaux > Paramètres des métacaractères)
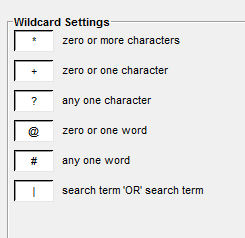
Réglage des paramètres des métacaractères.
Pour connaître la différence entre * et ?, recherchez “th*n” et “th?n”. Ces deux requêtes de recherche se ressemblent beaucoup, mais donnent des résultats très différents.
L’opérateur ? est plus spécifique que l’opérateur * : “wom?n+” - à la fois “woman” (femme) et “women” (femmes) “m?n” - “man” (homme) et “men” (hommes), mais aussi “min” comparativement “m*n” n’est pas utile, parce que vous allez avoir “mean”, “melon”, etc.
Exercice : Comparez ces deux recherches : “wom?n” et “m?n”
- Triez chaque recherche de façon significative (par exemple par terme de recherche puis 1L puis 2L)
- Puis, cliquez sur File > Save output to text file (Enregistrer les résultats dans un fichier texte)
ASTUCE : Au cours de vos recherches, vous pouvez générer de nombreux fichiers de ce type pour référence ; il est utile d’utiliser des noms de fichiers clairs qui décrivent ce qu’ils contiennent (tels que “wom?n-results.text”, et non “antconc_results.txt”).
Enregistrer les résultats dans un fichier texte
Fenêtre Enregistrer sous.
Et maintenant vous pouvez ouvrir le fichier texte dans votre éditeur de texte ; vous devrez peut-être élargir la fenêtre de l’application pour la rendre lisible :
Le fichier texte brut affiché dans un éditeur de texte.
Effectuez cette opération pour chacune des deux recherches, puis examinez les deux fichiers texte côte à côte. Qu’est-ce que vous remarquez ?
L’opérateur | (“ou”)
Exercice: Recherchez “she|he”.
Maintenant, recherchez-les séparément : combien d’occurences “she” comparé à “he” ?
| Il y a beaucoup moins de cas de “she”- pourquoi ? C’est une question de recherche ! Une bonne question de suivi pourrait être de trier la recherche “_she | he_” et de voir si des verbes particuliers suivent chacun d’eux. |
Exercice : Entraînez-vous à rechercher un mot de votre choix, à le trier de différentes façons, à utiliser des métacaractères et enfin à exporter les résultats. La question centrale à se poser ici : quels types de modèles voyez-vous ? Pouvez-vous les expliquer ?
Cooccurrences (collocates) et listes des mots (word lists)
Après avoir regardé les lignes KWIC à la recherche de schémas, n’aimeriez-vous pas que l’ordinateur puisse vous donner une liste des mots qui apparaissent le plus souvent en compagnie de votre mot-clé ?
Bonne nouvelle, il y a un moyen d’obtenir cette information, et elle est disponible dans l’onglet Collocates (Cooccurrences). Cliquez dessus, et AntConc vous dira qu’il doit créer une liste de mots. Appuyez sur OK ; il le fera automatiquement.
REMARQUE : Vous n’obtiendrez cet avis que si vous n’avez pas encore créé de liste de mots.
Avertissement liste de mots.
Essayez de générer des coooccurrences pour “she”
Les résultats non triés sembleront commencer par des mots vides (mots qui construisent des phrases) puis descendre jusqu’aux mots de contenu (mots qui construisent du sens). Les mots vides sont ces petits mots ennuyeux, les mots les plus fréquents en anglais, qui sont pour la plupart des créateurs de phrases. Les versions ultérieures d’AntConc incluent souvent le terme de recherche comme premier résultat, probablement parce que le terme de recherche que vous recherchez apparaît dans le texte et nous recherchons des mots qui sont susceptibles d’apparaître avec ce mot.
Certaines personnes voudront peut-être supprimer ces petits mots à l’aide d’une liste de mots vides (stopword list) ; c’est une étape courante dans la modélisation thématique (topic modelling). Personnellement, je n’encourage pas cette pratique parce qu’examiner les mots très fréquents est justement la force des ordinateurs ! La lecture humaine a tendance à ne pas les remarquer beaucoup. Mais les ordinateurs, en particulier les logiciels comme AntConc, peuvent nous montrer où ces mots apparaissent et où ils n’apparaissent pas, ce qui peut être très intéressant, surtout dans de très grandes collections de textes - comme nous l’avons vu précédemment dans le tutoriel, avec the, a, she et he.
De plus, dans les corpus en anglais, il se peut qu’une seule lettre s apparaisse, placée assez haute également - qui représente les ’s possessifs (l’apostrophe ne sera pas comptée), mais AntConc considère qu’il s’agit d’un autre mot. Un autre exemple de ceci est ‘t apparaissant avec do, car ils se contractent comme don’t. Comme ils apparaissent si souvent ensemble, il est fort probable qu’ils soient colocalisés.
Exercice : Générez des cooccurrences pour “m?n” et “wom?n”. Maintenant, triez-les par fréquence jusqu’à 1L. Cela nous renseigne sur ce qui rend un homme ou une femme digne d’être vu(e) au cinéma “ :
- les femmes doivent être “belles” ou “enceintes” ou “sophistiquées”.
- les hommes doivent être en quelque sorte hors norme - “saints” ou “noirs” ou “vieux “.
Ceci ne nous dit pas grand-chose sur les films en eux-mêmes, mais plutôt sur la façon dont ces films sont décrits dans les critiques, et cela peut nous amener à poser des questions plus nuancées, comme “Comment les femmes dans les comédies romantiques sont-elles décrites dans les critiques écrites par des hommes comparativement à celles écrites par des femmes ?”
Comparer des corpus
L’un des types d’analyse les plus intéressant consiste à comparer votre corpus à un corpus de référence plus volumineux.
J’ai sélectionné des critiques de films auxquels Steven Spielberg est associé (en tant que réalisateur ou producteur). On peut les comparer à un corpus de référence de films de différents réalisateurs.
Réfléchissez bien à ce à quoi pourrait ressembler un corpus de référence pour votre propre recherche (par exemple, une étude des écrits d’Agatha Christie dans ses dernières années serait très utile comme corpus d’analyse pour la comparaison avec un corpus de référence constitué de tous ses romans). Rappelez-vous, encore une fois, que la construction de corpus est un sous-domaine à part entière.
Allez dans Settings > Tool preferences > Keyword List (Paramètres > Options des outils > Liste des mots-clés). Sous “Reference Corpus” (Corpus de référence) assurez vous que “Use raw files” (Utiliser des fichiers bruts) est coché. Puis, cliquez sur Add Directory > Open (Ajouter répertoire > Ouvrir) pour ouvrir le répertoire contenant les fichiers qui composent le corpus de référence. Assurez-vous d’avoir une liste complète de fichiers !
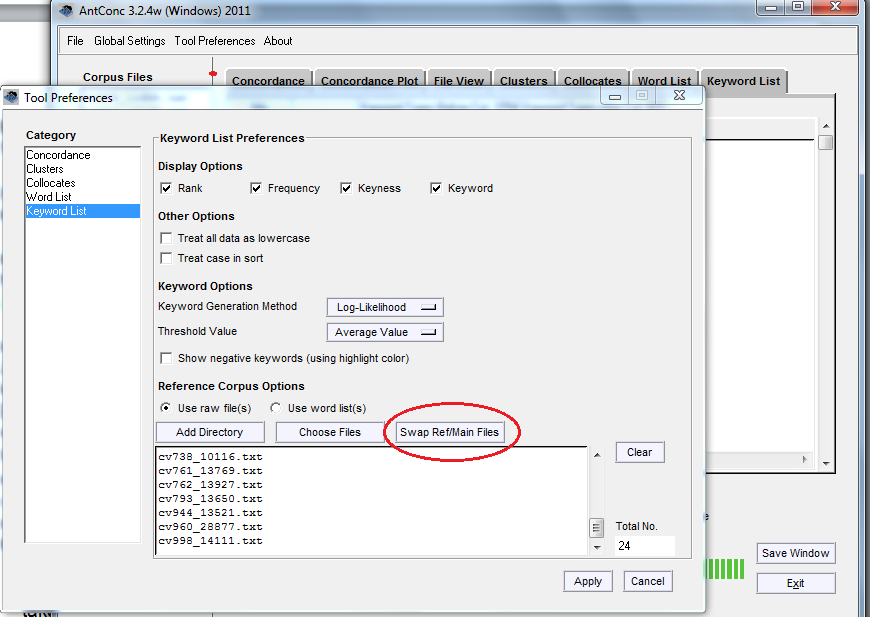
Ajouter un corpus de référence.
Cliquez sur “Load” (Charger), attendez et une fois que la boite “Loaded” (Chargé) est cochée, appuyez sur “Apply” (Appliquer). Vous pouvez également opter pour l’échange de corpus de référence et de fichiers principaux (Swap Ref/Main files). Il vaut la peine de regarder ce que les deux résultats montrent.
Si vous utilisez une version plus récente d’AntConc, l’option Swap Ref/Main files peut être marquée comme “swap with target files”, et vous devrez vous assurer que les corpus cible et de référence ont été chargés (appuyez sur le bouton “Load” à chaque fois que vous téléchargez, ou échangez, un corpus).
Dans Keyword List (Liste des mots-clés), appuyez simplement sur “Start” (Démarrer) (sans rien taper dans le champ de recherche). Si vous venez de changer le corpus de référence et les fichiers cibles, il se peut qu’on vous demande de créer une nouvelle liste de mots avant qu’AntConc ne calcule les mots-clés. Nous voyons une liste de mots-clés qui ont des mots qui sont beaucoup plus “inhabituels” - plus statistiquement inattendus - dans le corpus que nous regardons en comparaison avec le corpus de référence.
Keyness (spécificité) : c’est la fréquence d’un mot dans le texte par rapport à sa fréquence dans un corpus de référence, “telle que la probabilité statistique calculée par une procédure appropriée soit inférieure ou égale à une valeur p indiquée par l’utilisateur” (tiré d’ici). Pour ceux et celles qui s’intéressent aux détails statistiques, voir la section sur la spécificité (Keyness) à la page 7 du fichier read me de Laurence Anthony.
Quels sont nos mots-clés ?
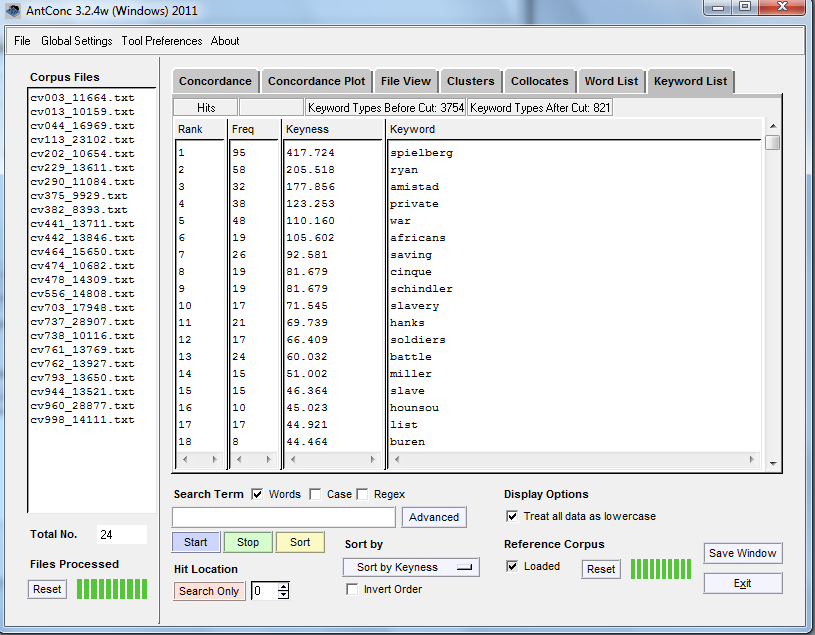
Spielberg vs critiques de films.
Discussion : Faire des comparaisons significatives
Gardez à l’esprit que la façon dont vous organisez vos fichiers textes fait une différence entre les types de questions que vous pouvez poser et les types de résultats que vous obtiendrez. N’oubliez pas que nous comparons ici les critiques “négatives” et “positives” de manière assez simpliste. Vous pourriez, par exemple, faire d’autres comparaisons avec différents sous-ensembles, qui donnent lieu à des questions de nature très différente.
Bien sûr, les fichiers que vous mettez dans votre corpus façonneront vos résultats. Là encore, la question de la représentativité et de l’échantillonnage est très pertinente - il n’est pas toujours nécessaire ou même idéal d’utiliser tous les ensembles de données en même temps, même si vous les avez. À ce stade, il vaut vraiment la peine de s’interroger sur la façon dont ces méthodes aident à produire des questions de recherche.
Lorsque vous réfléchissez à la façon dont les critiques de films fonctionnent en tant que genre, vous pourriez envisager, par exemple….
- Critiques de films vs critiques de musique
- Critiques de films vs critiques de livres
- Critiques de films vs actualités sur le sport
- Critiques de films vs actualités en général
Chacune de ces comparaisons vous dira quelque chose de différent, et peut produire différentes questions de recherche, telles que :
- En quoi les critiques de films sont-elles différentes des autres types de critiques de médias ?
- En quoi les critiques de films sont-elles différentes des autres types d’écrits publiés ?
- Comment les critiques de films se comparent-elles à d’autres types spécifiques d’écriture, comme l’écriture sportive ?
- Quel est le point commun entre les critiques de films et les critiques de musique ?
Et bien sûr, vous pouvez retourner ces questions pour faire d’autres questions de recherche :
- En quoi les critiques de livres sont-elles différentes des critiques de films ?
- En quoi les critiques musicales sont-elles différentes des critiques de films ?
- Qu’est-ce que les articles de journaux publiés ont en commun ?
- Comment les critiques de films sont-elles similaires à d’autres types d’écrits publiés ?
En résumé, il vaut la peine de réfléchir :
- Pourquoi vous voudrez comparer deux corpus ?
- Quels sont les types de requêtes qui rendent les questions de recherche pertinentes ?
- Aux principes de construction de corpus : échantillonnage et s’assurer que vous pouvez obtenir quelque chose de représentatif
Ressources supplémentaires pour ce tutoriel
En anglais
Une courte bibliographie sur la linguistique des corpus.
Une version plus détaillée de ce tutoriel, en supposant que vous n’avez aucune connaissance en informatique.
En français (notes de la version traduite)
Page AntConc de EduTech Wiki de l’UNIGE
Page AntConc sur le site Exploration de corpus : outils et pratiques
Tutoriel AntConc du CID-ENS Lyon
En France, des outils similaires à AntConc ont été dévéloppés dans le cadre de la textométrie, de la lexicométrie, et de la logométrie, souvent par des historien(ne)s. On peut nommer notamment Hyperbase, Iramuteq, Lexico ou TXM. Merci de consulter également: Bénédicte Pincemin, “Sept logiciels de textométrie”, 2018.
Bibliographie non-exhaustive
Ludovic Lebart et André Salem, Statistique textuelle, 1994.
Damon Mayaffre, “L’entrelacement lexical des textes. Cooccurrences et lexicométrie”, Journées de linguistique de corpus, 2008, p. 91-102.
La cooccurrence, du fait statistique au fait textuel, Corpus, 11, 2012, numéro coordonné par Damon Mayaffre et Jean-Marie Viprey.