Contents
- Background
- Possibilities
- Suggested Prior Skills
- Download the Lesson Files
- More Features in the HTRC Extracted Features Dataset
- Next Steps
- References
- Appendix: Downloading custom files via rsync
Summary: We introduce a toolkit for working with the 13.6 million volume Extracted Features Dataset from the HathiTrust Research Center. You will learn how to peer at the words and trends of any book in the collection, while developing broadly useful Python data analysis skills.
The HathiTrust holds nearly 15 million digitized volumes from libraries around the world. In addition to their individual value, these works in aggregate are extremely valuable for historians. Spanning many centuries and genres, they offer a way to learn about large-scale trends in history and culture, as well as evidence for changes in language or even the structure of the book. To simplify access to this collection the HathiTrust Research Center (HTRC) has released the Extracted Features dataset (Capitanu et al. 2015): a dataset that provides quantitative information describing every page of every volume in the collection.
In this lesson, we introduce the HTRC Feature Reader, a library for working with the HTRC Extracted Features dataset using the Python programming language. The HTRC Feature Reader is structured to support work using popular data science libraries, particularly Pandas. Pandas provides simple structures for holding data and powerful ways to interact with it. The HTRC Feature Reader uses these data structures, so learning how to use it will also cover general data analysis skills in Python.
Today, you’ll learn:
- How to work with notebooks, an interactive environment for data science in Python;
- Methods to read and visualize text data for millions of books with the HTRC Feature Reader; and
- Data malleability, the skills to select, slice, and summarize extracted features data using the flexible “DataFrame” structure.
Background
The HathiTrust Research Center (HTRC) is the research arm of the HathiTrust, tasked with supporting research usage of the works held by the HathiTrust. Particularly, this support involves mediating large-scale access to materials in a non-consumptive manner, which aims to allow research over a work without enabling that work to be traditionally enjoyed or read by a human reader. Huge digital collections can be of public benefit by allowing scholars to discover insights about history and culture, and the non-consumptive model allows for these uses to be sought within the restrictions of intellectual property law.
As part of its mission, the HTRC has released the Extracted Features (EF) dataset containing features derived for every page of 13.6 million ‘volumes’ (a generalized term referring to the different types of materials in the HathiTrust collection, of which books are the most prevalent type).
What is a feature? A feature is a quantifiable marker of something measurable, a datum. A computer cannot understand the meaning of a sentence implicitly, but it can understand the counts of various words and word forms, or the presence or absence of stylistic markers, from which it can be trained to better understand text. Many text features are non-consumptive in that they don’t retain enough information to reconstruct the book text.
Not all features are useful, and not all algorithms use the same features. With the HTRC EF Dataset, we have tried to include the most generally useful features, as well as adapt to scholarly needs. We include per-page information such as counts of words tagged by part of speech (e.g. how many times does the word jaguar appear as a lowercase noun on this page), line and sentence counts, and counts of characters at the leftmost and rightmost sides of a page. No positional information is provided, so the data would not specify if ‘brown’ is followed by ‘dog’, though the information is shared for every single page, so you can at least infer how often ‘brown’ and ‘dog’ occurred in the same general vicinity within a text.
Freely accessible and preprocessed, the Extracted Features dataset offers a great entry point to programmatic text analysis and text mining. To further simplify beginner usage, the HTRC has released the HTRC Feature Reader. The HTRC Feature Reader scaffolds use of the dataset with the Python programming language.
This tutorial teaches the fundamentals of using the Extracted Features dataset with the HTRC Feature Reader. The HTRC Feature Reader is designed to make use of data structures from the most popular scientific tools in Python, so the skills taught here will apply to other settings of data analysis. In this way, the Extracted Features dataset is a particularly good use case for learning more general text analysis skills. We will look at data structures for holding text, patterns for querying and filtering that information, and ways to summarize, group, and visualize the data.
Possibilities
Though it is relatively new, the Extracted Features dataset is already seeing use by scholars, as seen on a page collected by the HTRC.
Underwood leveraged the features for identifying genres, such as fiction, poetry, and drama (2014). Associated with this work, he has released a dataset of 178k books classified by genre alongside genre-specific word counts (Underwood 2015).
The Underwood subset of the Extracted Features dataset was used by Forster (2015) to observe gender in literature, illustrating the decline of woman authors through the 19th century.
The Extracted Features dataset also underlies higher-level analytic tools. Mimno processed word co-occurrence tables per year, allowing others to view how correlations between topics change over time (2014). The HT Bookworm project has developed an API and visualization tools to support exploration of trends within the HathiTrust collection across various classes, genres, and languages. Finally, we have developed an approach to within-book topic modelling which functions as a mnemonic accompaniment to a previously-read book (Organisciak 2014).
Suggested Prior Skills
This lesson provides a gentle but technical introduction to text analysis in Python with the HTRC Feature Reader. Most of the code is provided, but is most useful if you are comfortable tinkering with it and seeing how outputs change when you do.
We recommend a baseline knowledge of Python conventions, which can be learned with Turkel and Crymble’s series of Python lessons on Programming Historian.
The skills taught here are focused on flexibly accessing and working with already-computed text features. For a better understanding of the process of deriving word features, Programming Historian provides a lesson on Counting Frequencies, by Turkel and Crymble.
A more detailed look at text analysis with Python is provided in the Art of Literary Text Analysis (Sinclair). The Art of Literary Text Analysis (ALTA) provides a deeper introduction to foundation Python skills, as well as introduces further text analytics concepts to accompany the skills we cover in this lesson. This includes lessons on extracting features (tokenization, collocations), and visualizing trends.
Download the Lesson Files
To follow along, download lesson_files.zip and unzip it to any directory you choose.
The lesson files include a sample of files from the HTRC Extracted Features dataset. After you learn to use the feature data in this lesson, you may want to work with the entirety of the dataset. The details on how to do this are described in Appendix: rsync.
Installation
For this lesson, you need to install the HTRC Feature Reader library for Python alongside the data science libraries that it depends on.
For ease, this lesson will focus on installing Python through a scientific distribution called Anaconda. Anaconda is an easy-to-install Python distribution that already includes most of the dependencies for the HTRC Feature Reader.
To install Anaconda, download the installer for your system from the Anaconda download page and follow their instructions for installation of either the Windows 64-bit Graphical Installer or the Mac OS X 64-bit Graphical Installer. You can choose either version of Python for this lesson. If you have followed earlier lessons on Python at the Programming Historian, you are using Python 2, but the HTRC Feature Reader also supports Python 3.

Conda Install
Installing the HTRC Feature Reader
The HTRC Feature Reader can be installed by command line. First open a terminal application:
- Windows: Open ‘Command Prompt’ from the Start Menu and type:
activate. - Mac OS/Linux: Open ‘Terminal’ from Applications and type
source activate.
If Anaconda was properly installed, you should see something similar to this:

Activating the default Anaconda environment.
Now, you need to type one command:
conda install -c htrc htrc-feature-reader
This command installs the HTRC Feature Reader and its necessary dependencies. We specify -c htrc so the installation command knows to find the library from the htrc organization.
That’s it! At this point you have everything necessary to start reading HTRC Feature Reader files.
psst, advanced users: You can install the HTRC Feature Reader without Anaconda with
pip install htrc-feature-reader, though for this lesson you’ll need to install two additional librariespip install matplotlib jupyter. Also, note that not all manual installations are alike because of hard-to-configure system optimizations: this is why we recommend Anaconda. If you think your code is going slow, you should check that Numpy has access to BLAS and LAPACK libraries and install Pandas recommended packages. The rest is up to you, advanced user!
Start a Notebook
Using Python the traditional way – writing a script to a file and running it – can become clunky for text analysis, where the ability to look at and interact with data is invaluable. This lesson uses an alternative approach: Jupyter notebooks.
Jupyter gives you an interactive version of Python (called IPython) that you can access in a “notebook” format in your web browser. This format has many benefits. The interactivity means that you don’t need to re-run an entire script each time: you can run or re-run blocks of code as you go along, without losing your enviroment (i.e. the variables and code that are already loaded). The notebook format makes it easier to examine bits of information as you go along, and allows for text blocks to intersperse a narrative.
Jupyter was installed alongside Anaconda in the previous section, so it should be available to load now.
From the Start Menu (Windows) or Applications directory (Mac OS), open “Jupyter notebook”. This will start Jupyter on your computer and open a browser window. Keep the console window in the background, the browser is where the magic happens.
Opening Jupyter on Windows
If your web browser does not open automatically, Jupyter can be accessed by going to the address “localhost:8888” - or a different port number, which is noted in the console (“The Jupyter Notebook is running at…”):
A freshly started Jupyter notebook instance.
Jupyter is now showing a directory structure from your home folder. Navigate to the lesson folder where you unzipped lesson_files.zip.
In the lesson folder, open Start Here.pynb: your first notebook!
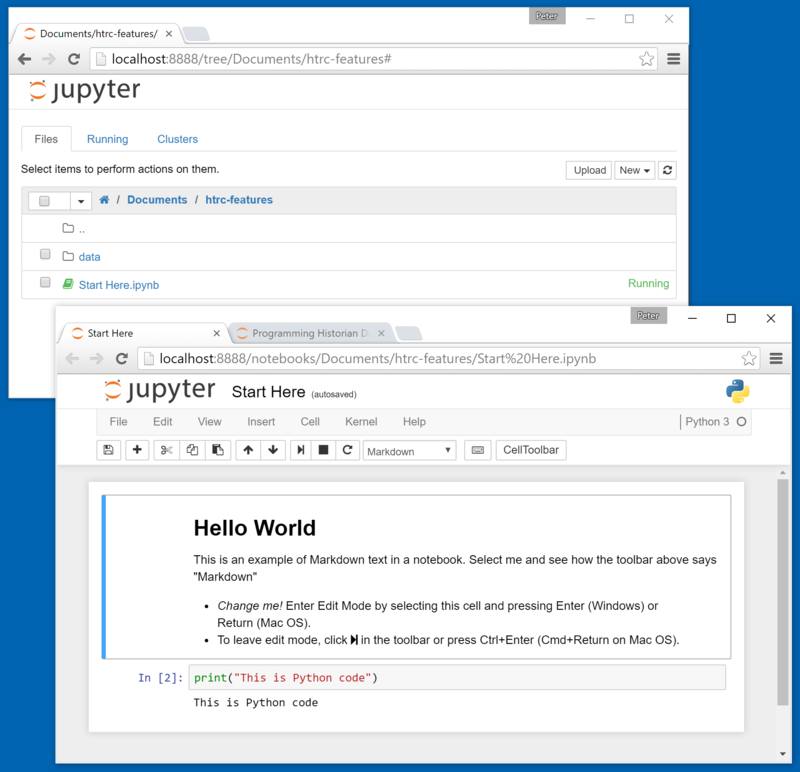
Hello world in a notebook
Here there are instructions for editing a cell of text or code, and running it. Try editing and running a cell, and notice that it only affects itself. Here are a few tips for using the notebook as the lesson continues:
- New cells are created with the Plus button in the toolbar. When not editing, this can be done by pressing ‘b’ on your keyboard.
- New cells are “code” cells by default, but can be changed to “Markdown” (a type of text input) in a dropdown menu on the toolbar. In edit mode, you can paste in code from this lesson or type it yourself.
- Switching a cell to edit mode is done by pressing Enter.
- Running a cell is done by clicking Play in the toolbar, or with
Ctrl+Enter(Ctrl+Returnon Mac OS). To run a cell and immediately move forward, useShift+Enterinstead.
An example of a full-fledged notebook is included with the lesson files in
example/Lesson Draft.ipynb.
In this notebook, it’s time to give the HTRC Feature Reader a try. When it is time to try some code, start a new cell with Plus, and run the code with Play. Before continuing, click on the title to change it to something more descriptive than “Start Here”.
Reading your First Volume
The HTRC Feature Reader library has three main objects: FeatureReader, Volume, and Page.
The FeatureReader object is the interface for loading the dataset files and making sense of them. The files are originally formatted in a notation called JSON (which Programming Historian discusses here) and compressed, which FeatureReader makes sense of and returns as Volume objects. A Volume is a representation of a single book or other work. This is where you access features about a work. Many features for a volume are collected from individual pages; to access Page information, you can use the Page object.
Let’s load two volumes to understand how the FeatureReader works. Create a cell in the already-open Jupyter notebook and run the following code. This should give you the input shown below.
from htrc_features import FeatureReader
import os
paths = [os.path.join('data', 'sample-file1.json.bz2'), os.path.join('data', 'sample-file2.json.bz2')]
fr = FeatureReader(paths)
for vol in fr.volumes():
print(vol.title)
June / by Edith Barnard Delano ; with illustrations.
You never know your luck; being the story of a matrimonial deserter, by Gilbert Parker ... illustrated by W.L. Jacobs.
Here, the FeatureReader is imported and initialized with file paths pointing to two Extracted Features files. The files are in a directory called ‘data’. Different systems do file paths differently: Windows uses back slashes (‘data\…’) while Linux and Mac OS use forward slashes (‘data/…’). os.path.join is used to make sure that the file path is correctly structured, a convention to ensure that code works on these different platforms.
With fr = FeatureReader(paths), the FeatureReader is initialized, meaning it is ready to use. An initialized FeatureReader is holding references to the file paths that we gave it, and will load them into Volume objects when asked.
Consider the last bit of code:
for vol in fr.volumes():
print(vol.title)
This code asks for volumes in a way that can be iterated through. The for loop is saying to fr.volumes(), “give me every single volume that you have, one by one.” Each time the for loop gets a volume, it starts calling it vol, runs what is inside the loop on it, then asks for the next one. In this case, we just told it to print the title of the volume.
You may recognize for loops from past experience iterating through what is known as a list in Python. However, it is important to note that fr.volumes() is not a list. If you try to access it directly, it won’t print all the volumes; rather, it identifies itself as something known as a generator:

Identifying a generator
What is a generator, and why do we iterate over it?
Generators are the key to working with lots of data. They allow you to iterate over a set of items that don’t exist yet, preparing them only when it is their turn to be acted upon.
Remember that there are 13.6 million volumes in the Extracted Features dataset. When coding at that scale, you need to be be mindful of two rules:
- Don’t hold everything in memory: you can’t. Use it, reduce it, and move on.
- Don’t devote cycles to processing something before you need it.
A generator simplifies such on-demand, short term usage. Think of it like a pizza shop making pizzas when a customer orders, versus one that prepares them beforehand. The traditional approach to iterating through data is akin to making all the pizzas for the day before opening. Doing so would make the buying process quicker, but also adds a huge upfront time cost, needs larger ovens, and necessitates the space to hold all the pizzas at once. An alternate approach is to make pizzas on-demand when customers buy them, allowing the pizza place to work with smaller capacities and without having pizzas laying around the shop. This is the type of approach that a generator allows.
Volumes need to be prepared before you do anything with them, being read, decompressed and parsed. This ‘initialization’ of a volume is done when you ask for the volume, not when you create the FeatureReader. In the above code, after you run fr = FeatureReader(paths), there are are still no Volume objects held behind the scenes: just the references to the file locations. The files are only read when their time comes in the loop on the generator fr.volumes(). Note that because of this one-by-one reading, the items of a generator cannot be accessed out of order (e.g. you cannot ask for the third item of fr.volumes() without going through the first two first).
What’s in a Volume?
Let’s take a closer look at what features are accessible for a Volume object. For clarity, we’ll grab the first Volume to focus on, which can conveniently be accessed with the first() method. Any code you write can easily be run later with a for vol in fr.volumes() loop.
Again here, start a new code cell in the same notebook that you had open before and run the following code. The FeatureReader does not need to be loaded again: it is still initialized and accessible as fr from earlier.
# Reading a single volume
vol = fr.first()
vol
<htrc_features.feature_reader.Volume at 0x1cf355a60f0>
While the majority of the HTRC Extracted Features dataset is features, quantitative abstractions of a book’s written content, there is also a small amount of metadata included for each volume. We already saw Volume.title accessed earlier. Other metadata attributes include:
Volume.id: A unique identifier for the volume in the HathiTrust and the HathiTrust Research Center.Volume.year: The publishing date of the volume.Volume.language: The classified language of the volume.Volume.oclc: The OCLC control number(s).
The volume id can be used to pull more information from other sources. The scanned copy of the book can be found from the HathiTrust Digital Library, when available, by accessing http://hdl.handle.net/2027/{VOLUME ID}. In the feature reader, this url is retrieved by calling vol.handle_url:
print(vol.handle_url)
http://hdl.handle.net/2027/nyp.33433075749246

Digital copy of sample book
Hopefully by now you are growing more comfortable with the process of running code in a Jupyter notebook, starting a cell, writing code, and running the cell. A valuable property of this type of interactive coding is that there is room for error. An error doesn’t cause the whole program to crash, requiring you to rerun everything from the start. Instead, just fix the code in your cell and try again.
In Jupyter, pressing the ‘TAB’ key will guess at what you want to type next. Typing vo then TAB will fill in vol, typing Fea then TAB will fill in FeatureReader.
Auto-completion with the tab key also provides more information about what you can get from an object. Try typing vol. (with the period) in a new cell, then press TAB. Jupyter shows everything that you can access for that Volume.
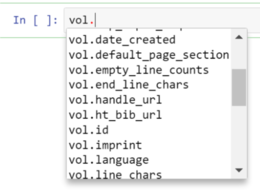
Tab Autocomplete in Jupyter
The Extracted Features dataset does not hold all the metadata that the HathiTrust has for the book. More in-depth metadata like genre and subject class needs to be grabbed from other sources, such as the HathiTrust Bibliographic API. The URL to access this information can be retrieved with vol.ht_bib_url.
Our First Feature Access: Visualizing Words Per Page
It’s time to access the first features of vol: a table of total words for every single page. These can be accessed by calling vol.tokens_per_page(). Try the following code.
If you are using a Jupyter notebook, returning this table at the end of a cell formats it nicely in the browser. Below, you’ll see us append
.head()to thetokenstable, which allows us to look at just the top few rows: the ‘head’ of the data.
tokens = vol.tokens_per_page()
# Show just the first few rows, so we can look at what it looks like
tokens.head()
| count | |
|---|---|
| page | |
| 1 | 5 |
| 2 | 0 |
| 3 | 1 |
| 4 | 0 |
| 5 | 1 |
No print! We didn’t call ‘print()’ to make Jupyter show the table. Instead, it automatically guessed that you want to display the information from the last code line of the cell.
This is a straightforward table of information, similar to what you would see in Excel or Google Spreadsheets. Listed in the table are page numbers and the count of words on each page. With only two dimensions, it is trivial to plot the number of words per page. The table structure holding the data has a plot method for data graphics. Without extra arguments, tokens.plot() will assume that you want a line chart with the page on the x-axis and word count on the y-axis.
%matplotlib inline
tokens.plot()
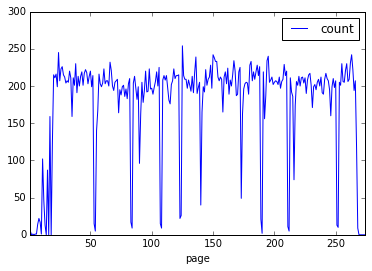
Output graph.
%matplotlib inlinetells Jupyter to show the plotted image directly in the notebook web page. It only needs to be called once, and isn’t needed if you’re not using notebooks.
On some systems, this may take some time the first time. It is clear that pages at the start of a book have fewer words per page, after which the count is fairly steady except for occasional valleys.
You may have some guesses for what these patterns mean. A look at the scans confirms that the large valleys are often illustration pages or blank pages, small valleys are chapter headings, and the upward pattern at the start is from front matter.
Not all books will have the same patterns so we can’t just codify these correlations for millions of books. However, looking at this plot makes clear an inportant assumption in text and data mining: that there are patterns underlying even the basic statistics derived from a text. The trick is to identify the consistent and interesting patterns and teach them to a computer.
Understanding DataFrames
Wait… how did we get here so quickly!? We went from a volume to a data visualization in two lines of code. The magic is in the data structure used to hold our table of data: a DataFrame.
A DataFrame is a type of object provided by the data analysis library, Pandas. Pandas is very common for data analysis, allowing conveniences in Python that are found in statistical languages like R or Matlab.
In the first line, vol.tokens_per_page() returns a DataFrame, something that can be confirmed if you ask Python about its type with type(tokens). This means that after setting tokens, we’re no longer working with HTRC-specific code, just book data held in a common and very robust table-like construct from Pandas. tokens.head() used a DataFrame method to look at the first few rows of the dataset, and tokens.plot() uses a method from Pandas to visualize data.
Many of the methods in the HTRC Feature Reader return DataFrames. The aim is to fit into the workflow of an experienced user, rather than requiring them to learn proprietary new formats. For new Python data mining users, learning to use the HTRC Feature Reader means learning many data mining skills that will translate to other uses.
Loading a Token List
The information contained in vol.tokens_per_page() is minimal, a sum of all words in the body of each page.
The Extracted Features dataset also provides token counts with much more granularity: for every part of speech (e.g. noun, verb) of every occurring capitalization of every word of every section (i.e. header, footer, body) of every page of the volume.
tokens_per_page() only kept the “for every page” grouping; vol.tokenlist() can be called to return section-, part-of-speech-, and word-specific details:
tl = vol.tokenlist()
# Let's look at some words deeper into the book:
# from 1000th to 1100th row, skipping by 15 [1000:1100:15]
tl[1000:1100:15]
| count | ||||
|---|---|---|---|---|
| page | section | token | pos | |
| 27 | body | those | DT | 1 |
| within | IN | 1 | ||
| 28 | body | a | DT | 3 |
| be | VB | 1 | ||
| deserted | VBN | 1 | ||
| faintly | RB | 1 | ||
| important | JJ | 1 |
As before, the data is returned as a Pandas DataFrame. This time, there is much more information. Consider a single row:
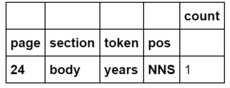
Single row of tokenlist.
The columns in bold are an index. Unlike the typical one-dimensional index seen before, here there are four dimensions to the index: page, section, token, and pos. This row says that for the 24th page, in the body section (i.e. ignoring any words in the header or footer), the word ‘years’ occurs 1 time as an plural noun. The part-of-speech tag for a plural noun, NNS, follows the Penn Treebank definition.
The “words” on the first page seems to be OCR errors for the cover of the book. The HTRC Feature Reader refers to “pages” as the \(n^{th}\) scanned image of the volume, not the actual number printed on the page. This is why “page 1” for this example is the cover.
Tokenlists can be retrieved with arguments that combine information by certain dimensions, such as case, pos, or page. For example, case=False specified that “Jaguar” and “jaguar” should be counted together. You may also notice that, by default, only ‘body’ is returned, a default that can be overridden.
Look at the following list of commands: can you guess what the output will look like? Try for yourself and observe how the output changes.
vol.tokenlist(case=False)vol.tokenlist(pos=False)vol.tokenlist(pages=False, case=False, pos=False)vol.tokenlist(section='header')vol.tokenlist(section='group')
Details for these arguments are available in the code documentation for the Feature Reader.
Jupyter provides another convenience here. Documentation can be accessed within the notebook by adding a ‘?’ to the start of a piece of code. Try it with ?vol.tokenlist, or with other objects or variables.
Working with DataFrames
The Pandas DataFrame type returned by the HTRC Feature Reader is very malleable. To work with the tokenlist that you retrieved earlier, three skills are particularily valuable:
- Selecting subsets by a condition
- Slicing by named row index
- Grouping and aggregating
Selecting Subsets of a DataFrame by a Condition
Consider this example: I only want to look at tokens that occur more than a hundred times in the book.
Remembering that the table-like output from the HTRC Feature Reader is a Pandas DataFrame, the way to pursue this goal is to learn to filter and subset DataFrames. Knowing how to do so is important for working with just the data that you need.
To subset individual rows of a DataFrame, you can provide a series of True/False values to the DataFrame, formatted in square brackets. When True, the DataFrame returns that row; when False, the row is excluded from what is returned.
To see this in context, first load a basic tokenlist without parts-of-speech or individual pages:
tl_simple = vol.tokenlist(pos=False, pages=False)
# .sample(5) returns five random words from the full result
tl_simple.sample(5)
| count | ||
|---|---|---|
| section | token | |
| body | halleluya | 4 |
| realty | 1 | |
| addressed | 4 | |
| win- | 1 | |
| broke | 3 |
To select just the relevant tokens, we need to look at each row and evaluate whether it matches the criteria that “this token has a count greater than 100”. Let’s try to convert that requirement to code.
“This token has a count” means that we are concerned specifically with the ‘count’ column, which can be singled out from the tl table with tl['count']. “greater than 100” is formalized as > 100. Putting it together, try the following and see what you get:
tl_simple['count'] > 100
It is a DataFrame of True/False values. Each value indicates whether the ‘count’ column in the corresponding row matches the criteria or not. We haven’t selected a subset yet, we simply asked a question and were told for each row when the question was true or false.
You may wonder why section and token are still seen, even though ‘count’ was selected. These are part of the DataFrame index, so they’re considered part of the information about that row rather than data in the row. You can convert the index to data columns with
reset_index(). In this lesson we will keep the index intact, though there are advanced cases where there are benefits to resetting it.
Armed with the True/False values of whether each token’s ‘count’ value is or isn’t greater than 100, we can give those values to tl_simple in square brackets.
matches = tl_simple['count'] > 100
tl_simple[matches].sample(5)
| count | ||
|---|---|---|
| section | token | |
| body | they | 127 |
| have | 210 | |
| The | 107 | |
| about | 110 | |
| , | 3258 |
You can move the comparison straight into the square brackets, the more conventional equivalent of the above:
tl_simple[tl_simple['count'] > 100].sample(5)
| count | ||
|---|---|---|
| section | token | |
| body | not | 220 |
| had | 455 | |
| have | 210 | |
| , | 3258 | |
| his | 206 |
As might be expected, many of the tokens that occur very often are common words like “she” and “and”, as well as various punctuation.
Multiple conditions can be chained with & (and) or | (or), using regular brackets so that Python knows the order of operations. For example, words with a count greater than 150 and a count less than 200 are selected in this way:
tl_simple[(tl_simple['count'] > 150) & (tl_simple['count'] < 200)]
| count | ||
|---|---|---|
| section | token | |
| body | Mr. | 159 |
| be | 196 | |
| but | 178 | |
| do | 179 | |
| is | 170 | |
| on | 190 | |
| — | 167 |
Slicing DataFrames
Above, subsets of the DataFrame were selected based on a matching criteria for columns. It is also possible to select a DataFrame subset by specifying the values of its index, a process called slicing. For example, you can ask, “give me all the verbs for pages 9-12”.
In the DataFrame returned by vol.tokenlist(), page, section, token, and POS were part of the index (try the command tl.index.names to confirm). One can think of an index as the margin content of an Excel spreadsheet: the letters along the top and numbers along the left side are the indices. A cell can be referred to as A1, A2, B1… In Pandas, however, you can name these, so instead of A, B, C, or 1,2,3, columns and rows can be referred to by more descriptive names. You can also have multiple levels, so you’re not bound by the two-dimensions of a table format. With a multi-indexed DataFrame, you can ask for Page=24,section=Body, ....
One can think of an index as the margin notations in Excel (i.e. 1,2,3… and A,B,C,..), except it can be named and can have multiple levels.
Slicing a DataFrame against a labelled index is done using DataFrame.loc[]. Try the following examples and see what is returned:
- Select information from page 17:
tl.loc[(17),]
- Select ‘body’ section of page 17:
tl.loc[(17, 'body'),]
- Select counts of the word ‘Anne’ in the ‘body’ section of page 17:
tl.loc[(17, 'body', 'Anne'),]
The levels of the index are specified in order, so in this case the first value refers to ‘page’, then ‘section’, and so on. To skip specifying anything for an index level – that is, to select everything for that level – slice(None) can be used as a placeholder:
- Select counts of the word ‘Anne’ for all pages and all page sections
tl.loc[(slice(None), slice(None), "Anne"),]
Finally, it is possible to select multiple labels for a level of the index, with a list of labels (i.e. ['label1', 'label2']) or a sequence covering everything from one value to another (i.e. slice(start, end)):
- Select pages 37, 38, and 52
tl.loc[([37, 38, 52]),]
- Select all pages from 37 to 40
tl.loc[(slice(37, 40)),]
- Select counts for ‘Anne’ or ‘Hilary’ from all pages
tl.loc[(slice(None), slice(None), ["Anne", "Hilary"]),]
The reason for the comma in
tl.loc[(...),]is because columns can be selected in the same way after the comma. Pandas DataFrames can have a multiple-level index for columns, but the HTRC Feature Reader does not use this.
Knowing how to slice, let’s try to find the word “CHAPTER” in this book, and compare where that shows up to the token-per-page pattern previously plotted.
The token list we previously set to tl only included body text; to include headers and footers in a search for CHAPTER we’ll grab a new tokenlist with section='all' specified.
tl_all = vol.tokenlist(section='all')
chapter_pages = tl_all.loc[(slice(None), slice(None), "CHAPTER"),]
chapter_pages
| count | ||||
|---|---|---|---|---|
| page | section | token | pos | |
| 19 | header | CHAPTER | NNP | 1 |
| 35 | header | CHAPTER | NNP | 1 |
| 56 | header | CHAPTER | NNP | 1 |
| 73 | header | CHAPTER | NNP | 1 |
| 91 | header | CHAPTER | NNP | 1 |
| 115 | header | CHAPTER | NNP | 1 |
| 141 | header | CHAPTER | NNP | 1 |
| 158 | header | CHAPTER | NNP | 1 |
| 174 | header | CHAPTER | NNP | 1 |
| 193 | header | CHAPTER | NNP | 1 |
| 217 | body | CHAPTER | NNP | 1 |
| 231 | header | CHAPTER | NNP | 1 |
| 246 | header | CHAPTER | NNP | 1 |
Earlier, token counts were visualized using tokens.plot(), a built-in function of DataFrames that uses the Matplotlib visualization library.
We can add to the earlier visualization by using Matplotlib directly. Try the following code in a new cell, which goes through every page number in the earlier search for ‘CHAPTER’ and adds a red vertical line at the place in the chart with matplotlib.pyplot.axvline():
# Get just the page numbers from the search for "CHAPTER"
page_numbers = chapter_pages.index.get_level_values('page')
# Visualize the tokens-per-page from before
tokens.plot()
# Add vertical lines for pages with "CHAPTER"
import matplotlib.pyplot as plt
for page_number in page_numbers:
plt.axvline(x=page_number, color='red')
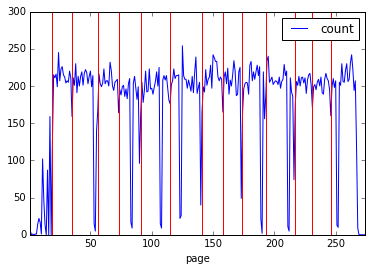
Output graph.
Advanced: Though slicing with
locis more common when working with the index, it is possible to create a True/False list from an index to select rows as we did earlier. Here’s an advanced example that grabs the ‘token’ part of the index and, using theisalpha()string method that Pandas provides, filters to fully alphabetical words.token_idx = tl.index.get_level_values("token") tl[token_idx.str.isalpha()]Readers familiar with regular expressions (see Understanding Regular Expressions by Doug Knox) can adapt this example for even more robust selection using the
contains()string method.
Sorting DataFrames
A DataFrame can be sorted with DataFrame.sort_values(), specifying the column to sort by as the first argument. By default, sorting is done in ascending order:
tl_simple.sort_values('count').head()
| count | ||
|---|---|---|
| section | token | |
| body | gratified | 1 |
| reminding | 1 | |
| dome | 1 | |
| remembering | 1 | |
| remains | 1 |
Descending order is possible with the argument ascending=False, which puts the most common tokens at the top. For example:
tl_simple.sort_values('count', ascending=False).head()
| count | ||
|---|---|---|
| section | token | |
| body | , | 3258 |
| " | 1670 | |
| the | 1565 | |
| . | 1532 | |
| and | 1252 |
The most common tokens are ‘the’ and ‘and’, alongside punctuation.
Exercise: Try to retrieve the five most-common tokens used as a noun (‘NNP’) or a plural noun (‘NNS’) in the book. You will have to get a new tokenlist, without pages but with parts-of-speech, then slice by the criteria, sort, and output the first five rows. (Solution)
Grouping DataFrames
Up to this point, the token count DataFrames have been subsetted, but not modified from the way they were returned by the HTRC Feature Reader. There are many cases where one may want to perform aggregation or transformation based on subsets of data. To do this, Pandas supports the ‘split-apply-combine’ pattern (Wickham 2011).
Split-apply-combine refers to the process of dividing a dataset into groups (split), performing some activity for each of those groups (apply), and joining the new groups back together into a single DataFrame (combine).
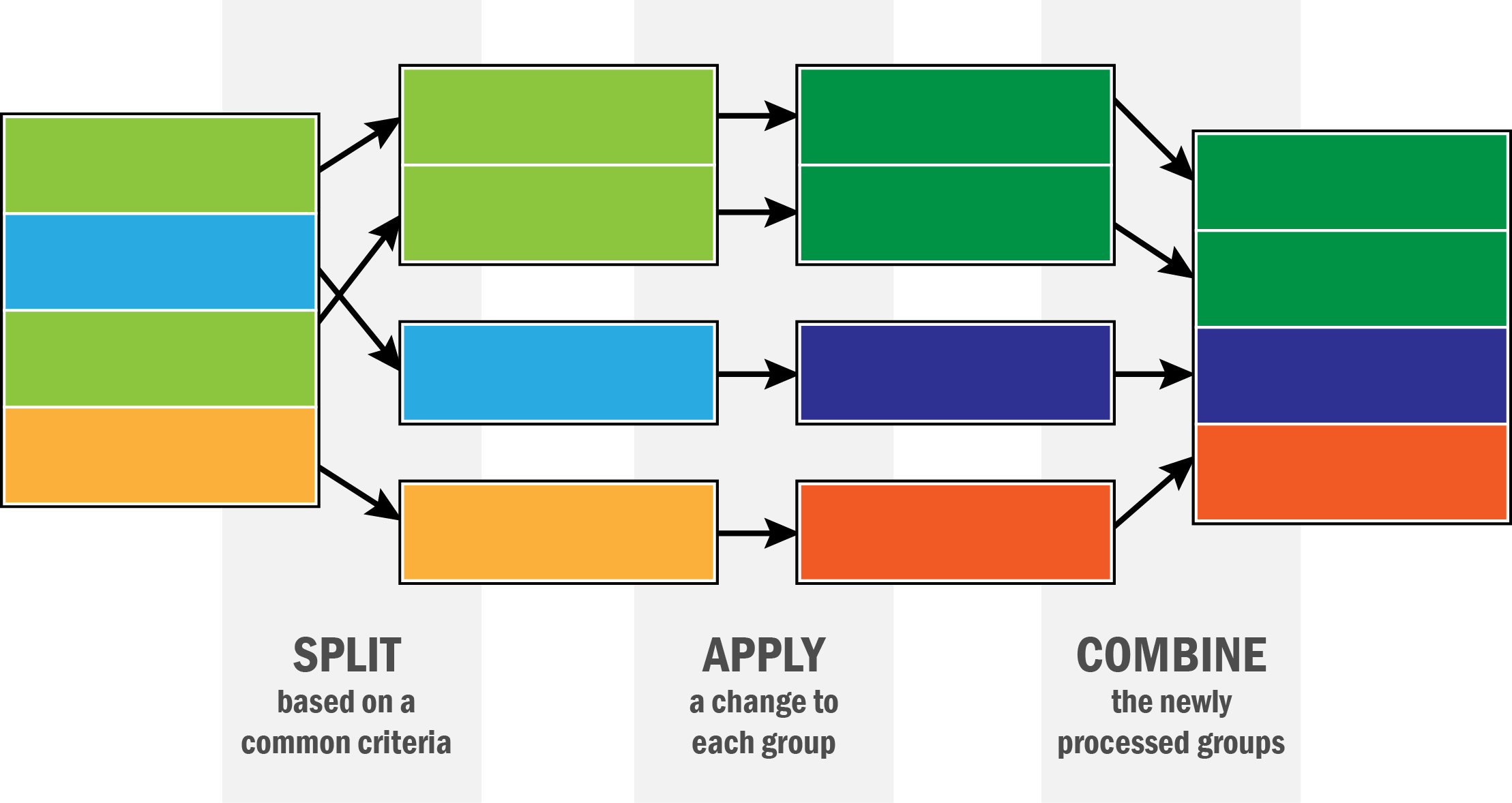
Graph demonstrating Split-Apply-Combine.
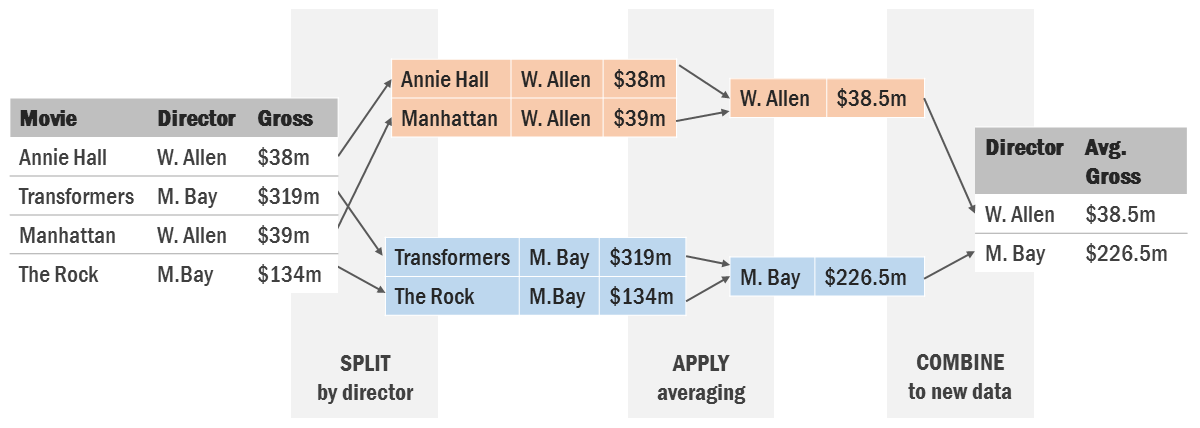
Example of Split-Apply-Combine, averaging movie grosses by director.
Split-apply-combine processes are supported on DataFrames with groupby(), which tells Pandas to split by some criteria. From there, it is possible to apply some change to each group individually, after which Pandas combines the affected groups into a single DataFrame again.
Try the following, can you tell what happens?
tl.groupby(level=["pos"]).sum()
The output is a count of how often each part-of-speech tag (“pos”) occurs in the entire book.
- Split with
groupby(): We took the token count dataframe that is set totland grouped by the part-of-speech (pos) level of the index. This means that rather than thinking in terms of rows, Pandas is now thinking of thetlDataFrame as a series of smaller groups, the groups selected by a common value for part of speech. So, all the personal pronouns (“PRP”) are in one group, and all the adverbs (“RB”) are in another, and so on. - Apply with
sum(): These groups were sent to an apply function,sum(). Sum is an aggregation function, so it sums all the information in the ‘count’ column for each group. For example, all the rows of data in the adverb group are summed up into a single count of all adverbs. - Combine: The combine step is implicit: the DataFrame knows from the
groupbypattern to take everything that the apply function gives back (in the case of ‘sum’, just one row for every group) and stick it together.
sum() is one of many convenient functions built-in to Pandas. Other useful functions are mean(), count(), max(). It is also possible to send your groups to any function that you write with apply().
groupby can be used on data columns or an index. To run against an index, use
level=[index_level_name]as above. To group against columns, useby=[column_name].
Below are some examples of grouping token counts.
- Find most common tokens in the entire volume (sorting by most to least occurrences)
tl.groupby(level="token").sum().sort_values("count", ascending=False)
- Count how many pages each token/pos combination occurs on
tl.groupby(level=["token", "pos"]).count()
Remember from earlier that certain information can be called by sending arguments to vol.tokenlist(), so you don’t always have to do the grouping yourself.
With sum, the data is being reduced: only one row is left for each group. It is also possible to ‘transform’ a group, where the same number of rows are returned. This is useful if processing is necessary based on the group statistics, such as percentages. Here is an advanced example of transformation, a TF*IDF function. TF*IDF weighs a token’s value to a document based on how common it is. In this case, it highlights words that are notable for a page but not the entire book.
from numpy import log
def tfidf(x):
return x * log(1+vol.page_count / x.count())
# Will take a few seconds to run, depending on your system
idf_scores = tl.groupby(level=["token"]).transform(tfidf)
idf_scores[1000:1100:30]
| count | ||||
|---|---|---|---|---|
| page | section | token | pos | |
| 24 | body | years | NNS | 2.315830 |
| 25 | body | asked | VBD | 1.730605 |
| him | PRP | 2.994040 | ||
| n't | RB | 1.250162 |
Compare the parts of the function given to transform() with the equation:
N is the total number of pages. Document frequency, \(df_w\), is ‘how many pages (docs) does the word occur on?’ That is the x.count(). Can you modify the above to use corpus frequency, which is ‘how many times does the word occur overall in the corpus (i.e. across all pages)?’ You’d want to add everything up.
More Features in the HTRC Extracted Features Dataset
So far we have mainly used token-counting features, accessed through Volume.tokenlist(). The HTRC Extracted Features Dataset provides more features at the volume level. Here are other features that are available to Volume objects. Try them on vol and see what the output is:
vol.line_counts(): How many vertically spaced lines of text, a measure related to the phyical format of the page.vol.sentence_counts(): How many sentences of text: a measure related to the content on a page.vol.empty_line_counts(): How many larger vertical spaces are there on the page between lines of text? In many cases, this can be used as a proxy for paragraph count. This is based on what software was used to OCR so there are inconsistencies: not all scans in the HathiTrust are OCR’d identically.vol.begin_line_chars(),vol.end_line_chars(): The count of different characters along the left-most and right-most sides of a page. This can tell you about what kind of page it is: for example, a table of contents might have a lot of numbers or roman numerals at the end of each line
Earlier, we saw that the number of words on a page gave some indication of whether it was a page of the story or a different kind of page (chapter, front matter, etc). We can see that line count is another contextual ‘hint’:
line_counts = vol.line_counts()
plt.plot(line_counts)
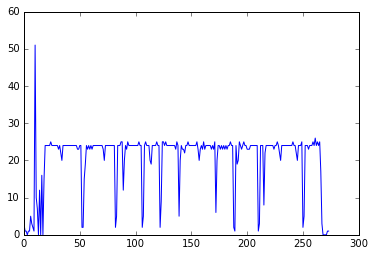
Output graph.
The majority of pages have 20-25 lines, confirmable with a histogram: plt.hist(line_counts). This is likely what a full page of text looks like in this book. A scholar trying to focus on patterns only in the text and comfortable missing a few short pages might choose to filter to just these pages.
Page-Level Features
If you open the raw dataset file for a HTRC EF volume on your computer, you may notice that features are provided for each page. While this lesson has focused on volumes, most of the features that we have seen can be accessed for a single page; e.g. Page.tokenlist() instead of Volume.tokenlist(). The methods to access the features are named the same, with the exception that line_count, empty_line_count, and sentence_count are not pluralized.
Like iterating over FeatureReader.volumes() to get Volume objects, it is possible to iterate across pages with Volume.pages().
Next Steps
Now that you know the basics of the HTRC Feature Reader, you can learn more about the Extracted Features dataset. The Feature Reader home page contains a lesson similar to this one but for more advanced users (that’s you now!), and the code documentation gives exact information about what types of information can be called.
Underwood (2015) has released genre classifications of public-domain texts in the HTRC EF Dataset, comprised of fiction, poetry, and drama. Though many historians will be interested in other corners of the dataset, fiction is a good place to tinker with text mining ideas because of its expressiveness and relative format consistency.
Finally, the repository for the HTRC Feature Reader has advanced tutorial notebooks showing how to use the library further. One such tutorial shows how to derive ‘plot arcs’ for a text, a process popularized by Jockers (2015).
Plot Arc Example.
References
Boris Capitanu, Ted Underwood, Peter Organisciak, Timothy Cole, Maria Janina Sarol, J. Stephen Downie (2016). The HathiTrust Research Center Extracted Feature Dataset (1.0) [Dataset]. HathiTrust Research Center, https://doi.org/10.13012/J8X63JT3.
Chris Forster. “A Walk Through the Metadata: Gender in the HathiTrust Dataset.” Blog. http://cforster.com/2015/09/gender-in-hathitrust-dataset/.
Matthew L. Jockers (Feb 2015). “Revealing Sentiment and Plot Arcs with the Syuzhet Package”. Matthew L. Jockers. Blog. http://www.matthewjockers.net/2015/02/02/syuzhet/.
Peter Organisciak, Loretta Auvil, J. Stephen Downie (2015). “Remembering books: A within-book topic mapping technique.” Digital Humanities 2015. Sydney, Australia.
Stéfan Sinclair & Geoffrey Rockwell (2016). “The Art of Literary Text Analysis.” Github.com. Commit b04bc18. https://github.com/sgsinclair/alta.
William J. Turkel and Adam Crymble (2012). “Counting Word Frequencies with Python”. The Programming Historian. /lessons/counting-frequencies.
Ted Underwood (2014): Understanding Genre in a Collection of a Million Volumes, Interim Report. figshare. https://doi.org/10.6084/m9.figshare.1281251.v1.
Ted Underwood, Boris Capitanu, Peter Organisciak, Sayan Bhattacharyya, Loretta Auvil, Colleen Fallaw, J. Stephen Downie (2015). “Word Frequencies in English-Language Literature, 1700-1922” (0.2) [Dataset]. HathiTrust Research Center. https://doi.org/10.13012/J8JW8BSJ.
Hadley Wickham (2011). “The split-apply-combine strategy for data analysis”. Journal of Statistical Software, 40(1), 1-29.
Appendix: Downloading custom files via rsync
The full HTRC Extracted Features dataset is accessible using rsync, a Unix command line program for syncing files. It is already preinstalled on Linux or Mac OS. Windows users need to use rsync by downloading a program such as Cygwin, which provides a Unix-like command line environment in Windows.
To download all 4 TB comprising the EF dataset, you can use this command (be aware the full transfer will take a very long time):
rsync -rv data.analytics.hathitrust.org::features/ .
This command recurses (the -r flag) through all the folders on the HTRC server, and syncs all the files to a location on your system; in this case the . at the end means “the current folder”. The -v flag means --verbose, which tells rsync to show you more information.
It is possible to sync individual files by specifying a full file path. Files are organized in a PairTree structure, meaning that you can find an exact dataset file from a volume’s HathiTrust id. The HTRC Feature Reader has a tools and instructions for getting the path for a volume. A list of all file paths is available:
rsync -azv data.analytics.hathitrust.org::features/listing/htrc-ef-all-files.txt .
Finally, it is possible to download many files from a list. To try, we’ve put together lists for public-domain fiction, drama, and poetry (Underwood 2014). For example:
rsync -azv --files-from=fiction_paths.txt data.analytics.hathitrust.org::features/ .